-
Python时间序列分析库介绍:statsmodels、tslearn、tssearch、tsfresh
时间序列分析在金融和医疗保健等领域至关重要,在这些领域,理解随时间变化的数据模式至关重要。在本文中,我们将介绍四个主要的Python库——statmodels、tslearn、tssearch和tsfresh——每个库都针对时间序列分析的不同方面进行了定制。这些库为从预测到模式识别的任务提供了强大的工具,使它们成为各种应用程序的宝贵资源。
我们使用来自Kaggle的数据集,通过加速度计数为各种身体活动进行分析。这些活动被分为12个不同的类别,每个类别对应一个特定的身体动作,如站立、坐着、行走,或从事更有活力的活动,如慢跑和骑自行车。每个活动都记录了一分钟的持续时间,提供了丰富的时间序列数据源。
用于此分析的库有:
# statsmodels from statsmodels.tsa.seasonal import seasonal_decompose from statsmodels.tsa.stattools import adfuller from statsmodels.graphics.tsaplots import plot_acf #tslearn from tslearn.barycenters import dtw_barycenter_averaging # tssearch from tssearch import get_distance_dict, time_series_segmentation, time_series_search, plot_search_distance_result # tsfresh from tsfresh import extract_features from tsfresh.feature_selection.relevance import calculate_relevance_table from tsfresh.feature_extraction import EfficientFCParameters from tsfresh.utilities.dataframe_functions import impute- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Statsmodels
从statmodels库中,两个基本函数在理解从x, y和z方向收集的加速度数据的特征方面起着关键作用。
adfuller函数是确定时间序列信号平稳性的有力工具。通过对我们的数据进行Augmented Dickey-Fuller检验,可以确定加速度信号是否表现出平稳的行为,这是许多时间序列分析技术的基本要求。这个测试帮助我们评估数据是否随时间而变化。
