-
nlp与知识图谱代码解读_词嵌入
词嵌入
简单原理
可以使用一些比喻和生活中的例子:
老师: 你们还记得玩乐高积木的时候,每个积木块代表了一个特定的事物或形状吗?现在,想象一下,每个词都像是一个乐高积木。我们要做的是为每个积木找到一个特殊的地方,这样它们就可以和其他积木在某种方式上连接起来。
词嵌入就像是为每个词找一个特定的地方或位置,但这个“地方”不是在房间里,而是在一个叫做“嵌入空间”的地方。
学生A: “嵌入空间”是什么?
老师: 好问题!嵌入空间就像一个大大的游乐场。每个词都有自己的一个小小的位置,这个位置由一些数字决定。比如,“猫”可能在游乐场的旋转木马旁边,而“狗”可能在滑梯旁边。这些位置是用数字来表示的,所以“猫”可能是[0.5, 2.3],而“狗”可能是[0.6, 2.1]。
这些位置不是随机选择的。词之间的关系决定了它们在游乐场中的位置。例如,因为“猫”和“狗”都是宠物,所以它们的位置会很接近。但“猫”和“汽车”可能就相距很远,因为它们是不同类别的事物。
学生B: 那我们是怎么知道每个词的位置的呢?
老师: 很好的问题!我们使用计算机和特殊的算法。我们把很多句子和文本输入到计算机中,计算机会查看哪些词经常一起出现,然后根据这些信息决定它们在游乐场中的位置。
比如,“奶”和“饼干”在很多句子中都一起出现,所以计算机会认为它们应该在游乐场的同一个地方或附近。
学生C: 那为什么我们要做这个呢?
老师: 好问题!当我们给计算机很多文本时,我们希望它能理解这些文本的意思。但计算机不懂“猫”或“狗”的真正意思,它只懂数字。所以,我们把每个词转换成数字,这样计算机就可以理解它们了。通过这种方式,计算机可以帮助我们回答问题、写文章或者做其他有趣的事情!
既然计算机不懂什么是“猫”和“狗”,那计算机如何将“猫”和“狗”的数字设置的近一些呢?
很好的问题!确实,计算机本身并不知道“猫”和“狗”的具体含义,但它可以通过分析大量的文本数据来识别这两个词语之间的关联。下面我会用一个简单的例子来解释这个过程。
老师: 让我们想象一个游戏:你在读很多的故事书,但是每次你只看两个连在一起的词。比如:“猫在”, “在睡觉”, “狗在”, “在追”。你可能会注意到,“猫”和“狗”经常都跟“在”这个词后面。
现在,假设我们有一个大篮子,里面放着很多词的卡片。开始时,这些卡片都随机地放在篮子里。每次你读到两个连在一起的词,你就把这两张卡片放得更近一些。
经过很多次这样的操作后,你会发现那些经常在故事里连在一起的词卡片会聚集在一起。所以,“猫”和“狗”可能会因为它们经常与相似的词语连在一起,而被放得很近。
计算机在进行词嵌入的时候,也是做了类似的事情。它看了大量的句子,每次只注意那些靠近的词。然后,它会调整每个词的数字位置,使得经常在一起出现的词更加接近。
通过这种方式,即使计算机不知道“猫”和“狗”的真实含义,它也能知道这两个词在很多情境中是相似或有关的,所以应该放得近一些。
希望这个解释能帮助你理解计算机是如何决定词嵌入中词的位置的!
