-
使用 DDPO 在 TRL 中微调 Stable Diffusion 模型
引言
扩散模型 (如 DALL-E 2、Stable Diffusion) 是一类文生图模型,在生成图像 (尤其是有照片级真实感的图像) 方面取得了广泛成功。然而,这些模型生成的图像可能并不总是符合人类偏好或人类意图。因此出现了对齐问题,即如何确保模型的输出与人类偏好 (如“质感”) 一致,或者与那种难以通过提示来表达的意图一致?这里就有强化学习的用武之地了。
在大语言模型 (LLM) 领域,强化学习 (RL) 已被证明是能让目标模型符合人类偏好的非常有效的工具。这是 ChatGPT 等系统卓越性能背后的主要秘诀之一。更准确地说,强化学习是人类反馈强化学习 (RLHF) 的关键要素,它使 ChatGPT 能像人类一样聊天。
在 Training Diffusion Models with Reinforcement Learning 一文中,Black 等人展示了如何利用 RL 来对扩散模型进行强化,他们通过名为去噪扩散策略优化 (Denoising Diffusion Policy Optimization,DDPO) 的方法针对模型的目标函数实施微调。
在本文中,我们讨论了 DDPO 的诞生、简要描述了其工作原理,并介绍了如何将 DDPO 加入 RLHF 工作流中以实现更符合人类审美的模型输出。然后,我们切换到实战,讨论如何使用
trl库中新集成的DDPOTrainer将 DDPO 应用到模型中,并讨论我们在 Stable Diffusion 上运行 DDPO 的发现。DDPO 的优势
DDPO 并非解决
如何使用 RL 微调扩散模型这一问题的唯一有效答案。在进一步深入讨论之前,我们强调一下在对 RL 解决方案进行横评时需要掌握的两个关键点:
计算效率是关键。数据分布越复杂,计算成本就越高。
近似法很好,但由于近似值不是真实值,因此相关的错误会累积。
在 DDPO 之前,奖励加权回归 (Reward-Weighted Regression,RWR) 是使用强化学习微调扩散模型的主要方法。RWR 重用了扩散模型的去噪损失函数、从模型本身采样得的训练数据以及取决于最终生成样本的奖励的逐样本损失权重。该算法忽略中间的去噪步骤/样本。虽然有效,但应该注意两件事:
通过对逐样本损失进行加权来进行优化,这是一个最大似然目标,因此这是一种近似优化。
加权后的损失甚至不是精确的最大似然目标,而是从重新加权的变分界中得出的近似值。
所以,根本上来讲,这是一个两阶近似法,其对性能和处理复杂目标的能力都有比较大的影响。
DDPO 始于此方法,但 DDPO 没有将去噪过程视为仅关注最终样本的单个步骤,而是将整个去噪过程构建为多步马尔可夫决策过程 (MDP),只是在最后收到奖励而已。这样做的好处除了可以使用固定的采样器之外,还为让代理策略成为各向同性高斯分布 (而不是任意复杂的分布) 铺平了道路。因此,该方法不使用最终样本的近似似然 (即 RWR 的做法),而是使用易于计算的每个去噪步骤的确切似然 ( )。
如果你有兴趣了解有关 DDPO 的更多详细信息,我们鼓励你阅读 原论文 及其 附带的博文。
DDPO 算法简述
考虑到我们用 MDP 对去噪过程进行建模以及其他因素,求解该优化问题的首选工具是策略梯度方法。特别是近端策略优化 (PPO)。整个 DDPO 算法与近端策略优化 (PPO) 几乎相同,仅对 PPO 的轨迹收集部分进行了比较大的修改。
下图总结了整个算法流程:
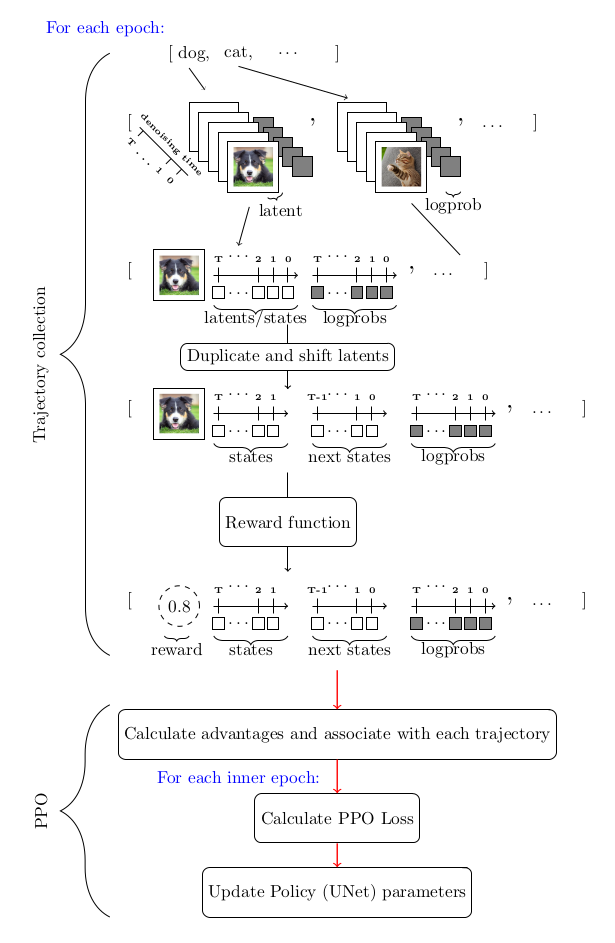
dppo rl 流图 DDPO 和 RLHF: 合力增强美观性