def activity_stationary_test(dataframe, sensor, activity): dataframe.reset_index(drop=True) adft = adfuller(dataframe[(dataframe['Activity'] == activity)][sensor], autolag='AIC') output_df = pd.DataFrame({'Values':[adft[0], adft[1], adft[4]['1%']], 'Metric':['Test Statistics', 'p-value', 'critical value (1%)']}) print('Statistics of {} sensor:\n'.format(sensor), output_df) print() if (adft[1] < 0.05) & (adft[0] < adft[4]['1%']): print('The signal is stationary') else: print('The signal is non-stationary')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
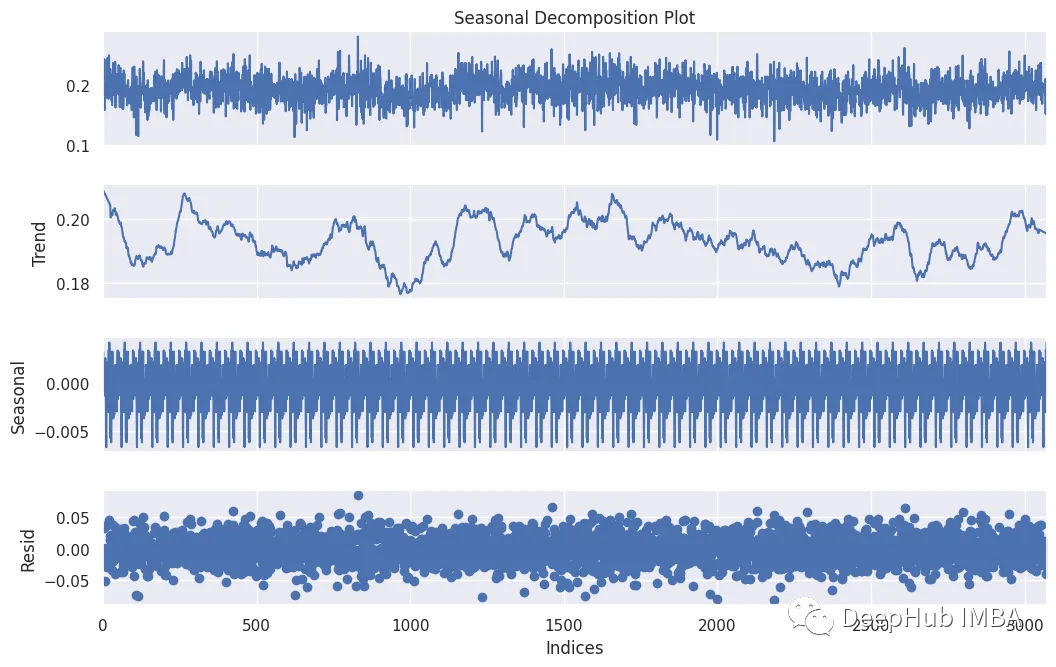
seasonal_decomposition函数提供了对时间序列数据结构的宝贵见解。它将时间序列分解为三个不同的组成部分:趋势、季节性和残差。这种分解使我们能够可视化和理解加速度数据中的潜在模式和异常。
def activity_decomposition(dataframe, sensor, activity): dataframe.reset_index(drop=True) data = dataframe[(dataframe['Activity'] == activity)][sensor] decompose = seasonal_decompose(data, model='additive', extrapolate_trend='freq', period=50) fig = decompose.plot() fig.set_size_inches((12, 7)) fig.axes[0].set_title('Seasonal Decomposition Plot') fig.axes[3].set_xlabel('Indices') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Tslearn
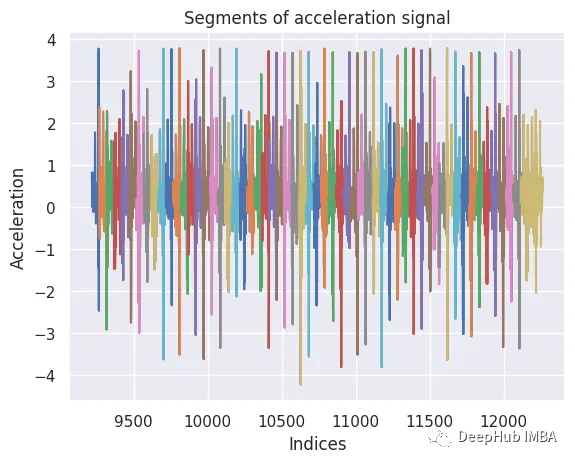
如果使用tslearn库进行时间序列分析。可以采用分割方法,将连续的加速信号分解成特定长度的离散段或窗口(例如,150个数据点)。这些片段提供了行走过程中运动的颗粒视图,并成为进一步分析的基础。重要的是,我们在相邻部分之间使用了50个数据点的重叠,从而可以更全面地覆盖潜在的动态。
