-
【python笔记】小甲鱼
基本语法
P1
P2
P3
dir()
查看内置函数
dir(__builtins__)变量和字符串
P4
变量名命名规则:
1、变量名不能以数字打头;
2、变量名可以是中文
字符串可以是:
1、单引号:文本中存在双引号时使用单引号2、双引号:文本中存在单引号时使用双引号
当文本中既有单引号又有双引号时使用转义字符。
P5
原始字符串:在字符串前加 r ,转义字符将不再有效
- >>> print("D:\three\two\one\now")
- D: hree wo\one
- ow
- >>> print(r"D:\three\two\one\now")
- D:\three\two\one\now
反斜杠不能放在字符串的末尾,若某行的末尾是反斜杠,则说明字符串还没有结束。反斜杠可以让字符串跨行。
三引号:分为三单引号或三双引号,前后要对应,可以实现字符串的跨行而不需要行末的反斜杠。
字符串的加法和乘法:
1、加法:拼接
2、乘法:复制
P6
input()
字符串的输入input方法:输入的是字符串,如需要数字则需要强转一下。
- >>> temp=input("你是谁?")
- 你是谁?我是你霸霸
- >>> temp
- '我是你霸霸'
- >>> num=input("请输入一个数字")
- 请输入一个数字8
- >>> num
- '8'
- >>> NUM=int(num)
- >>> NUM
- 8
if...else...语句和while循环
P7
if...else...语句:
- a = 1
- if a < 3:
- print("a is small")
- else:
- print('a is big')
- a = 5
- if a < 3:
- print("a is small")
- else:
- print('a is big')
- a is small
- a is big
while循环:
- counts = 3
- while counts > 0:
- print("I love HZQ")
- counts = counts - 1
- I love HZQ
- I love HZQ
- I love HZQ
break语句:
跳出一层循环体。
random模块
P8
random模块
1、random.randint(a,b)函数,返回一个a~b的伪随机数;
2、random.getstate()函数,返回随机数种子
3、random.setstate(x)函数,设置随机数种子,
随机数种子相同时,生成的伪随机数顺序相同。
数字类型
P9
1、python可以随时随地进行大数的计算。
2、python存储浮点数存在误差,浮点数并不是百分之百精确的,
- >>> 0.1+0.2
- 0.30000000000000004
- >>> i=0
- >>> while i<1:
- ... i=i+0.1
- ... print(i)
- ...
- 0.1
- 0.2
- 0.30000000000000004
- 0.4
- 0.5
- 0.6
- 0.7
- 0.7999999999999999
- 0.8999999999999999
- 0.9999999999999999
- 1.0999999999999999
3、python要想精确地计算浮点数,需要 decimal 模块。
- >>> import decimal
- >>> a=decimal.Decimal('0.1')
- >>> b=decimal.Decimal('0.2')
- >>> print(a+b)
- 0.3
- >>> c=decimal.Decimal('0.3')
- >>> c==a+b
- True
4、科学计数法
- >>> 0.0000000000005
- 5e-13
- >>> 0.00000000004003002050403
- 4.003002050403e-11
5、复数
复数的实部和虚部都是浮点数的形式存储的
- >>> a=1-2j
- >>> a
- (1-2j)
- >>> a.real
- 1.0
- >>> a.imag
P10

1,x//y,地板除,结果向下取整。
2,abs(x),返回x的绝对值,x为复数时返回模值。
3,complex(a,b)函数,括号中可以是两个数字表示实部和虚部,也可以是复数对应的字符串。
- >>> complex(1,3)
- (1+3j)
- >>> complex('3+8j')
- (3+8j)
布尔类型
P11
1,布尔值为False的情况:

2,
and和or都是短路逻辑,下方代码中几种情况需要记住。
- >>> 3 and 4
- 4
- >>> 3 or 4
- 3
- >>> "HZQ" and "LOVE"
- 'LOVE'
- >>> '''HZQ''' and """LOVE"""
- 'LOVE'
- >>> '''HZQ''' or """LOVE"""
- 'HZQ'
运算符优先级
P12
1,运算符优先级

流程图
P13
流程图

P14
分支和循环
P15、P16
1,基本结构:if.... elif.... else....
