-
风格迁移常用代码
损失
nn.MSELoss均方损失函数

LPIPS感知损失
学习感知图像块相似度(Learned Perceptual Image Patch Similarity, LPIPS)也称为“感知损失”(perceptual loss),用于度量两张图像之间的差别,来源于论文《The Unreasonable Effectiveness of Deep Features as a Perceptual Metric》。
论文地址:
https://arxiv.org/pdf/1801.03924.pdf
代码地址:
pytorch:https://github.com/richzhang/PerceptualSimilarity
计算相似度需逐层计算网络输出的对应channel的Cos Distance,然后对得到的distance进行平均(所有层,空间维度),LPIPS主要是把两个Cos Distance作为网络的输入,然后用Cross Entropy Loss训练网络学习2AFC。

计算x与x0 之间的距离d0:给定不同的BaseNet F,首先计算深度嵌入,规格化通道维度中的激活,用向量w缩放每个通道,取L2距离,然后对空间维度和所有层次求平均。

从
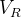 层提取特征堆并在通道维度中进行单元标准化。通过
层提取特征堆并在通道维度中进行单元标准化。通过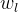 缩放激活通道维并计算
缩放激活通道维并计算  距离
距离,在空间上取平均,在层上求和。
- # pytorch 求LPIPS
- import torch
- import lpips
- import os
- use_gpu = False # Whether to use GPU
- spatial = True # 返回感知距离的空间图
- # 线性校准模型 Linearly calibrated models (LPIPS)
- loss_fn = lpips.LPIPS(net='alex', spatial=spatial) # Can also set net = 'squeeze' or 'vgg'
- # loss_fn = lpips.LPIPS(net='alex', spatial=spatial, lpips=False) # Can also set net = 'squeeze' or 'vgg'
- if (use_gpu):
- loss_fn.cuda()
- # 使用伪张量的实例 Example usage with dummy tensors
- rood_path = r'D:\Project\results\faces'
- img0_path_list = []
- img1_path_list = []
- ## path in net is already exist
- '''
- for root, _, fnames in sorted(os.walk(rood_path, followlinks=True)):
- for fname in fnames:
- path = os.path.join(root, fname)
- if '_generated' in fname:
- im0_path_list.append(path)
- elif '_real' in fname:
- im1_path_list.append(path)
- '''
- dist_ = []
- for i in range(len(img0_path_list)):
- dummy_img0 = lpips.im2tensor(lpips.load_image(img0_path_list[i]))
- dummy_img1 = lpips.im2tensor(lpips.load_image(img1_path_list[i]))
- if (use_gpu):
- dummy_img0 = dummy_img0.cuda()
- dummy_img1 = dummy_img1.cuda()
- dist = loss_fn.forward(dummy_img0, dummy_img1)
- dist_.append(dist.mean().item())
- print('Avarage Distances: %.3f' % (sum(dist_) / len(img0_path_list)))
GAN
- netG = StyleBankNet(len(dataset_list))
- netD = Discriminator()
- loss_network = LossNetwork()
- bce_loss = nn.BCELoss()
- use_gpu = torch.cuda.is_available()
- if use_gpu:
- netG = netG.cuda()
- netD = netD.cuda()
- loss_network = loss_network.cuda()
- LR = 1e-2
- optimizerG = Adam(netG.parameters(), LR)
- optimizerD = Adam(netD.parameters(), LR)
- scheduler = StepLR(optimizerG, step_size=30, gamma=0.2)
- netG.train()
- netD.train()
- print('networks done')
- # batch_id--批次索引 (style_id, content_image, stylized_image)--风格索引 内容图 风格图
- for batch_id, (style_id, content_image, stylized_image) in enumerate(dataloader):