template_length = 150 overlap = 50 # Adjust the overlap value as needed segments = [signal[i:i + template_length] for i in range(0, len(signal) - template_length + 1, overlap)]- 1
- 2
- 3
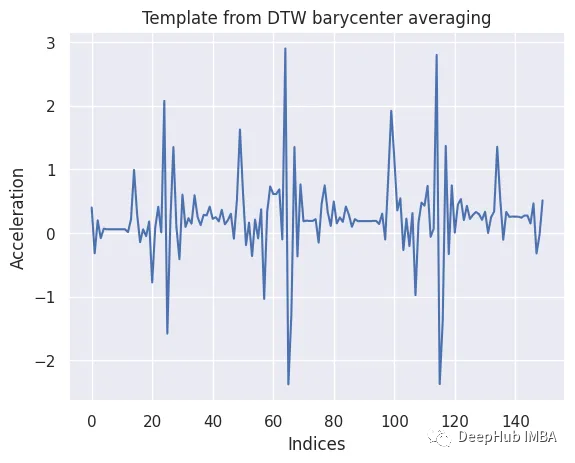
为了从这些片段中获得一个封装行走典型特征的代表性模板,我们使用了dtw_barycenter_averaging函数。该方法采用动态时间规整(Dynamic Time Warping, DTW)对分割的时间序列进行对齐和平均,有效地创建了一个捕捉步行运动中心趋势的模板。
template_signal = dtw_barycenter_averaging(segments) template_signal = template_signal.flatten()- 1
- 2
生成的模板为后续的分类和比较任务提供了有价值的参考,有助于基于x轴加速度的步行活动识别和分析。
Tssearch
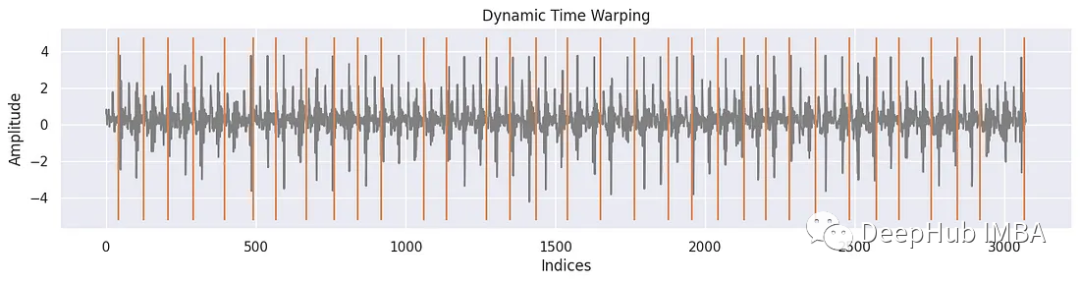
对于tssearch库使用time_series_segmentation函数,通过动态时间规整(DTW)或其他相似性度量来识别输入时间序列中与所提供的模板信号最相似的片段。
该函数的主要目标是定位和提取与模板信号密切匹配的输入时间序列片段。通过将模板信号与输入时间序列进行比较,可以找到这些片段,该函数返回输入时间序列中这些片段开始的位置或索引。
segment_distance = get_distance_dict(["Dynamic Time Warping"]) segment_results = time_series_segmentation(segment_distance, template_signal, signal_np) for k in segment_results: plt.figure(figsize=(15, 3)) plt.plot(signal_np, color='gray') plt.vlines(segment_results[k], np.min(signal_np)-1, np.max(signal_np) + 1, 'C1') plt.xlabel('Indices') plt.ylabel('Amplitude') plt.title(k)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