2,条件表达式:
- score = 76
- level = ("D" if 0 <= score < 60 else
- "C" if 60 <= score < 70 else
- "B" if 70 <= score < 80 else
- "A" if 80 <= score < 100 else
- "S" if score == 100 else
- print("请输入0~100之间的数字"))
- print(level)
- 运行结果:B
P17
P18
1,continue,结束本轮循环,开始下一轮循环
2,while...else...语句:while后的条件不成立时,执行一次else后的操作
P19
1,for循环:
- for 变量 in 可迭代对象 :
- statement(s)
- >>> for each in "FishC":
- ... print(each)
- ...
- F
- i
- s
- h
- C
- >>> each
- 'C'
- 1000不是可迭代对象,故以下代码报错
- >>> for each in 1000 :
- ... print(each)
- ...
- Traceback (most recent call last):
- File "
" , line 1, in <module> - TypeError: 'int' object is not iterable
2,range()函数,用于生成数字序列,将数字变为可迭代对象,形式如下:
range(stop)
range(start,stop)
range(start,stop,step)
生成的序列包括start,不包括stop
- >>> for i in range(10):
- ... print(i)
- ...
- 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- >>> for i in range(8,17,2):
- ... print(i)
- ...
- 8
- 10
- 12
- 14
- 16
列表
P20
列表索引,列表切片
P21
1,append()方法:列表添加一个元素
- >>> a=[1,2,3]
- >>> a
- [1, 2, 3]
- >>> a.append('q')
- >>> a
- [1, 2, 3, 'q']
2,extend()方法:列表添加一个可迭代对象
- >>> a
- [1, 2, 3, 'q']
- >>> a.extend([5,56,'gf'])
- >>> a
- [1, 2, 3, 'q', 5, 56, 'gf']
3,切片添加元素
- >>> a=[1,2,3,4,5]
- >>> a[len(a):]=[6]
- >>> a
- [1, 2, 3, 4, 5, 6]
- >>> a[len(a):]=['qq',2,"ed"]
- >>> a
- [1, 2, 3, 4, 5, 6, 'qq', 2, 'ed']
4,insert()方法, 指定位置插入元素
- >>> a=[1,3,4,5]
- >>> a.insert(1,2)
- >>> a
- [1, 2, 3, 4, 5]
- >>> a.insert(0,0)
- >>> a
- [0, 1, 2, 3, 4, 5]
- >>> a.insert(len(a),6)
- >>> a
- [0, 1, 2, 3, 4, 5, 6]
5,remove()方法,删除列表元素,若有多个待删除元素,未指定时删除下标最小的一个。
- >>> a=[1,2,3,4,5]
- >>> a.remove(3)
- >>> a
- [1, 2, 4, 5]
- >>> a=[1,2,4,3,4,4,5,6,7]
- >>> a.remove(4)
- >>> a
- [1, 2, 3, 4, 4, 5, 6, 7]
6,pop()方法,通过下标删除元素,同时返回删除的元素
- >>> a
- [1, 2, 3, 4, 4, 5, 6, 7]
- >>> a.pop(3)
- 4
- >>> a
- [1, 2, 3, 4, 5, 6, 7]
- >>> a.pop(5)
- 6
- >>> a
- [1, 2, 3, 4, 5, 7]
7,clear(),清空列表
- >>> a
- [1, 2, 3, 4, 5, 7]
- >>> a.clear()
- >>> a
- []
P22
1,s.sort(key=None,reverse=False)方法,对列表中的元素进行原地排序(key 参数用于指定一个用于比较的函数;reverse 参数用于指定排序结果是否反转)
2,reverse()方法,纯数字列表从大到小排序
3,count(a),返回元素出现的次数
4,index(a,start,end),返回元素的索引
5,copy(),拷贝列表
6,切片和copy都是浅拷贝,
*P23
1,对于嵌套列表,用乘法进行拷贝时,内存中开辟的空间是同一个;
判断是否在内存中开辟空间是同一个用 is 关键词
列表元素用*复制,指向同一内存空间,用*复制后在分别赋值,则指向不同空间;
- >>> A=[0]*3
- >>> for i in range(3):
- ... A[i]=[0]*2
- ...