RLHF 的一般训练步骤如下:
有监督微调“基础”模型,以学习新数据的分布。
收集偏好数据并用它训练奖励模型。
使用奖励模型作为信号,通过强化学习对模型进行微调。
需要指出的是,在 RLHF 中偏好数据是获取人类反馈的主要来源。
DDPO 加进来后,整个工作流就变成了:
从预训练的扩散模型开始。
收集偏好数据并用它训练奖励模型。
使用奖励模型作为信号,通过 DDPO 微调模型
请注意,DDPO 工作流把原始 RLHF 工作流中的第 3 步省略了,这是因为经验表明 (后面你也会亲眼见证) 这是不需要的。
下面我们实战一下,训练一个扩散模型来输出更符合人类审美的图像,我们分以下几步来走:
从预训练的 Stable Diffusion (SD) 模型开始。
在 美学视觉分析 (Aesthetic Visual Analysis,AVA) 数据集上训练一个带有可训回归头的冻结 CLIP 模型,用于预测人们对输入图像的平均喜爱程度。
使用美学预测模型作为奖励信号,通过 DDPO 微调 SD 模型。
记住这些步骤,下面开始干活:
使用 DDPO 训练 Stable Diffusion
环境设置
首先,要成功使用 DDPO 训练模型,你至少需要一个英伟达 A100 GPU,低于此规格的 GPU 很容易遇到内存不足问题。
使用 pip 安装
trl库pip install trl[diffusers]主库安装好后,再安装所需的训练过程跟踪和图像处理相关的依赖库。注意,安装完
wandb后,请务必登录以将结果保存到个人帐户。pip install wandb torchvision注意: 如果不想用
wandb,你也可以用pip安装tensorboard。演练一遍
trl库中负责 DDPO 训练的主要是DDPOTrainer和DDPOConfig这两个类。有关DDPOTrainer和DDPOConfig的更多信息,请参阅 相应文档。trl代码库中有一个 示例训练脚本。它默认使用这两个类,并有一套默认的输入和参数用于微调RunwayML中的预训练 Stable Diffusion 模型。此示例脚本使用
wandb记录训练日志,并使用美学奖励模型,其权重是从公开的 Hugging Face 存储库读取的 (因此数据收集和美学奖励模型训练均已经帮你做完了)。默认提示数据是一系列动物名。用户只需要一个命令行参数即可启动脚本。此外,用户需要有一个 Hugging Face 用户访问令牌,用于将微调后的模型上传到 Hugging Face Hub。
运行以下 bash 命令启动程序:
python stable_diffusion_tuning.py --hf_user_access_token下表列出了影响微调结果的关键超参数:
参数 描述 单 GPU 训练推荐值(迄今为止) num_epochs训练 epoch数200 train_batch_size训练 batch size 3 sample_batch_size采样 batch size 6 gradient_accumulation_steps梯度累积步数 1 sample_num_steps采样步数 50 sample_num_batches_per_epoch每个 epoch的采样 batch 数4 per_prompt_stat_tracking是否跟踪每个提示的统计信息。如果为 False,将使用整个 batch 的平均值和标准差来计算优势,而不是对每个提示进行跟踪Trueper_prompt_stat_tracking_buffer_size用于跟踪每个提示的统计数据的缓冲区大小 32 mixed_precision混合精度训练 Truetrain_learning_rate学习率 3e-4 这个脚本仅仅是一个起点。你可以随意调整超参数,甚至彻底修改脚本以适应不同的目标函数。例如,可以集成一个测量 JPEG 压缩度的函数或 使用多模态模型评估视觉文本对齐度的函数 等。