tssearch库中还有另一个用于发现时间序列数据中的相似性和差异性的方法。首先,我们配置了一个字典dict_distances来指定搜索的距离度量。定义了两种不同的方法。第一个,标记为“elastic”,采用动态时间规整(DTW)作为相似性度量。使用特定的参数定制DTW,例如dtw_type设置为“sub-dtw”,alpha设置为0.5,允许灵活的时间序列对齐和比较。然后是“lockstep”,它利用欧几里得距离以一种更严格的方式来衡量相似性。有了这些距离配置,就可以使用time_series_search函数执行时间序列搜索,将模板信号与目标信号(signal_np)进行比较,并指定前30个匹配项的输出。
dict_distances = { "elastic": { "Dynamic Time Warping": { "function": "dtw", "parameters": {"dtw_type": "sub-dtw", "alpha": 0.5}, } }, "lockstep": { "Euclidean Distance": { "function": "euclidean_distance", "parameters": "", } } } result = time_series_search(dict_distances, template_signal, signal_np, output=("number", 30)) plot_search_distance_result(result, signal_np)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
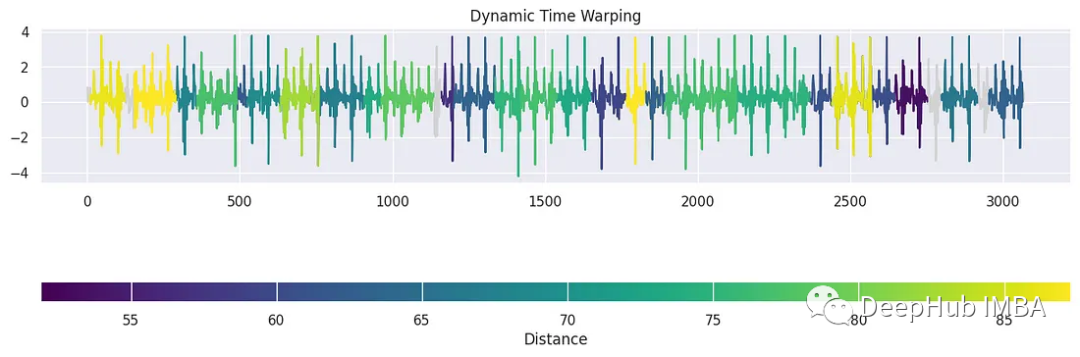
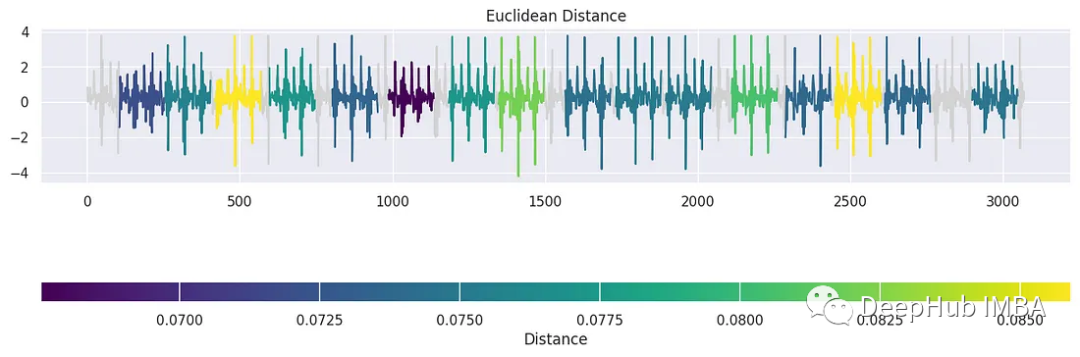
这是一种时间序列聚类的简单的方法,并且可解释性很强。
Tsfresh
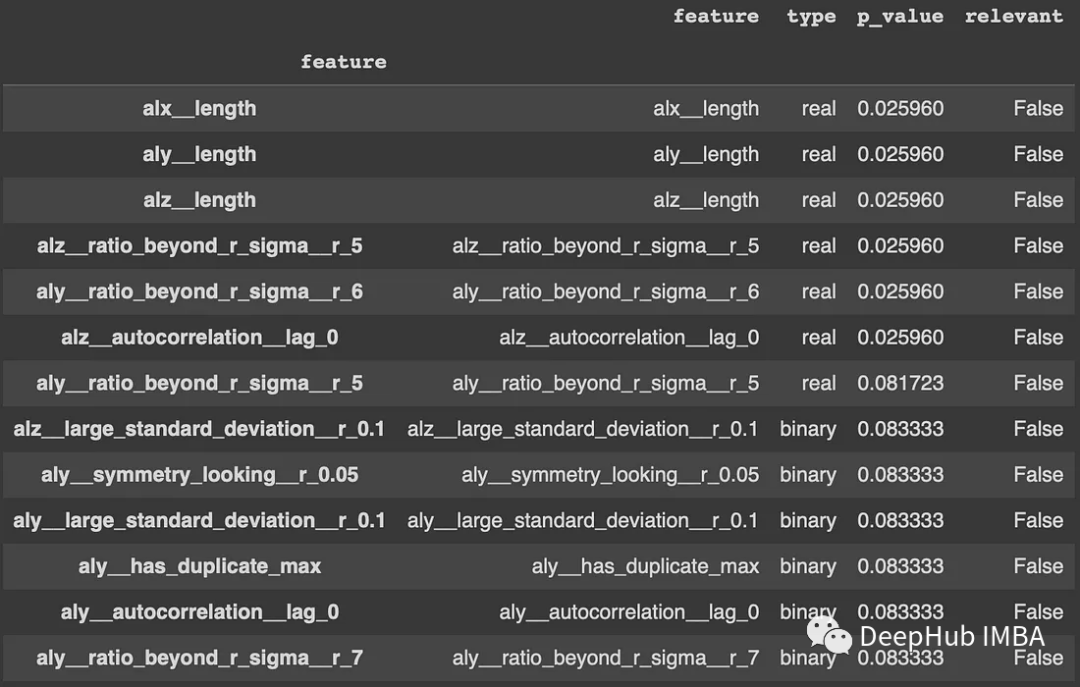
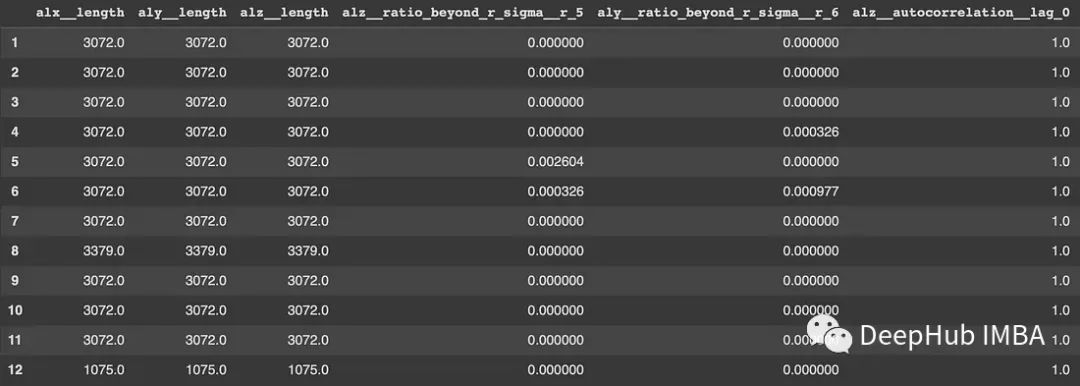
tsfresh库则是一个很好的自动化特征提取过程的工具。effentfcparameters()定义了一组提取设置,它指定了特征提取参数和配置。这些设置可以控制在提取过程中计算哪些特征。然后就可以使用extract_features函数应用进行特征的提取。这里应该将“Activity”列作为标识符列,并提供了特征提取参数。重要的是,该库可以对缺失值(NaN)的特征进行自动删除,结果保存在x_extract中,是从时间序列数据中提取的大量特征集合。Tsfresh简化了通常复杂且耗时的特征工程过程,为时间序列分析提供了宝贵的资源。