- >>> A
- [[0, 0], [0, 0], [0, 0]]
- >>> B=[[0]*2]*3
- >>> B
- [[0, 0], [0, 0], [0, 0]]
- >>> A[1][1]=1
- >>> B[1][1]=1
- >>> A
- [[0, 0], [0, 1], [0, 0]]
- >>> B
- [[0, 1], [0, 1], [0, 1]]
2,两个相同的字符串分别赋值,即使不是用*复制的,内存空间也是指向同一个,因为字符串和列表不同,字符串是不可变的。
- >>> a=[1,2,3]
- >>> b=[1,2,3]
- >>> a is b
- False
- >>> c="WAHZQ"
- >>> d='WAHZQ'
- >>> c is d
- True
P24
1,等号赋值单个变量,只是让两个变量地址相同,改变一个变量时,这个变量的地址将会改变,两个变量地址将不相同。
- >>> a=2
- >>> b=a
- >>> a is b
- True
- >>> a=3
- >>> b
- 2
- >>> a is b
- False
等号赋值列表,是让两个变量列表地址相同,当改变其中一个列表的某一元素时,另一个列表中对应元素也改变。当对整个列表赋值时,这个列表的地址将会改变。
- >>> a=[1,2,3,'qwe']
- >>> b=a
- >>> b is a
- True
- >>> b
- [1, 2, 3, 'qwe']
- >>> a[1]=5
- >>> b
- [1, 5, 3, 'qwe']
- >>> b=[1,5,3,'qwe']
- >>> b is a
- False
2,copy()方法,切片
copy()方法和切片不仅拷贝列表的引用,拷贝的是整个列表,拷贝后的列表与被拷贝的列表的地址不同,改变一个元素,另一个列表中对应元素的值不变。
- >>> a=[1,2,3]
- >>> b=a.copy()
- >>> b
- [1, 2, 3]
- >>> a[1]=5
- >>> b
- [1, 2, 3]
- >>> a is b
- False
- >>> c=a[:]
- >>> a[0]=8
- >>> c
- [1, 5, 3]
- >>> a is c
- False
3,深拷贝
copy()方法和切片可以拷贝一维列表,当二维列表时,将不能完成内层的拷贝。
- >>> a=[[1,2,3],[4,5,6],[7,8,9]]
- >>> b=a.copy()
- >>> b
- [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
- >>> a[1][1]=0
- >>> a
- [[1, 2, 3], [4, 0, 6], [7, 8, 9]]
- >>> b
- [[1, 2, 3], [4, 0, 6], [7, 8, 9]]
这时候就需要用到深拷贝了,即copy模块中的deepcopy()函数,copy模块中的copy()函数也是浅拷贝,但是浅拷贝的效率更高,速度快。
- >>> import copy
- >>> a=[[1,2,3],[4,5,6],[7,8,9]]
- >>> b=copy.copy(a)
- >>> b
- [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
- >>> a[1][1]=0
- >>> b
- [[1, 2, 3], [4, 0, 6], [7, 8, 9]]
- >>> c=copy.deepcopy(a)
- >>> a[1][0]=0
- >>> a
- [[1, 2, 3], [0, 0, 6], [7, 8, 9]]
- >>> c
- [[1, 2, 3], [4, 0, 6], [7, 8, 9]]
is()方法验证:
- >>> import copy
- >>> a=[[1,2,3],[4,5,6],[7,8,9]]
- >>> b=copy.copy(a)
- >>> c=copy.deepcopy(a)
- >>> d=a
- >>> a is b
- False
- >>> a is c
- False
- >>> a is d
- True
- >>> a[1] is b[1]
- True
- >>> a[1] is c[1]
- False
- >>> a[1][1] is b[1][1]
- True
- >>> a[1][1] is c[1][1]
- True
故拷贝能力强弱顺序为:
(=赋值) < (copy方法、切片操作、copy模块中的copy函数) < (copy模块中的deepcopy函数)
对于深层拷贝,再多一层还是可以完美拷贝:
- >>> a=[[[11,13,14],2,3],[4,5,6],[7,8,9]]
- >>> e=copy.deepcopy(a)
- >>> e
- [[[11, 13, 14], 2, 3], [4, 5, 6], [7, 8, 9]]
- >>> a[0][0][0]=22
- >>> a
- [[[22, 13, 14], 2, 3], [4, 5, 6], [7, 8, 9]]
