-
数组与链表算法-矩阵算法
目录
数组与链表算法-矩阵算法
矩阵相加
矩阵的相加运算较为简单,前提是相加的两个矩阵对应的行数与列数必须相等,而相加后矩阵的行数与列数也是相同的。【
C++代码
- #include
- using namespace std;
- void MaterixAdd(int* arrA, int* arrB, int* arrC, int dimX, int dimY) {
- if (dimX <= 0 || dimY <= 0) {
- cout << "矩阵维数必须大于0" << endl;
- return;
- }
- for (int row = 0; row < dimX; row++) {
- for (int col = 0; col < dimY; col++) {
- arrC[row * dimX + col] = arrA[row * dimX + col] + arrB[row * dimX + col];
- }
- }
- }
- void PrintArr(int* arr, int dimX, int dimY) {
- for (int i = 0; i < dimX; i++) {
- for (int j = 0; j < dimY; j++) {
- cout << arr[i * dimX + j] << "\t";
- }
- cout << endl;
- }
- }
- int main() {
- const int Row = 3;
- const int Col = 3;
- int A[Row][Col] = { {1,3,5},
- {7,9,11},
- {13,15,17} };
- int B[Row][Col] = { {9,8,7},
- {6,5,4},
- {3,2,1} };
- int C[Row][Col] = { 0 };
- cout << "矩阵A的各个元素:" << endl;
- PrintArr(&A[0][0], Row, Col);
- cout << "矩阵B的各个元素:" << endl;
- PrintArr(&B[0][0], Row, Col);
- MaterixAdd(&A[0][0], &B[0][0], &C[0][0], Row, Col);
- cout << "矩阵C的各个元素:" << endl;
- PrintArr(&C[0][0], Row, Col);
- return 0;
- }
输出结果

矩阵相乘
两个矩阵A和B的相乘受到某些条件的限制。首先,必须符合A为一个
 的矩阵,B为一个
的矩阵,B为一个 的矩阵,
的矩阵, 之后的结果为一个
之后的结果为一个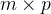 的矩阵C。
的矩阵C。C++代码
- #include
- using namespace std;
- void MaterixMultiply(int* arrA, int* arrB, int* arrC, int dimX, int dimY) {
- if (dimX <= 0 || dimY <= 0) {
- cout << "矩阵维数必须大于0" << endl;
- return;
- }
- for (int i = 0; i < dimX; i++) {
- for (int j = 0; j < dimX; j++) {
- int Temp = 0;
- for(int k = 0;k< dimY;k++){
- arrC[i * dimX + j] += (arrA[i * dimY + k] * arrB[k * dimX + j]);
- }
- }
- }
- }
- void PrintArr(int* arr, int dimX, int dimY) {
- for (int i = 0; i < dimX; i++) {
- for (int j = 0; j < dimY; j++) {
- cout << arr[i * dimY + j] << "\t";
- }
- cout << endl;
- }
- }
- int main() {
- const int Row = 2;
- const int Col = 3;
- int A[Row][Col] = { {1,2,3},
- {4,5,6} };
- int B[Col][Row] = { {3,4},
- {6,1},
- {2,7} };
- int C[Row][Row] = { 0 };
- cout << "矩阵A的各个元素:" << endl;
- PrintArr(&A[0][0], Row, Col);
- cout << "矩阵B的各个元素:" << endl;
- PrintArr(&B[0][0], Col, Row);
- MaterixMultiply(&A[0][0], &B[0][0], &C[0][0], Row, Col);
- cout << "矩阵C的各个元素:" << endl;
- PrintArr(&C[0][0], Row, Row);
- return 0;
- }
输出结果

转置矩阵
转置矩阵(
 )就是把原矩阵的行坐标元素与列坐标元素相互调换。假设为
)就是把原矩阵的行坐标元素与列坐标元素相互调换。假设为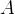 的转置矩阵,则有
的转置矩阵,则有![A^{t}[j,i] = A[i,j]](https://1000bd.com/contentImg/2024/03/26/d3ecf2e3f47acae3.png) 。
。C++代码
- #include
- using namespace std;
- void MaterixTranspose(int* arr, int dimX, int dimY) {
- for (int i = 0; i < dimX; i++) {
- for (int j = 0; j <= i; j++) {
- int Temp = arr[i * dimY + j];
- arr[i * dimY + j] = arr[j * dimY + i];
- arr[j * dimY + i] = Temp;
- }
- }
- }
- void PrintArr(int* arr, int dimX, int dimY) {
- for (int i = 0; i < dimX; i++) {
- for (int j = 0; j < dimY; j++)
- cout << arr[i * dimY + j] << "\t";
- cout << endl;
- }
- }
- int main() {
- const int Row = 3;
- const int Col = 3;
- int arr[Row][Col] = { {1,2,3},
- {4,5,6},
- {7,8,9} };
- cout << "原始矩阵:" << endl;
- PrintArr(&arr[0][0], Row, Col);
- MaterixTranspose(&arr[0][0], Row, Col);
- cout << "转置矩阵:" << endl;
- PrintArr(&arr[0][0], Row, Col);
- return 0;
- }
输出结果

