-
工作小计-GPU硬编以及依赖库 nvcuvid&nvidia-encode
工作小计-GPU编码以及依赖库
已经是第三篇关于编解码的记录了。项目中用到GPU编码很久了,因为yuv太大,所以编码显得很重要。这次遇到的问题是环境的搭建问题。需要把开发机上的环境放到docker中,以保证docker中同样可以进行GPU的编码。
1 定位问题
docker是算法部门提供的,天然带了cuda,gpu驱动等环境。但是代码调用解码器时,未找到对应的硬解码器。
定位问题,先确定是否真的不支持编码器。查看库是否支持GPU
strings libavcodec.so | grep -i cuda- 1

看到很多cuda输出,最重要的还是这个编译选项,可以看到是开启了对应的cuda,nvenc,cuvid都有的--prefix=/opt/ffmpeg --enable-shared --enable-ffplay --enable-cuda --enable-cuvid --enable-nvenc --enable-nonfree --enable-libnpp --enable-gpl --extra-cflags='-I/usr/local/cuda/include /usr/local/cuda-11.1/targets/x86_64-linux/include' --extra-ldflags='-L/usr/local/cuda/lib64 -L/usr/local/cuda-11.1/targets/x86_64-linux/lib' --disable-x86asm --extra-cflags=-fPIC --extra-cxxflags=-fPIC --enable-libmfx --enable-nonfree --enable-encoder=h264_qsv --enable-decoder=h264_qsv --enable-encoder=hevc_qsv --enable-decoder=hevc_qsv --prefix=/opt/ffmpeg --libdir=/opt/ffmpeg/lib --extra-cflags=-I/opt/intel/mediasdk/include --extra-ldflags=-L/opt/intel/mediasdk/lib64- 1
查看运行时是否支持硬件解码
手头有现成h265文件,
# 得到yuv文件 ffmpeg -i input.h265 -c:v rawvideo -pix_fmt yuv420p output.yuv # 得到MP4文件 ffmpeg -i input.h265 -c:v libx264 -crf 23 -c:a aac -strict experimental output.mp4 # 对yuv进行h264/hevc(h265) 硬件编码 ffmpeg -f rawvideo -pix_fmt yuv420p -s 3840x2160 -r 30 -i output.yuv -c:v hevc_nvenc output.mp4 ffmpeg -f rawvideo -pix_fmt yuv420p -s 3840x2160 -r 30 -i output.yuv -c:v h264_nvenc output.mp4- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
果然硬编码报错了
可见h264和h265的硬编都报错了[h264_nvenc @ 0x258a880] Cannot load libnvidia-encode.so.1 [hevc_nvenc @ 0x258a880] The minimum required Nvidia driver for nvenc is (unknown) or newer- 1
- 2
- 3
2 解决问题
直接搜宿主机的环境

i386-linux-gnu 是32位环境的,直接忽略。去对应的文件夹找nvidia对应的库
和docker中的对比下
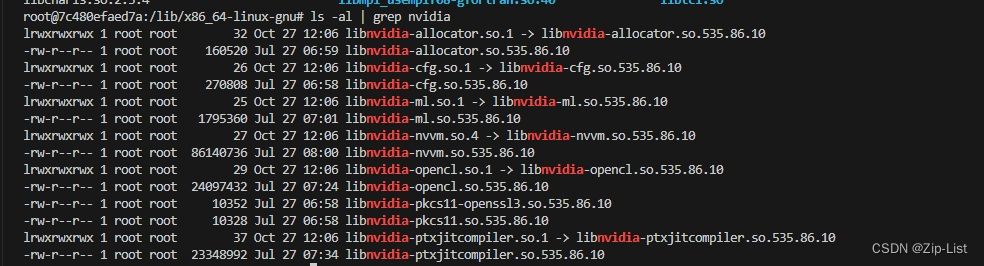
果然查了很多,因为docker中的是深度学习的环境,和我们的硬件编码库肯定会有偏拷贝过去,仍然报错。最终定位到cuvid的问题。坑爹的是,ffmpeg缺少硬件编码缺少cuvid的时候,同样会报错缺少 libnvidia-encode.so的问题

可以看到nvenc和cuvid这两个库分别对应硬件的编解码,之前的项目用硬解比较多,而这边则是硬编比较多libnvcuvid.so是NVIDIA Video Codec SDK中的一个库文件,它提供了用于解码和处理视频的功能。它允许应用程序使用NVIDIA GPU来加速视频解码,从而提高视频处理性能。
libnvidia-encode.so是NVIDIA Video Codec SDK中的另一个库文件,它提供了用于编码和处理视频的功能。它允许应用程序使用NVIDIA GPU来加速视频编码,从而提高视频处理性能。这两个库文件都是NVIDIA提供的用于视频处理的工具,可以在支持NVIDIA GPU的系统上使用。它们为开发人员提供了使用GPU进行视频解码和编码的接口和功能,以实现更高效的视频处理和加速。
至此,问题解决。3 docker相关
额外记录一些docker相关的理解。
docker想要调用gpu和必定要和宿主机中的gpu进行通信(肤浅的理解可以是各自安装了 nvidia-container-toolkit),完成一次远程调用/中转调用。这个调用之前是由nvidia-docker完成的。高版本的docker集成了nvidia-docker,所以只要如入–gpu 参数就好。只要在容器中的nvidia-smi正常之后,就基本差不多了,因为是进行了一次交互。但是驱动,指的是调用gpu的指令,*.so这些,还是要在docker中安装的,不然即没有办法和宿主机通讯,也没有办法被上层应用调用。nvidia-container-cli --version # 查看是否安装了对应的版本- 1
在容器中使用 GPU,通常需要在宿主机和容器中都安装 NVIDIA Container Toolkit。在宿主机中安装 NVIDIA Container Toolkit 用于管理宿主机上的 GPU 资源,而在容器中安装 NVIDIA Container Toolkit 则用于在容器内访问这些 GPU 资源。
宿主机
https://github.com/NVIDIA/k8s-device-plugin#preparing-your-gpu-nodesdistribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-docker2- 1
- 2
- 3
- 4
容器
# 基于一个带有 NVIDIA 驱动的基础镜像构建 FROM nvidia/cuda:11.0-base # 安装 NVIDIA Container Toolkit 相关的软件包 RUN apt-get update && apt-get install -y nvidia-container-toolkit # 设置 NVIDIA 运行时环境变量 ENV NVIDIA_VISIBLE_DEVICES all ENV NVIDIA_DRIVER_CAPABILITIES compute,utility # 验证 NVIDIA GPU 配置是否正确 RUN nvidia-smi # 运行你的应用程序或服务 CMD ["/your/app/command"]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4 gpu驱动相关