- >>> e
- [[[11, 13, 14], 2, 3], [4, 5, 6], [7, 8, 9]]
P25
ord()函数:将字符转换为Unicode编码
列表推导式
- >>> oho=[1,2,3,4,5]
- >>> x=[i*2 for i in oho]
- >>> x
- [2, 4, 6, 8, 10]
- >>> y=[i+1 for i in range(10)]
- >>> y
- [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
P26
1,列表推导式创建二维列表
- >>> a=[[0]*3 for i in range(3)]
- >>> a
- [[0, 0, 0], [0, 0, 0], [0, 0, 0]]
- >>> a[1][1]=2
- >>> a
- [[0, 0, 0], [0, 2, 0], [0, 0, 0]]
- >>> b=[[0]*3]*3
- >>> b
- [[0, 0, 0], [0, 0, 0], [0, 0, 0]]
- >>> b[1][1]=2
- >>> b
- [[0, 2, 0], [0, 2, 0], [0, 2, 0]]
列表推导式后还可加 if 条件限制:
- >>> y=[i+1 for i in range(10) if i%2==0]
- >>> y
- [1, 3, 5, 7, 9]
这个列表推导式的运行顺序是:
(1)for i in range(10)
(2)if i%2==0
(3)i+1
2,嵌套的列表推导式
根据列表推导式的运行顺序可推出嵌套列表推导式
- >>> a=[[1,2,3],[4,5,6],[7,8,9]]
- >>> b=[i*2 for j in a for i in j]
- >>> b
- [2, 4, 6, 8, 10, 12, 14, 16, 18]
元组
P27
1,元组:元素不可变,元组用的是圆括号。元组也可以省略括号,用逗号隔开就可以。
2,元组支持切片,
3,列表中有增删改查,到元组就只有了查,即count()和index()方法
4,没有元组推导式
5,生成只有一个元素的元组:需要有逗号
- >>> a=(520)
- >>> type(a)
- <class 'int'>
- >>> b=(520,)
- >>> type(b)
- <class 'tuple'>
6,元组的打包和解包,字符串、列表也可以打包和解包。
- >>> x=1
- >>> y=2
- >>> z=3
- >>> t=(x,y,z)
- >>> t
- (1, 2, 3)
- >>> (a,b,c)=t
- >>> a
- 1
- >>> b
- 2
- >>> c
- 3
- >>> a,b,c,d='hjdk'
- >>> a
- 'h'
- >>> c
- 'd'
解包时等号左侧的变量数个右侧元素数需相等,不相等时报错,可以在最后一个变量上加*来解决。
- >>> a,b,c="ahjjdk"
- Traceback (most recent call last):
- File "
" , line 1, in - ValueError: too many values to unpack (expected 3)
- >>> a,b,*c="ahjjdk"
- >>> a
- 'a'
- >>> b
- 'h'
- >>> c
- ['j', 'j', 'd', 'k']
7,元组元素不可变,当元组中的元素指向一个可以修改的列表时,这个元组元素列表中的元素可以改变
- >>> s=[1,2,3]
- >>> t=[5,6,7]
- >>> w=(s,t)
- >>> w
- ([1, 2, 3], [5, 6, 7])
- >>> w[0][1]=10
- >>> w
- ([1, 10, 3], [5, 6, 7])
字符串
P28、P29、P30、P31
1,判断字符串是否是回文字符串:
- >>> x='12321'
- >>> "是回文数" if x==x[::-1] else "不是回文数"
- '是回文数'
- >>> x='12345'
- >>> "是回文数" if x==x[::-1] else "不是回文数"
- '不是回文数'
2,字符串相关的众多方法:
(1)~(6)主要是大小写字母的变换。
(1)capitalize():返回首字母大写,其他字母小写的字符串
- >>> x="I love Hzq"
- >>> x.capitalize()
- 'I love hzq'
(2)casefold():返回所有字符都是小写的字符串
- >>> x="I love Hzq"
- >>> x.casefold()
- 'i love hzq
(3)title():返回每个单词的首字母都变成大写,剩下的字母变成小写
- >>> x="I love Hzq"
- >>> x.title()
- 'I Love Hzq'
(4)swapcase():所有字母大小写反转
- >>> x="I love Hzq"
- >>> x.swapcase()