- optimizerG.zero_grad()
- optimizerD.zero_grad()
- batch_size = len(style_id)
- count += batch_size # 总训练的图片数量
- epoch_count += batch_size # 本轮次训练的图片数量
- # 创建了一个名为label的张量(tensor),类型为torch.FloatTensor,它的大小与batch_size相同。
- # fill_()函数用指定的值填充整个张量。在这里,fill_(1)表示将label张量的所有元素都设置为1
- label = torch.FloatTensor(batch_size).fill_(1)
- # Variable函数的作用是将输入的张量(例如图像)封装成一个可以进行自动求导操作的变量
- content_image = Variable(content_image)
- stylized_image = Variable(stylized_image)
- if use_gpu:
- content_image = content_image.cuda()
- stylized_image = stylized_image.cuda()
- label = label.cuda()
- labelv = Variable(label)
- output_image = netG(content_image, style_id)
- output_features = loss_network(output_image)
- #############################################################
- # (1) 更新鉴别器网络: 最大化 log(D(x)) + log(1 - D(G(z)))
- # Update D network: maximize log(D(x)) + log(1 - D(G(z)))
- # the Discriminator training part is referenced from
- # https://github.com/pytorch/examples/blob/master/dcgan/main.py
- # at 2018/3/6
- #############################################################
- # train with real
- p_real = netD(stylized_image)
- # 使用二值交叉熵损失函数 bce_loss 比较输出 p_real 和标签 labelv,计算真实图像的判别器损失 errD_real
- # p_real 是一个预测值,表示模型对真实数据的预测结果。labelv 是真实标签,其中包含了对应于每个预测值的期望输出
- errD_real = bce_loss(p_real, labelv)
- errD_real.backward()
- D_x = D_x + p_real.data.mean()
- # train with fake
- labelv = Variable(label.fill_(0))
- p_fake = netD(output_image.detach())
- errD_fake = bce_loss(p_fake, labelv)
- errD_fake.backward()
- D_G_z1 = D_G_z1 + p_fake.data.mean()
- Loss_D = Loss_D + errD_fake.data.mean() + errD_real.data.mean()
- optimizerD.step()
nn.BCELoss()
`bce_loss(p_real, labelv)` 是二分类任务中的二元交叉熵损失函数。它的原理如下:
首先,`p_real` 是一个预测值,表示模型对真实数据的预测结果。`labelv` 是真实标签,其中包含了对应于每个预测值的期望输出。
二元交叉熵损失函数的计算公式如下:
```
loss = -[labelv * log(p_real) + (1 - labelv) * log(1 - p_real)]
```其中 `log` 表示自然对数。这个损失函数通过比较预测值 `p_real` 和真实标签 `labelv` 之间的差异来度量模型的预测效果。
当 `labelv` 为 1 时,损失函数的第一项起作用,即 `loss = -log(p_real)`。这时,我们希望模型能够将真实数据正确分类为正样本,即 `p_real` 趋近于 1。如果 `p_real` 越接近 0(即模型错误地将真实数据分类为负样本),那么损失函数的值就会越大,反之亦然。
当 `labelv` 为 0 时,损失函数的第二项起作用,即 `loss = -log(1 - p_real)`。这时,我们希望模型能够将真实数据正确分类为负样本,即 `p_real` 趋近于 0。如果 `p_real` 越接近 1(即模型错误地将真实数据分类为正样本),那么损失函数的值就会越大,反之亦然。
通过最小化二元交叉熵损失函数,我们可以使模型学习到正确分类样本的权重和偏差,从而提高模型的准确性和泛化能力。
-
相关阅读:
一例jse蠕虫的分析
韩顺平java课程527 -531速记笔记
手写一个Bus总线
使用 WordPress快速个人建站指南
ABAP WBS 用户状态的取值方法
2.1C#新语法
代码随想录第三十天|无重叠区间| 划分字母区间| 合并区间
QSS样式表的使用
【力扣白嫖日记】SQL
移动开发技术
- 原文地址:https://blog.csdn.net/qq_44527508/article/details/134074075