上云之后仍然有问题,这个报错是因为so是向下兼容驱动的,项目中最终涉及到了本地升级GPU驱动,因为gpu的云端环境的驱动实在太高了。

升级GPU驱动,简单理解。升级的就是cuda*.so和libnvidia*.so,(还有GPU的底软相关的*.ko文件)。直观上看就是nvidia-smi的驱动版本变高了
对应的官网指令,以及做成了指令。
https://developer.nvidia.com/cuda-downloads?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=22.04
卸载驱动则可以使用 apt-get purge这种方法。升级完毕后。sudo updatedb //先更新数据库的缓存再查询 locate libnvidia-encode.so- 1
- 2
也可以看到从86升级到了98

这些库的具体作用如下,跟随着会一起升级的。libnvidia-encode.so: 与 NVENC 相关,提供硬件加速的视频编码功能。 libnvidia-glcore.so: 与 OpenGL 相关,提供 3D 渲染功能。 libnvidia-eglcore.so: 与 EGL 相关,提供渲染窗口和图像的接口。 libnvidia-glsi.so: 与 OpenGL 的场景图相关。 libnvidia-nvvm.so: 与 NVIDIA 的虚拟机相关,用于 CUDA。 libnvidia-ml.so: 提供对 GPU 硬件状态的查询功能,如温度、电压等。 libnvidia-cfg.so: 提供 GPU 配置相关的功能。 libnvidia-opticalflow.so: 提供光流计算功能,常用于视频分析和计算机视觉。 libnvidia-rtcore.so: 与光线追踪相关。 libnvidia-gtk2/3.so: 提供与 GTK2 和 GTK3 界面工具包的集成。 libnvidia-container.so: 与 NVIDIA Container Toolkit 相关,支持在 Docker 容器中使用 GPU。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
另外我们可以知道,只要docker中有了对应的nvso库之后,即使宿主机没有对应的so库,只要有gpu的驱动就可以成功运行程序,因为so是和驱动交互的,而nv-docker就是让容器中的so和宿主机的gpu驱动交互。
libcuda.so和libnvida.so
在 NVIDIA 的软件堆栈中,libcuda.soXXX(也称为 CUDA 驱动 API)和libnvidia-encode.soXXX(NVENC,用于硬件加速视频编码)都是较底层的库。比较它们的“层级”,可以这样描述:
libcuda.soXXX (CUDA 驱动 API): 这是 CUDA 架构的基础。它允许应用程序与 NVIDIA GPU进行直接交互。基于 CUDA 的应用程序和库,如 cuDNN、cuBLAS 等,都依赖于这个库来与 GPU 交互。
libnvidia-encode.soXXX (NVENC): 这是专门用于视频编码的库。它提供了硬件加速的视频编码功能,并直接与NVIDIA GPU 的视频编码硬件进行交互。
二者对比
libcuda 更为“基础”或“底层”,因为它是整个 CUDA 架构的基石。而 libnvidia-encode则是针对特定功能(视频编码)的专门库。
libnvidia-encode.so 是 NVIDIA 的编码(NVENC)库,它提供了硬件加速的视频编码功能。libcuda.so 是CUDA 运行时的主要库,它允许应用程序访问 NVIDIA GPU 的并行计算能力。
虽然这两个库都与 NVIDIA GPU 的功能有关,但它们服务于不同的目的。libnvidia-encode.so 主要用于视频编码,而 libcuda.so 用于并行计算。
但是,从实现的角度来看,libnvidia-encode.so 可能在内部使用到了 libcuda.so 或其他与 GPU驱动相关的库,这样可以更直接地与 GPU 交互。具体到 libnvidia-encode.so 是否直接调用 libcuda.so,这要看NVIDIA 的内部实现,通常这些细节是不公开的。
-
相关阅读:
三维模型3DTile格式轻量化压缩在移动智能终端应用方面的重要性分析
会话边界控制器(SBC)
机器学习分类方法
Java项目:SSH在线水果商城平台含管理系统
基于MQTT协议的远距离数据采集与WEB服务系统设计稿
PDF压缩文件怎么压缩?两分钟让你学会三种方法
(文献随笔)肿瘤浸润的活化B细胞抑制结直肠癌的肝转移(Cell Report, 2022年8月30日)
测试人经验谈:需求不明确也能写出测试用例
二叉搜索树
Docker常见命令
- 原文地址:https://blog.csdn.net/qq_41565920/article/details/134083941