经验与教训
尽管训练提示很少,但其结果似乎已经足够泛化。对于美学奖励函数而言,该方法已经得到了彻底的验证。
尝试通过增加训练提示数以及改变提示来进一步泛化美学奖励函数,似乎反而会减慢收敛速度,但对模型的泛化能力收效甚微。
虽然推荐使用久经考验 LoRA,但非 LoRA 也值得考虑,一个经验证据就是,非 LoRA 似乎确实比 LoRA 能产生相对更复杂的图像。但同时,非 LoRA 训练的收敛稳定性不太好,对超参选择的要求也高很多。
对于非 LoRA 的超参建议是: 将学习率设低点,经验值是大约
1e-5,同时将mixed_ precision设置为None。
结果
以下是提示
bear、heaven和dune微调前 (左) 、后 (右) 的输出 (每行都是一个提示的输出):微调前 微调后 





限制
目前
trl的DDPOTrainer仅限于微调原始 SD 模型;在我们的实验中,主要关注的是效果较好的 LoRA。我们也做了一些全模型训练的实验,其生成的质量会更好,但超参寻优更具挑战性。
总结
像 Stable Diffusion 这样的扩散模型,当使用 DDPO 进行微调时,可以显著提高图像的主观质感或其对应的指标,只要其可以表示成一个目标函数的形式。
DDPO 的计算效率及其不依赖近似优化的能力,在扩散模型微调方面远超之前的方法,因而成为微调扩散模型 (如 Stable Diffusion) 的有力候选。
trl库的DDPOTrainer实现了 DDPO 以微调 SD 模型。我们的实验表明 DDPO 对很多提示具有相当好的泛化能力,尽管进一步增加提示数以增强泛化似乎效果不大。为非 LoRA 微调找到正确超参的难度比较大,这也是我们得到的重要经验之一。
DDPO 是一种很有前途的技术,可以将扩散模型与任何奖励函数结合起来,我们希望通过其在 TRL 中的发布,社区可以更容易地使用它!
致谢
感谢 Chunte Lee 提供本博文的缩略图。
🤗 宝子们可以戳 阅读原文 查看文中所有的外部链接哟!
英文原文: https://hf.co/blog/trl-ddpo
原文作者: Luke Meyers,Sayak Paul,Kashif Rasul,Leandro von Werra
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
审校/排版: zhongdongy (阿东)
-
相关阅读:
【算法系列】卡尔曼滤波算法
【MySQL调优(二)】性能监控分析 - Show Profile
Spring core项目的创建与使用
分省/市/县最低工资标准(2012-2021年)和 全国/省/市/县GDP数据(1949-2020年)
Asp.net MVC中文件夹中的控制器如何跳转到根目录的控制器中?
中英文说明书丨Abbkine 总蛋白提取试剂盒解决方案
聊聊不是产品经理的程序员如何做产品经理
【Unity开发实战】—— 2D项目1 - Ruby‘s Adventure 游戏世界中各个对象的交互(3-1)
uniapp调起拨打手机号
Win 7 VPN拨号错误734.
- 原文地址:https://blog.csdn.net/HuggingFace/article/details/134002638