代码案例+解读
import numpy as np from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Embedding # 词嵌入 model = Sequential() model.add(Embedding(input_dim=7, output_dim=3, )) # 输入、输出 model.compile() # 全部参数使用默认 x = np.array([[0, 1, 0, 1, 1, 0, 0], [1, 1, 1, 1, 1, 1, 1]]) print('input shape data: \n', x, x.shape) result = model.predict(x) print('Embedding:', result, 'shape:', result.shape)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这段代码使用TensorFlow的Keras API来创建一个简单的词嵌入(Embedding)模型。我们来逐行解读代码内容:
-
import numpy as np
导入NumPy库,并使用别名np引用它。NumPy是一个常用的Python科学计算库,用于进行数值计算。 -
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding
这两行从TensorFlow库中导入必要的模块。Sequential模型是Keras中一个线性堆叠的层次结构,而Embedding是Keras中用于词嵌入的层。 -
model = Sequential()
创建一个Sequential模型的实例。 -
model.add(Embedding(input_dim=7, output_dim=3, ))
向模型中添加一个Embedding层。其中,input_dim=7表示输入数据的词汇表大小为7,也即我们有7个不同的单词/标记。output_dim=3表示每个单词要被嵌入到3维的向量空间中。 -
model.compile()
编译模型。这里没有为compile函数提供任何参数,所以它使用默认设置。由于这只是一个简单的演示,并没有进行真实的训练,所以这一步的设置不是很关键。 -
x = np.array([[0, 1, 0, 1, 1, 0, 0], [1, 1, 1, 1, 1, 1, 1]])
使用NumPy创建一个形状为(2, 7)的数组。可以看作是两个句子,每个句子由7个单词/标记组成。这里的数字代表词汇表中的索引。 -
print('input shape data: \n', x, x.shape)
打印输入数据和它的形状。 -
result = model.predict(x)
使用Embedding模型对输入数据x进行预测。实际上,这一步将输入数据的每个单词索引转换为对应的嵌入向量。 -
print('Embedding:', result, 'shape:', result.shape)
打印嵌入的结果和它的形状。
总结:此代码创建了一个简单的词嵌入模型,然后用这个模型将两个句子中的单词索引转换为对应的嵌入向量。这个模型没有经过训练,所以得到的嵌入向量是随机的。
专业原理介绍
词嵌入简介:
词嵌入(Word Embedding)是NLP和深度学习中的一个关键技术,它的核心思想是将自然语言中的单词或短语转换成固定大小的向量。这些向量可以捕获单词之间的语义关系、相似性和其他多种语言属性。
为什么需要词嵌入?
计算机本身不能理解文本或单词,它只能理解数字。因此,我们需要一种方法将单词转化为数值或向量形式。初学者可能会首先想到“独热编码”,但这种方法在大词汇表中是不切实际的,因为它产生的向量非常稀疏,且不能捕获单词间的关系。
词嵌入提供了一种更紧凑、高效的表示方法,其中相似的单词在向量空间中彼此靠近。
如何获得词嵌入?
-
预训练模型:例如Word2Vec、GloVe和FastText,这些模型在大量文本数据上训练,可以为每个单词提供预训练的向量。你可以直接使用这些预训练向量或在特定任务上进行进一步的微调。
-
自行训练:例如,在一个深度学习模型(如RNN、CNN)中使用嵌入层,这个层在模型训练过程中学习合适的单词向量。
Word2Vec简介:
Word2Vec是最受欢迎的词嵌入方法之一。它的核心思想是“一个单词的含义可以由它周围的单词定义”。Word2Vec有两种主要的训练方法:
- CBOW(Continuous Bag of Words):给定上下文,预测当前单词。
- Skip-Gram:给定当前单词,预测它的上下文。
词嵌入的优点:
- 捕获语义信息:例如,“king” - “man” + “woman” 接近 “queen”。
- 降维:将高维的独热向量转化为低维的密集向量。
- 可转移:预训练的词向量可以用于多种不同的任务。
总结:
词嵌入为单词提供了一种密集、低维的向量表示形式,这些向量捕获了单词的语义属性和关系。使用词嵌入,我们可以在深度学习模型中更高效地处理文本数据。
场景
当然可以!让我们使用一个简单的例子来进一步理解词嵌入。
场景: 设想你有以下四个句子:
- The cat sat on the mat.
- The dog sat on the rug.
- Cats and dogs are pets.
- Pets make great companions.
