-
CNN 网络结构简介
本文通过整理李宏毅老师的机器学习教程的内容,介绍 CNN(卷积神经网络)的网络结构。
CNN 主要应用在图像识别(image classification, 图像分类)领域。
通常,输入的图片大小相同,如 100 × 100 100 \times 100 100×100,输出的分类为 one-hot 形式:
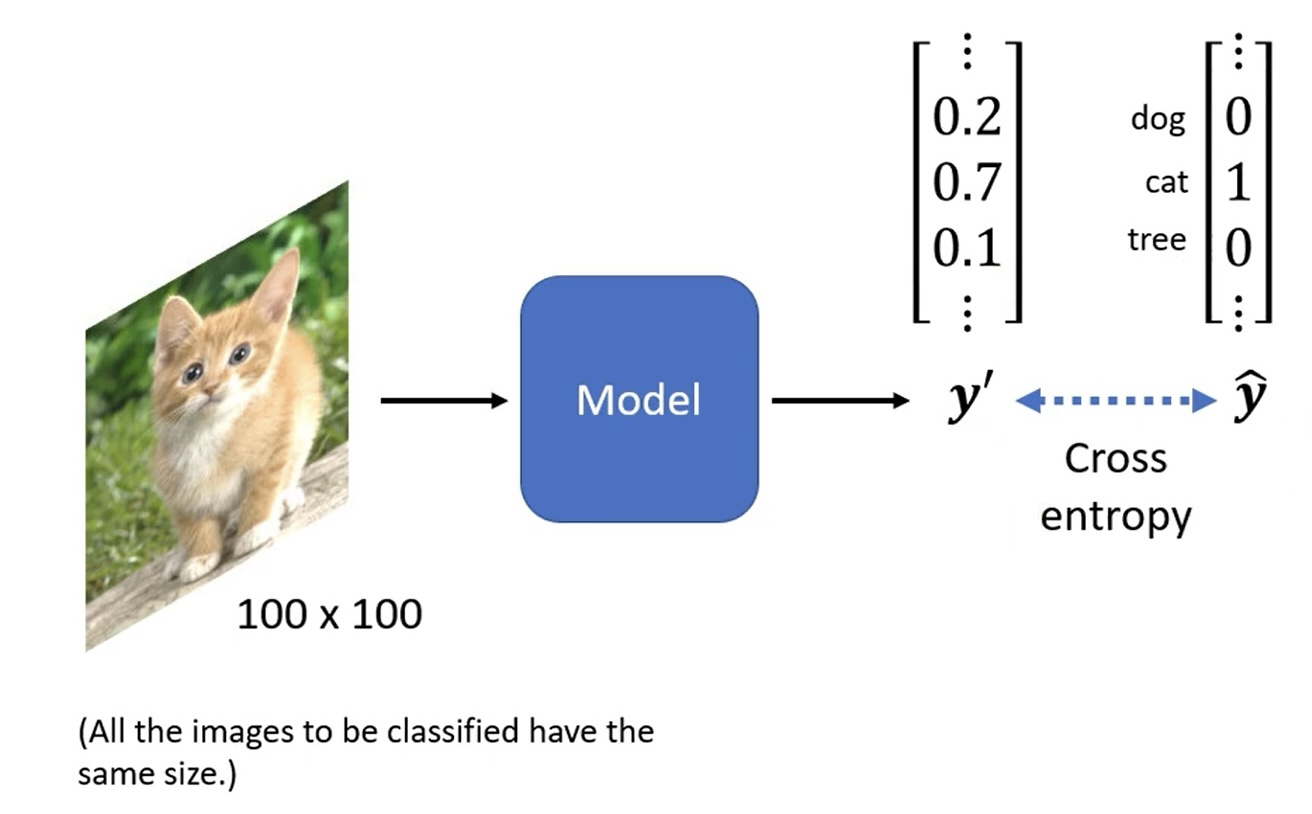
输入数据的格式为 tensor(张量),维数为:宽度 × \times × 高度 × \times × channel(频道)数:

理解方式一:神经元视角(neuron version story)
如果使用全连接(fully connected network)的网络结构,参数量会非常大:

考虑到图片识别问题的特性,其实并不需要全连接的网络,下面基于此进行简化。
感受野
图像识别本质上是对图像中的各个部位进行识别,如一只鸟的喙、眼和爪等,因此每个神经元(neuron)只需输入图片的一部分即可,即感受野(receptive field):

值得注意的是:
- 不同神经元的感受野可以重叠;
- 同一个感受野也可以有多个神经元用以侦测不同的特征:

此外,感受野还可以有一些其他的操作:
- 可以有大有小;
- 可以只考虑部分 channel,在通常的 CNN 中不常见,但在 network corporation 时会遇到;
- 可以是长方形;
- 理论上甚至可以不相连,但是要想清楚这样做的理由。
总之,感受野可以任意设计。
最经典的感受野的设计如下:
- 考虑所有 channel,因此只需要输入宽度和高度即可,宽度和高度合称为 kernel size;
- kernal size 往往不会很大,如 3 × 3 3 \times 3 3×3,后面会解释如何对更大范围的模式(pattern)进行识别;
- 同一个感受野会有多个神经元;
- 感受野的移动步长(stride)不要太大,通常为 1 或 2,希望感受野之间有重叠,防止感受野交界上的模式被遗漏;
- 对于位于边界上、超出范围的感受野,需要对超出的位置进行补值(padding),通常补 0,也有其他补值方法,如补全图的平均值,或补边界值等;
- 感受野整体要覆盖全图。
参数共享
由于同样的模式可能出现在图片的不同位置:

于是侦测不同位置的相同模式的神经元,其对应的参数相同,即参数共享:

侦测相同位置的神经元不能共享参数。
共享的参数叫做滤波器(filter):

综上所述,以上两种 CNN 对全连接网络的简化方式:

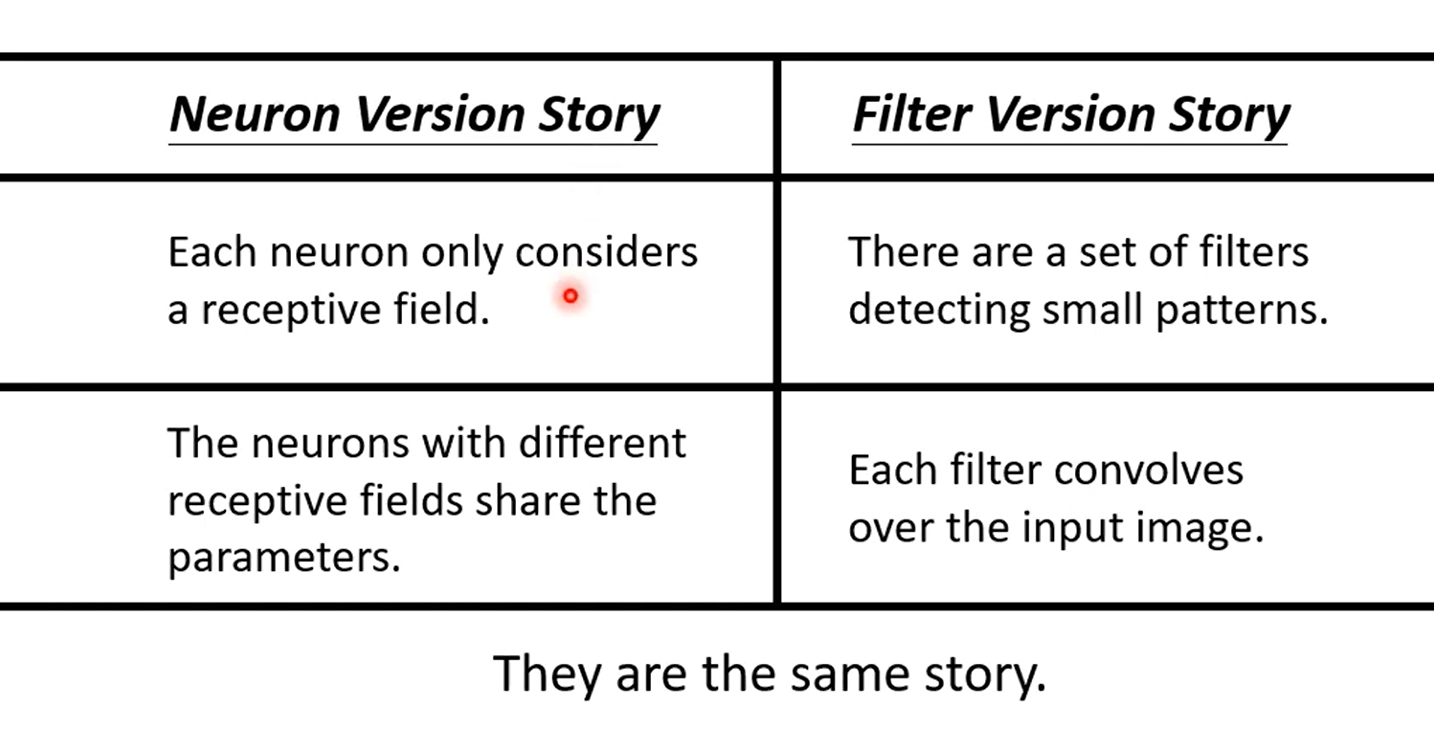
理解方式二:滤波器视角(filter version story)
将每个卷积层(convolutional layer)视为若干滤波器扫过整张图片,去识别对应的模式:


同一卷积层的所有滤波器输出的所有数据叫做 feature map,它可以看成是另一张图片,只不过 channel 数量由 3 个(RGB)变成了滤波器的数量,因此下一层的滤波器的高度需要设为上一层的滤波器数量:

当网络更深时,同样大小的感受野所看到的范围会越来越大,例如,同样是 3 × 3 3 \times 3 3×3 的感受野,在第二层就可以看到原图片中 5 × 5 5 \times 5 5×5 的范围:

此外,第一种理解方式中的参数共享,即是把滤波器扫过整张图片的过程。
两种理解方式总结如下:
有关 pooling
pooling 即 subsampling,是把一张大的图片缩小,以减少运算量的过程。
常见的 pooling 方式为 max pooling,即保留最大值:


通常是做一层或几层卷积后,做一次 pooling,整体网络结构如下:

但近年来,pooling 用得越来越少,甚至可有可无,因为其操作会影响性能,而运算资源又越来越强。
AlphaGo 的网络结构

其中,rectifier nonlinearity 即为 ReLU。
此外,AlphaGo 没有使用 pooling。
局限性
CNN 无法处理图片放大缩小或旋转的情形,解决方案有:
- 数据增强(data augmentation),即把训练资料的每张图片都截成小块再放大,并把每张图片都旋转,使网络看到放大和旋转后的图片;
- 使用 spatial transformer layer。
-
相关阅读:
算法入门(六):归并排序
【计网】链路层
Eclipse中去掉javaResources文件夹
uniapp 小程序 堆叠轮播图 左滑 右滑 自动翻页 点击停止自动翻页
[N1CTF 2018]eating_cms
Ubuntu20.04中复现FoundationPose
17-Linux进程管理
arm架构,django4.2.7适配达梦8数据库
eslint+stylelint+prettier全流程配置
网络安全学习--操作系统安全防护
- 原文地址:https://blog.csdn.net/Zhang_0702_China/article/details/134059372