- 'i LOVE hZQ'
(5)upper():全部大写
(6)lower():全部小写,只能处理英语,casefold()不仅英语,还可以其他语言
(7)~(10)左中右对齐
(7)center(width , fillchar = ''):width如果比原字符串小,则直接原字符串输出,如果比原字符串大,则宽度保持width,不足的部分用空格填充,字符串居中;不设置fillchar时默认空格填充,设置后以设置的fillchar填充。
(8)ljust(width , fillchar = ''):左对齐,其余同上
(9)rjust(width , fillchar = ''):右对齐,其余同上
(10)zfill(width):字符串靠右,0填充左侧;也适合负数情况,负数时,负号会被移到最左侧。
- >>> x="I love Hzq"
- >>> x.center(15)
- ' I love Hzq '
- >>> x.center(15,'_')
- '___I love Hzq__'
- >>> x.ljust(16)
- 'I love Hzq '
- >>> x.rjust(16)
- ' I love Hzq'
- >>> x.zfill(16)
- '000000I love Hzq'
(11)~(15)查找
(11)count(x,start,end):包括索引为star的元素,不包括索引为end的元素
(12)find(x,start,end):从左往右找,返回第一个找的的元素的索引,找不到的话返回-1
(13)rfind(x,start,end):从右往左找,返回第一个找的的元素的索引,找不到的话返回-1
(14)index(x,start,end):和find()类似,找不到不到字符串时,报错
(15)rindex(x,start,end):和rfind()类似,找不到不到字符串时,报错
(16)~(18)替换
(16)expandtabs([tabsize=8]):将字符串中的tab替换为空格,返回字符串,参数代表一个tab代表多少个空格

(17)replace(old,new,count=-1):将字符串中的old替换为new,count为替换的个数,默认为全部。
- >>> a="yuuiijhgfb"
- >>> a.replace('u','U')
- 'yUUiijhgfb'
- >>> a.replace('u','U',5)
- 'yUUiijhgfb'
(18)translate(table):table代表的是一个映射关系,即将原字符串按照table进行映射,并返回映射后的字符串。
- >>> a="I love Hzq"
- >>> table=str.maketrans("abcdefg","1234567")
- >>> a.translate(table)
- 'I lov5 Hzq'
- // str.maketrans("abcdefg","1234567") 表示创建一个映射关系,
- //该函数还支持第三个参数 str.maketrans("abcdefg","1234567","str"),表示将 str 忽略掉(删掉)。
(19)~(33)表示对字符串的判断
(19)startswith(x,start,end):判断指定字符串是否在待判断字符串的起始位置,x可以是一个元组,将多个待匹配的字符串写进去,若有一个匹配成功,即返回True
(20)endswith(x,start,end):判断指定字符串是否在待判断字符串的结束位置,x可以是一个元组,将多个待匹配的字符串写进去,若有一个匹配成功,即返回True
- >>> a="我爱python"
- >>> a.startswith(('我','你','她'))
- True
(21)isupper():全大写字母,返回True
(22)islower():全小写字母,返回True
(23)istitle():所有单词以大写字母开头,其余小写,返回True
(24)isalpha():判断是否全以字母构成
(25)isascii():如果字符串中的所有字符都是ASCII字符(即字符的Unicode码点在0到127之间),则返回
True,否则返回False。(26)isspace():判断是否是空白字符串,空白包括:空格、Tab、\n、
- >>> ' \n'.isspace()
- True
(27)isprintable():判断字符串是否是可打印的,其中 转义字符、空格 不是可打印字符
- >>> ' \n'.isprintable()
- False
- >>> ' '.isprintable()
- False
- >>> ' love '.isprintable()
- False
- >>> 'love'.isprintable()
- True
(28)isdecimal():判断数字,能力最弱
(29)isdigit(): 判断数字,能力居中,可判断(
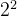 )
)(30)isnumeric():判断数字,能力最强,可判断(ⅠⅡⅢ...和一二三...)