稀疏矩阵
稀疏矩阵(Sparse Matrix)就是指一个矩阵中的大部分元素为0。对于稀疏矩阵而言,因为矩阵中的许多元素都是0,所以实际存储的数据项很少,如果在计算机中使用传统的二维数组方式来存储稀疏矩阵,就十分浪费计算机的内存空间。
提高内存空间利用率的方法是使用三项式(3-Tuple)的数据结构。我们把每一个非零项用(i, j, item-value)的形式来表示,假如一个稀疏矩阵有n个非零项,那么可以使用一个A(0:n, 1:3)的二维数组来存储这些非零项。
其中,A(0, 1)存储这个稀疏矩阵的行数,A(0,2)存储这个稀疏矩阵的列数,而A(0,3)则存储这个稀疏矩阵非零项的总数。另外,每一个非零项以(i, j, item-value)来表示。其中i为此矩阵非零项所在的行数,j为此矩阵非零项所在的列数,item-value则为此矩阵非零项的值。
A(0, 1):表示此矩阵的行数。
A(0, 2):表示此矩阵的列数。
A(0, 3):表示此矩阵非零项的总数。
这种利用3项式数据结构来压缩稀疏矩阵的方式可以减少对内存的浪费。
C++代码
- #include
- using namespace std;
- void MaterixSparse(int* arrSparse, int* arrCompress, int dimX, int dimY) {
- int temp = 1;
- for (int i = 0; i < dimX; i++) {
- for (int j = 0; j < dimY; j++) {
- if (arrSparse[i * dimY + j] != 0) {
- arrCompress[temp * 3 + 0] = i;
- arrCompress[temp * 3 + 1] = j;
- arrCompress[temp * 3 + 2] = arrSparse[i * dimY + j];
- temp++;
- }
- }
- }
- }
- void PrintArr(int* arr, int dimX, int dimY) {
- for (int i = 0; i < dimX; i++) {
- for (int j = 0; j < dimY; j++)
- cout << arr[i * dimY + j] << "\t";
- cout << endl;
- }
- }
- int main() {
- const int Row = 8;
- const int Col = 9;
- const int NotZero = 8;
- int Sparse[Row][Col] = { {0,0,0,0,0,0,0,0,0},
- {0,0,0,0,0,0,0,0,0},
- {0,0,0,0,7,0,0,0,0},
- {0,0,0,0,0,0,0,0,5},
- {0,0,0,0,0,0,0,0,0},
- {0,0,0,0,0,0,0,0,0},
- {0,0,6,1,8,0,0,0,2},
- {4,0,0,0,0,0,3,0,0} };
- int Compress[NotZero + 1][3]{ 0 };
- Compress[0][0] = Row;
- Compress[0][1] = Col;
- Compress[0][2] = NotZero;
- cout << "稀疏矩阵:" << endl;
- PrintArr(&Sparse[0][0], Row, Col);
- MaterixSparse(&Sparse[0][0], &Compress[0][0], Row, Col);
- cout << "压缩矩阵:" << endl;
- PrintArr(&Compress[0][0], NotZero + 1, 3);
- return 0;
- }
输出结果

-
相关阅读:
前端面试题50(有哪些常见的前端安全措施可以防止CSRF攻击?)
【GitHub】小技巧
基于JAVA清颜广告股份有限公司网站演示录像计算机毕业设计源码+数据库+lw文档+系统+部署
顶级网络安全预测:近三分之一的国家将在三年内规范勒索软件响应
【css案例】
ubuntu 18.04安装自己ko驱动&& 修改secure boot
HDD-FAT32 ZIP-FAT32 HDD-FAT16 ZIP-FAT16 HDD-NTFS
Flink之窗口指派API模板
k8s~动态生成pvc和pv
阶乘算法优化
- 原文地址:https://blog.csdn.net/qq_40660998/article/details/134059399
