-
Pytorch代码入门学习之分类任务(三):定义损失函数与优化器
目录
1.3 交叉熵误差(cross entropy error)
一、定义损失函数
1.1 代码
criterion = nn.CrossEntropyLoss()1.2 损失函数简介
神经网络的学习通过某个指标表示目前的状态,然后以这个指标为基准,寻找最优的权重参数。神经网络以某个指标为线索寻找最优权重参数,该指标称为损失函数(loss function)。这个损失函数可以使用任意函数, 但一般用均方误差和交叉熵误差等。损失函数是表示神经网络性能的“恶劣程度”的指标,即当前的神经网络对监督数据在多大程度上不拟合、不一致。这个值越低,表示网络的学习效果越好。
但是,如果loss很低的话,可能出现过拟合现象。
过拟合是指训练出来的模型在训练集上表现得很好,但是在测试集上表现的较差,模型训练的误差远小于它在测试集上的误差。
1.3 交叉熵误差(cross entropy error)
交叉熵误差如下式所示:
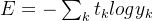
其中,log表示以e为底数的自然对数(log e );yk指神经网络的输出,tk是正确解标签。并且,tk中只有正确解标签的索引为1,其他均为0(one-hot表示)。 因此,上式实际上只计算对应正确解标签的输出的自然对数。比如,假设正确解标签的索引是“2”,与之对应的神经网络的输出是0.6,则交叉熵误差 是−log 0.6 = 0.51;若“2”对应的输出是0.1,则交叉熵误差为−log 0.1 = 2.30。因此,交叉熵误差的值是由正确解标签所对应的输出结果决定的。
交叉熵误差函数需要两个参数,第一个是输入参数(预测值),第二个是正确值。
二、定义优化器
2.1 代码
- import torch.optim as optim
- optimizer = optim.SGD(net.parameters(),lr=0.001,momentum=0.9)
2.2 构造优化器
optimizer = optim.SGD(net.parameters(),lr=0.001,momentum=0.9):第一个参数是需要更新的参数,第二个参数是指学习率(指每次更新学习率下降的大小),第三个参数为动量;
2.3 随机梯度下降法(SGD)
用数学式子可以把SGD写为如下的式:
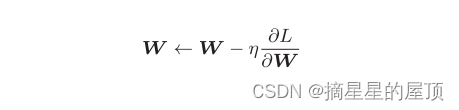
其中,W记为需要更新的权重参数,
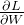 是指损失函数关于W的梯度,
是指损失函数关于W的梯度, 表示学习率,一般情况下会取为0.01或0.001这类事先决定好的值。式子中的“箭头”表示用右边的值更新左边的值。
表示学习率,一般情况下会取为0.01或0.001这类事先决定好的值。式子中的“箭头”表示用右边的值更新左边的值。SGD较为简单,且容易实现,但是在解决某些问题时可能没有效率。SGD是朝着梯度方向只前进一定距离的简单方法,且梯度的方法并没有指向最小值的方向。
-
相关阅读:
第六章 音视频-FFmpeg实现播放器解码和对应数据处理
Calendar.getInstance()获取指定时间点(定时)
Vue3与Vue2:前端进化论,从性能到体验的全面革新
用户运营的常用工具和运营策略
C++提高编程:05 STL- 常用算法
go 反射 reflect 包
visual studio 中添加qt类报错问题
windows系统edge浏览器退出账户后还能免密登录的解决方式
(STM32H5系列)STM32H573RIT6、STM32H573RIV6、STM32H573ZIT6嵌入式微控制器基于Cortex®-M33内核
linux虚拟化: svm: 初始化及重要函数分析
- 原文地址:https://blog.csdn.net/m0_53096519/article/details/134062960