如果我们从这些句子中提取出所有的唯一单词,我们得到一个词汇表:[The, cat, sat, on, the, mat, dog, rug, cats, dogs, are, pets, make, great, companions]。我们忽略大小写和标点符号。
独热编码:
让我们先看独热编码。对于词汇表中的每一个单词,独热编码将会为其分配一个向量,其中只有一个元素是1,其余都是0。
例如:
- cat: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
- dog: [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
但是这种表示方式有两个问题:向量很大并且稀疏(大部分为0),且这种编码方式无法表示单词间的关系(如“cat”和“dog”都是宠物,有语义上的相似性)。
词嵌入:
相对于独热编码,词嵌入将每个单词表示为一个更小的、密集的向量。例如,我们可以有一个3维的嵌入空间(实际应用中通常更高维)。
在这个简化的例子中,向量可能如下:
- cat: [0.9, 0.5, 0.3]
- dog: [0.8, 0.6, 0.4]
- mat: [0.1, 0.2, 0.3]
- rug: [0.15, 0.21, 0.31]
在这个嵌入空间中,“cat”和“dog”的向量很接近,这意味着它们在语义上相似。而“mat”和“rug”也很接近,因为它们都是可以坐或躺的物体。
词嵌入的美妙之处在于,当它们被训练在大量的文本数据上时,它们能够捕获更多的复杂语义和语法关系。例如,“king”和“queen”的向量之间的关系可能类似于“man”和“woman”的向量之间的关系。
这个简化的例子展示了词嵌入如何提供一种更紧凑、更有表现力的方式来表示单词,从而能够捕获单词之间的关系和语义含义。
词嵌入之前:
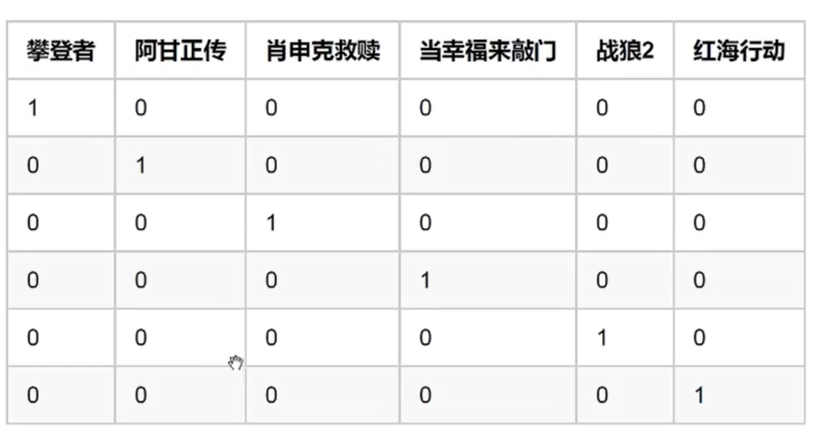
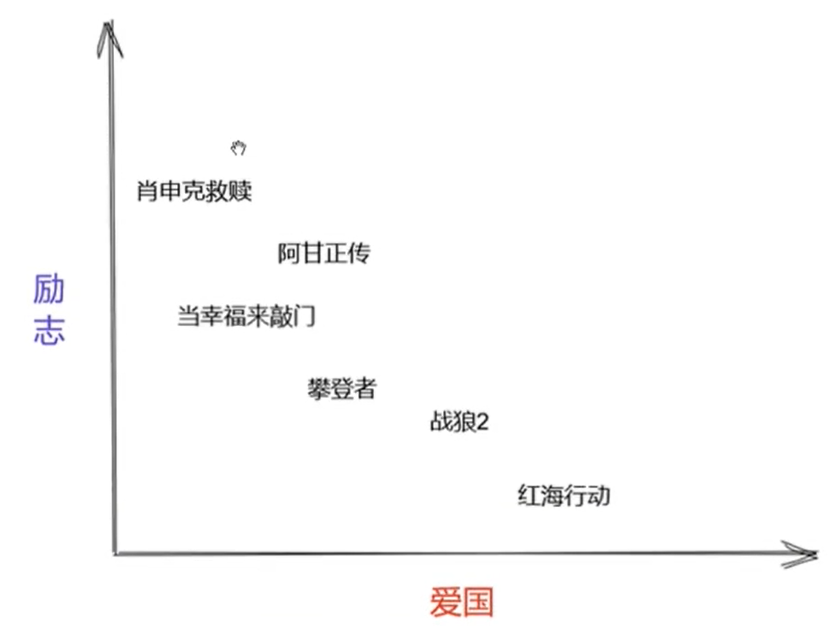
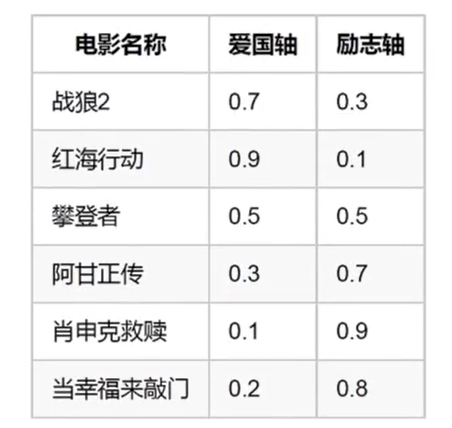
将其降成 2 维——(励志,爱国)。
-
相关阅读:
KVB:黄仁勋的职业智慧——找到一门技艺,用一生去完善、磨炼!
Revit中顶对齐风管的绘制及“管线自动对齐”功能
垃圾桶--360安全浏览器插件,用于自助过滤不良信息;
前端高度变化实现过渡动画
动态代理类的特征
23种设计模式(六)原型模式 (阁瑞钛伦特软件-九耶实训)
OKR高效落地的四个关键要素
购房,出资款性质如何认定?
Git统计提交代码量
基础语法——组合与继承
- 原文地址:https://blog.csdn.net/weixin_46713695/article/details/134065418