-
常见面试题-MySQL专栏(一)
为什么 mysql 删了行记录,反而磁盘空间没有减少?
答:
在 mysql 中,当使用 delete 删除数据时,mysql 会将删除的数据标记为已删除,但是并不去磁盘上真正进行删除,而是在需要使用这片存储空间时,再将其从磁盘上清理掉,这是 MySQL 使用延迟清理的方式。
延迟清理的优点:
- 如果 mysql 立即删除数据,会导致磁盘上产生大量的碎片,使用延迟清理可以减少磁盘碎片,提高磁盘的读写效率
- 如果删除数据时立即清理磁盘上的数据,会消耗大量的性能。(如果一个大表存在索引,只删除其中一行,整个索引结构就会发生变化)
延迟清理的缺点:
- 这些被标记为删除的数据,就是数据空洞,不仅浪费空间,还影响查询效率。
mysql 是以数据页为单位来存储和读取数据,如果一个表有大量的数据空洞,那么 mysql 读取一个数据页,可能被标记删除的数据就占据了大量的空间,导致需要读取很多个数据页,影响查询效率
如何回收未使用空间:
optimize table 表名
索引的结构?
答:
索引是存储在引擎层而不是服务层,所以不同存储引擎的索引的工作方式也不同,我们只需要重点关注 InnoDB 存储引擎和 InnoDB 存储引擎中的索引实现,以下如果没有特殊说明,则都为 InnoDB 引擎。
mysql 支持两种索引结构: B-tree 和 HASH
- B-tree 索引
B-tree 索引结构使用 B+ 树来进行实现,结构如下图(粉色区域存放索引数据,白色区域存放下一级磁盘文件地址):
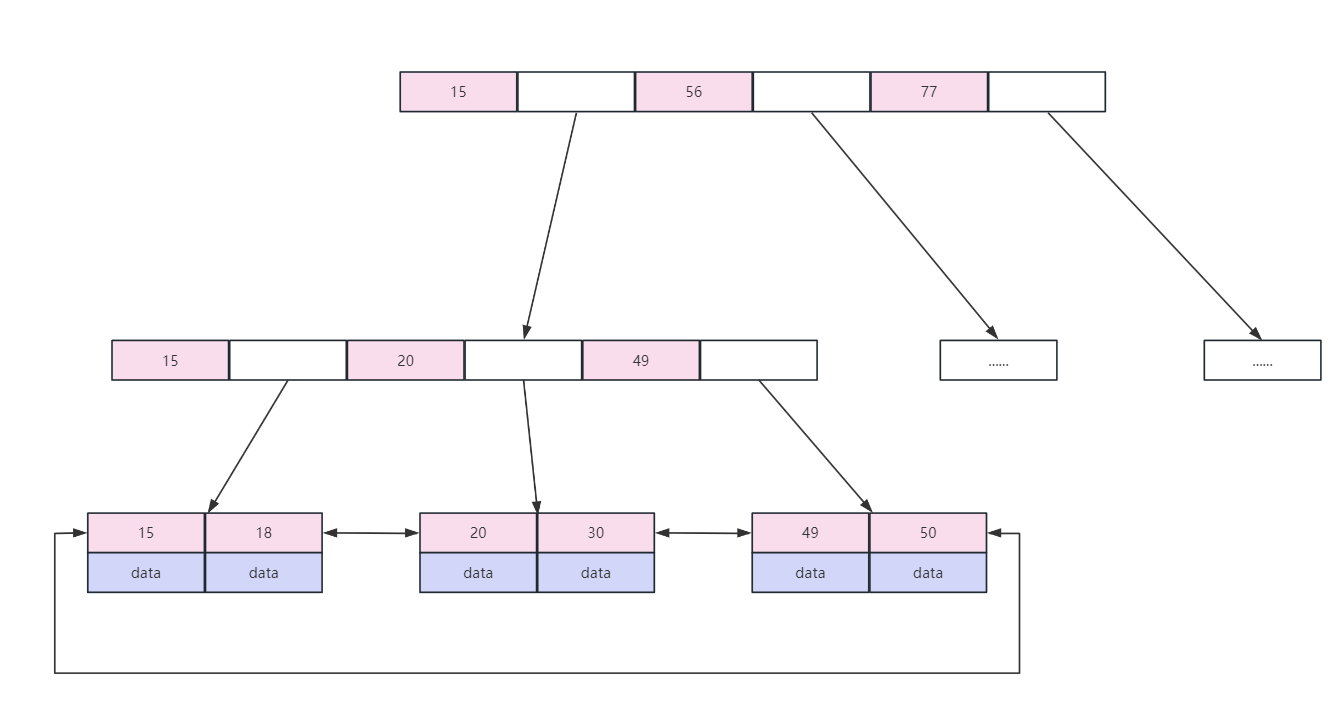
B-tree 索引(B+ 树实现)的一些特点:
- B+ 树叶子节点之间按索引数据的大小顺序建立了双向链表指针,适合按照范围查找
- 使用 B+ 树非叶子节点只存储索引,在 B 树中,每个节点的索引和数据都在一起,因此使用 B+ 树时,通过一次磁盘 IO 拿到相同大小的存储页,B+ 树可以比 B 树拿到的索引更多,因此减少了磁盘 IO 的次数。
- B+ 树查询性能更稳定,因为数据只保存在叶子节点,每次查询数据,磁盘 IO 的次数是稳定的
为什么索引能提高查询速度?