extraction_settings = EfficientFCParameters() X_extracted = extract_features(final_df, column_id='Activity', default_fc_parameters=extraction_settings, # we impute = remove all NaN features automatically impute_function=impute, show_warnings=False) X_extracted= pd.DataFrame(X_extracted, index=X_extracted.index, columns=X_extracted.columns) values = list(range(1, 13)) y = pd.Series(values, index=range(1, 13)) relevance_table_clf = calculate_relevance_table(X_extracted, y) relevance_table_clf.sort_values("p_value", inplace=True) relevance_table_clf.head(10)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
top_features = relevance_table_clf["feature"].head(10) x_features = X_extracted[top_features]- 1
- 2
总结
本文向您介绍了时间序列分析的四个基本Python库:statmodels、tslearn、tssearch和tsfresh。时间序列分析是金融和医疗保健等各个领域的重要工具,在这些领域,我们需要了解数据随时间的变化趋势,以便做出明智的决策和预测。
每个库都专注于时间序列分析的不同方面,选择哪个库取决于具体问题。通过结合使用这些库,可以处理各种与时间相关的挑战,从预测财务趋势到对医疗保健中的活动进行分类。当要开始自己的时间序列分析项目时,请记住这些库,结合着使用它们可以帮助你解决很多的实际问题。
https://avoid.overfit.cn/post/ce023e947e0246c09a10a3d71f0181c5
作者:daython3
-
相关阅读:
CSND BUG
QT集成Protobuf
【Visual Leak Detector】QT 中 VLD 输出解析(四)
HTML+CSS大作业:基于HMTL校园学校网页设计题材【我的学校网站】
python判断是否是周末
纬度转地理易语言代码
python LeetCode 刷题记录 67
「重启程序」的正面和反面
“升职加薪”必经路,深入详解Spring,读懂源码So easy
LeetCode Algorithm 剑指 Offer 22. 链表中倒数第k个节点
- 原文地址:https://blog.csdn.net/m0_46510245/article/details/134087703