(31)isalnum(): 判断数字,能力第一,上述三个一个为True,这个就为True
(32)isidentifier():判断字符串是否是python的合法标识符(空格不合法,下划线合法;数字开头的字符串不合法)
- >>> 'I love'.isidentifier()
- False
- >>> 'I_love'.isidentifier()
- True
- >>> 'love520'.isidentifier()
- True
- >>> '520love'.isidentifier()
- False
(33)keyword模块中的iskeyword(str)函数:判断是否是关键字
- >>> import keyword
- >>> keyword.iskeyword('if')
- True
- >>> keyword.iskeyword('py')
- False
(34)~(38)字符串截取
(34)strip(char=None):删掉字符串左边和右边的指定字符,默认为空格
(35)lstrip(char=None):删掉字符串左边的指定字符,默认为空格
(36)rstrip(char=None):删掉字符串右边的指定字符,默认为空格
- >>> ' I love '.lstrip()
- 'I love '
- >>> ' I love '.rstrip()
- ' I love'
- >>> 'www.Iloveyou.com'.lstrip('w.I')
- 'loveyou.com'
- >>> 'www.Iloveyou.com'.rstrip('.mo')
- 'www.Iloveyou.c'
- >>> 'www.Iloveyou.com '.rstrip(' .mo')
- 'www.Iloveyou.c'
- >>> 'www.Iloveyou.com '.rstrip('.mo')
- 'www.Iloveyou.com '
(37)removeprefix(prefix):删除前缀(整体)
(38)removesuffix(suffix):删除后缀(整体)
- >>> 'www.Iloveyou.com'.removeprefix('www.')
- 'Iloveyou.com'
- >>> 'www.Iloveyou.com'.removesuffix('.com')
- 'www.Iloveyou'
- >>> 'www.Iloveyou.com '.removesuffix('.com')//原字符串在.com后加了一个空格
- 'www.Iloveyou.com '
(39)~()字符串拆分、拼接
(39)partition(sep):从左到右找一个sep字符串,以sep为界,返回元组('左'、'sep'、'右')
(40)rpartition(sep):从右到左找一个sep字符串,以sep为界,返回元组('左'、'sep'、'右')
- >>> 'www.Iloveyou.com '.partition('.')
- ('www', '.', 'Iloveyou.com ')
- >>> 'www.Iloveyou.com '.rpartition('.')
- ('www.Iloveyou', '.', 'com ')
(41)split(sep=None,maxsplit=-1):从左到右找到maxsplit个sep,默认为全部,并以此分割成若干字符串元素的列表,分界处的sep删去
(42)rsplit(sep=None,maxsplit=-1):从右到左找到maxsplit个sep,默认为全部,并以此分割成若干字符串元素的列表,分界处的sep删去
(43)splitlines():以行进行分割,换行符可以是\n、\r、\r\n ,括号中写True时,换行符写进前一个元素中。
(44)join(iterable):字符串拼接,join拼接比加号拼接快,大量需要拼接时,join节省大量时间。
- >>> '.'.join(['www','Iloveyou','com'])
- 'www.Iloveyou.com'
- >>> '.'.join(('www','Iloveyou','com'))
- 'www.Iloveyou.com'
P32、P33
1,格式化字符串format()函数
- >>> "love you {} years".format(num) //位置索引
- 'love you 10000 years'
- >>> '{}看到{}很激动'.format('我','你') //位置索引
- '我看到你很激动'
- >>> '{1}看到{0}很激动'.format('我','你') //位置索引
- '你看到我很激动'
- >>> '{1}看到{1}很激动'.format('我','你') //位置索引
- '你看到你很激动'
- >>> '{a}看到{b}很激动'.format(a='我',b='你') //关键字索引
- '我看到你很激动'
- >>> '{0}看到{b}很激动'.format('我',b='你') //关键字索引和位置索引杂交
- '我看到你很激动'
2,在字符串中显示花括号
- >>> '{},{},{}'.format(1,'{}',2)
- '1,{},2'
- >>> '{},{{}},{}'.format(1,2)
- '1,{},2'