答:
索引可以让服务器快速定位到表的指定位置,索引有以下几个优点:
- 索引大大减少了服务器需要扫描的数据量
- 索引可以帮助服务器避免排序和临时表
- 索引可以将随机 IO 变为顺序 IO
前缀索引和索引的选择性?
答:
索引的选择性:指的是不重复的索引值与数据表的记录总数的比值。
索引的选择性越高,查询效率也越高,因为选择性高的索引可以让 mysql 在查找时过滤掉更多的行。唯一索引的选择性是1,这也是最好的索引选择性,性能也是最好的
前缀索引:
有时候为了提高索引的性能,并且节省索引的空间,只对字段的前一部分字符进行索引,但是存在的缺点就是:降低了索引的选择性
如何选择前缀索引的长度呢?
前缀索引的长度选择我们要兼顾索引的选择性和存储索引的空间两个方面,因此既不能太长也不能太短,可以通过计算不同前缀索引长度的选择性,找到最接近完整列的选择性的前缀长度,通过以下 sql 进行计算不同前缀索引长度的选择性:
select count(distinct left(title, 6)) / count(*) as sel6, count(distinct left(title, 7)) / count(*) as sel7, count(distinct left(title, 8)) / count(*) as sel8, count(distinct left(title, 9)) / count(*) as sel9, count(distinct left(title, 10)) / count(*) as sel10, count(distinct left(title, 11)) / count(*) as sel11, count(distinct left(title, 12)) / count(*) as sel12, count(distinct left(title, 13)) / count(*) as sel13, count(distinct left(title, 14)) / count(*) as sel14, count(distinct left(title, 15)) / count(*) as sel15, count(distinct left(title, 16)) / count(*) as sel16, count(distinct left(title, 17)) / count(*) as sel17, count(distinct left(title, 18)) / count(*) as sel18, count(distinct left(title, 19)) / count(*) as sel19, count(distinct left(title, 20)) / count(*) as sel20, count(distinct left(title, 21)) / count(*) as sel21 from interview_experience_article- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
计算结果如下:

再计算完整列的选择性:
select count(distinct title)/count(*) from interview_experience_article- 1
计算结果如下:

完整列的选择性是 0.6627,而前缀索引在长度为 16 的时候选择性为(sel16=0.6592),就已经很接近完整列的选择性了,此使再增加前缀索引的长度,选择性的提升幅度就已经很小了,因此在本例中,可以选择前缀索引长度为 16
本例中的数据是随便找的一些文本数据,类型是 text
如何创建前缀索引:
alter table table_name add key(title(16))- 1
如何选择合适的索引顺序?
答:
来源于《高性能MySQL》(第4版)
对于选择合适的索引顺序来说,有一条重要的经验法则:将选择性最高的列放到索引的最前列
在通常境况下,这条法则会有所帮助,但是存在一些特殊情况:
对于下面这个查询语句来说:
select count(distinct threadId) as count_value from message where (groupId = 10137) and (userId = 1288826) and (anonymous = 0) order by priority desc, modifiedDate desc- 1
- 2
- 3
- 4
explain 的结果如下(只列出使用了哪个索引):
id: 1 key: ix_groupId_userId- 1
- 2
可以看出选择了索引(groupId, userId),看起来比较合理,但是我们还没有考虑(groupId、userId)所匹配到的数据的行数:
select count(*), sum(groupId=10137), sum(userId=1288826), sum(anonymous=0) from message- 1
- 2
结果如下:
count(*): 4142217 sum(groupId=10137): 4092654 sum(userId=1288826): 1288496 sum(anonymous=0): 4141934- 1
- 2
- 3
- 4
可以发现通过 groupId 和 userId 基本上没有筛选出来多少条数据
因此上边说的经验法则一般情况下都适用,但是在特殊形况下,可能会摧毁整个应用的性能
上边这种情况的出现是因为这些数据是从其他应用迁移过来的,迁移的时候把所有的消息都赋予了管理组的用户,因此导致这样查询出来的数据量非常大,这个案例的解决情况是修改应用程序的代码:区分这类特殊用户和组,禁止针对这类用户和组执行这个查询
聚簇索引和非聚簇索引的区别?非聚集索引一定回表查询吗?
答:
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。
当表里有聚簇索引时,它的数据行实际上存放在索引的叶子节点中。
聚簇表示数据行和相邻和键值存储在一起
InnoDB 根据主键来聚簇数据,如果没有定义主键的话,InnoDB 会隐式定义一个主键来作为聚簇索引,
聚簇索引的优点:
- 数据访问更快。聚簇索引将数据和索引保存在同一个 B-tree 中,获取数据比非聚簇索引更快
- 使用覆盖索引扫描的查询可以直接使用叶节点的主键值
聚簇索引的缺点:
- 提升了 IO 密集型应用的性能。(如果数据全部放在内存中的话,不需要执行 IO 操作,聚集索引就没有什么优势了)
- 插入速度严重依赖于插入顺序。按照主键的顺序插入行是将数据加载到 InnoDB 表中最快的方式。
如果不是按照逐渐顺序加载数据,在加载完之后最好使用 optimize table 重新组织一下表,该操作会重建表。重建操作能更新索引统计数据并释放聚簇索引中的未使用的空间。
可以使用show table status like '[table_name]'查看优化前后表占用的存储空间 - 更新聚集索引的代价很高。因为会强制 InnoDB 将每个被更新的行移动到新的位置
- 基于聚簇索引的表在插入新行是或者主键被更新到只需要移动行的时候,可能面临 页分裂 的问题,当行的主键值需要插入某个已经满了的页中时,存储引擎会将该页分裂成两个页面来存储,也就是页分裂操作,页分裂会导致表占用更多的磁盘空间
- 聚簇索引可能会导致全表扫描变慢,尤其是行比较稀疏或者由于页分裂导致数据存储不连续的时候
- 二级索引(也是非聚簇索引)可能比想象的要更大,因为在二级索引的叶子节点存储了指向行的主键列。
- 二级索引访问需要两次索引查找,而不是一次。
二级索引中,叶子节点保存的是指向行的主键值,那么如果通过二级索引进行查找,找到二级索引的叶子节点,会先获取对应数据的主键值,然后再根据这个值去聚簇索引中查找对应的行数据。(两次索引查找)
二级索引是什么?为什么已经有了聚集索引还需要使用二级索引?
答:
二级索引是非主键索引,也是非聚集索引(索引和数据分开存放),也就是在非主键的字段上创建的索引就是二级索引。
比如我们给一张表里的 name 字段加了一个索引,在插入数据的时候,就会重新创建一棵 B+ 树,在这棵 B+ 树中,就来存放 name 的二级索引。
即在二级索引中,索引是 name 值,数据(data)存放的是主键的值,第一次索引查找获取了主键值,之后根据主键值再去聚集索引中进行第二次查找,才可以找到对应的数据。
常见的二级索引:
- 唯一索引
- 普通索引
- 前缀索引:只适用于字符串类型的字段,取字符串的前几位字符作为前缀索引。
为什么已经有了聚簇索引还需要使用二级索引?
聚簇索引的叶子节点存储了完整的数据,而二级索引只存储了主键值,因此二级索引更节省空间。如果需要为表建立多个索引的话,都是用聚簇索引的话,将占用大量的存储空间。
为什么在 InnoDB 表中按逐渐顺序插入行速度更快呢?
答:
向表里插入数据,主键可以选择整数自增 ID 或者 UUID。
- 如果选择自增 ID 作为主键
那么在向表中插入数据时,插入的每一条新数据都在上一条数据的后边,当达到页的最大填充因子(InnoDB 默认的最大填充因子是页大小的 15/16,留出部分空间用于以后修改)时,下一条记录就会被写入到新的页中。
- 如果选择 UUID 作为主键
在插入数据时,由于新插入的数据的主键的不一定比之前的大,所以 InnoDB 需要为新插入的数据找到一个合适的位置——通常是已有数据的中间位置,有以下缺点:
- 写入的目标也可能已经刷到磁盘上并从内存中删除,或者还没有被加载到内存中,那么 InnoDB 在插入之前,需要先将目标页读取到内存中。这会导致大量随机 IO
- 写入数据是乱序的,所以 InnoDB 会频繁执行页分裂操作
- 由于频繁的页分裂,页会变得稀疏并且被不规则地填充,最终数据会有碎片
什么时候使用自增 ID 作为主键反而更糟?
在高并发地工作负载中,并发插入可能导致间隙锁竞争。
-
相关阅读:
Java SE 10 新增特性
Linux常用快捷键汇总
神经网络用于控制的优越性,神经网络稳定性理论
【20220912】电商业务的核心流程
【RocketMQ】事务的实现原理
代码随想录第五十六天
栈与队列练习题
什么是私域流量,私域流量的媒介有哪些?
MPCS-480 LSOP-6 IPM正输出图腾极 高速光电耦合器代替TLP2710
左值引用与右值引用疑点总结
- 原文地址:https://blog.csdn.net/qq_45260619/article/details/134066080