3,格式化字符串

- >>> '{:^}'.format(250)
- '250'
- >>> '{:^10}'.format(250)
- ' 250 '
- >>> '{1:>10}{0:<10}'.format(520,250)
- ' 250520 '
- >>> '{left:>10}{right:<10}'.format(left=520,right=250)
- ' 520250 '
- >>> '{:010}'.format(520)
- '0000000520'
- >>> '{:010}'.format(-520)
- '-000000520'
- >>> '{1:%>10}{0:%<10}'.format(520,250)
- '%%%%%%%250520%%%%%%%'
- >>> '{:0=10}'.format(520)
- '0000000520'
- >>> '{:0=10}'.format(-520)
- '-000000520'
- >>> '{:=10}'.format(-520)
- '- 520'

- >>> '{:+}{:-}'.format(520,-250)
- '+520-250'
- >>> '{:,}'.format(12345)
- '12,345'
- >>> '{:.2f}'.format(3.14159)
- '3.14'
- >>> '{:.2g}'.format(3.14159)
- '3.1'
- >>> '{:.6}'.format('I love you')
- 'I love'

- >>> '{:b}'.format(80)
- '1010000'
- >>> '{:c}'.format(80)
- 'P'
- >>> '{:d}'.format(80)
- '80'
- >>> '{:o}'.format(80)
- '120'
- >>> '{:x}'.format(80)
- '50'
- >>> '{:#b}'.format(80)
- '0b1010000'
- >>> '{:#c}'.format(80)
- Traceback (most recent call last):
- File "
" , line 1, in - ValueError: Alternate form (#) not allowed with integer format specifier 'c'
- >>> '{:#d}'.format(80)
- '80'
- >>> '{:#o}'.format(80)
- '0o120'
- >>> '{:#x}'.format(80)
- '0x50'
适用于浮点数、复数:

- >>> '{:e}'.format(3.14159)
- '3.141590e+00'
- >>> '{:E}'.format(3.14159)
- '3.141590E+00'
- >>> '{:f}'.format(3.14159)
- '3.141590'
- >>> '{:g}'.format(123456789)
- '1.23457e+08'
- >>> '{:g}'.format(123.456789)
- '123.457'
- >>> '{:%}'.format(0.98)
- '98.000000%'
- >>> '{:.2%}'.format(0.98)
- '98.00%'
- >>> '{:.{prec}f}'.format(3.1415,prec=2)
- '3.14'
3,f-字符串:代替format()函数,python3.6以后的版本才能用
- >>> F"I love you {num} year"
- 'I love you 10000 year'
- >>> F"{-520:010}"
- '-000000520'
所有的格式化都可以用F-字符串代替format()函数
序列
P34
1,列表是可变序列,元组和字符串是不可变序列。
2,id(x):返回x的id号,
3,每个对象都有三个特征:
(1)唯一标志:标签->id(x)函数获取
(2)类型
(3)值
4,
(1)对于列表,对其中元素赋值,不会改变其id,对整个列表赋值,会改变id。
例外:a*=2前后a的id相同。
- >>> a=[1,2,3]
- >>> id(a)
- 1905786440512
- >>> a=[4,5,6]
- >>> id(a)
- 1905786440768
- >>> a[1]=[4,5,6]
- >>> id(a)
- 1905786440768
(2)对于元组,只能整体赋值,赋值后id就会改变
5, is、is not,同一性运算符,判断id是否相同。
- >>> a=[1,2,3]
- >>> b=[1,2,3]
- >>> c=(1,2,3)
- >>> d=(1,2,3)
- >>> e='qwe'
- >>> f='qwe'
- >>> a is b
- False
- >>> c is d
- False
- >>> e is f
- True
6, in、not in,判断包含问题
- >>> 'love' in 'I love you'
- True
- >>> 'e' in 'I love you'
- True
- >>> 'e' not in 'I love you'
- False
7,del,删除序列,也可以删除可变序列中的指定元素
- >>> x=[1,2,3]
- >>> del x
- >>> x
- Traceback (most recent call last):
- File "
" , line 1, in - NameError: name 'x' is not defined
- >>> y=[1,2,3]
- >>> del y[1:]
- >>> y
- [1]
P35
1,列表,元组,字符串相互转换的函数
(1)list()
(2)tuple()
(3)str()
- >>> list('qwer')
- ['q', 'w', 'e', 'r']
- >>> list((1,2,3))
- [1, 2, 3]
- >>> tuple([1,2,3])
- (1, 2, 3)
- >>> tuple('qwer')
- ('q', 'w', 'e', 'r')
- >>> str([1,2,3,4,5])
- '[1, 2, 3, 4, 5]'
- >>> str((1,2,3,4,5,6))
- '(1, 2, 3, 4, 5, 6)'
2,求最大最小值函数
(1)min()
(2)max()
若是字符串,则判断每个元素的编码值。若待判断的序列为空,则抛出异常,可传入参数进行避免抛出异常。
- >>> min([])
- Traceback (most recent call last):
- File "
" , line 1, in - ValueError: min() arg is an empty sequence
- >>> min([],default='序列中什么有没有')
- '序列中什么有没有'
3,len()和sum()
(1)len():参数有最大可承受范围((2**31-1)或(2**63-1))
(2)sum(x,[start=num]):可传入可选参数,从start开始加。
- >>> len(range(10))
- 10
- >>> sum([1,2,3,4,5])
- 15
- >>> sum([1,2,3,4,5],start=100)
4,sorted() 和 reversed()
(1)sorted():排序,可以有key函数,表示干预排序的函数 ;sort()方法只能排序列表,sorted()函数能传进去的参数可以是列表,元组和字符串,但返回结果都是列表。
- >>> s=[1,2,3,0,6]
- >>> sorted(s)
- [0, 1, 2, 3, 6]
- >>> sorted(s,reverse=True)
- [6, 3, 2, 1, 0]
- >>> t=['FishC','Banana','Book','Pen','Apple']
- >>> sorted(t)
- ['Apple', 'Banana', 'Book', 'FishC', 'Pen']
- >>> sorted(t,key=len)
- ['Pen', 'Book', 'FishC', 'Apple', 'Banana']
(2)reversed():得到与输入序列反向的迭代器
- s=[1,2,5,8,0]
- >>> reversed(s)
object at 0x000001BBB9766CD0> - >>> list(reversed(s))
- [0, 8, 5, 2, 1]
- >>> a=(1,2,5,8,0)
- >>> list(reversed(a))
- [0, 8, 5, 2, 1]
P36
1,all()和any()
(1)all():判断可迭代对象中是否所有元素都为真
(2)any():判断可迭代对象中是否有为真的元素
2,enumerate()函数:用于返回一个枚举对象,它的功能就是将可迭代对象中的每个元素及从 0开始的序号共同构成一个二元组的列表;
- >>> seasons=['Spring','Summer','Fall','Winter']
- >>> enumerate(seasons)
- <enumerate object at 0x000001BBB9BA1440>
- >>> list(enumerate(seasons))
- [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
可以有start参数,用来自定义序号开始的值。
- >>> list(enumerate(seasons,10))
- [(10, 'Spring'), (11, 'Summer'), (12, 'Fall'), (13, 'Winter')]
3,zip()
zip()函数用于创建一个聚合多个可迭代对象的迭代器。它会将作为参数传入的每个可迭代对象的每个元素依次组合成元组,即第i个元组包含来自每个参数的第i个元素。
- >>> x=[1,2,3]
- >>> y=[4,5,6]
- >>> zip(x,y)
- <zip object at 0x000001BBB9BA17C0>
- >>> list(zip(x,y))
- [(1, 4), (2, 5), (3, 6)]
- >>> z=[7,8,9]
- >>> list(zip(x,y,z))
- [(1, 4, 7), (2, 5, 8), (3, 6, 9)]
传入不同迭代对象长度不一致时:以最短的为准
- >>> z=[7,8,9,10]
- >>> list(zip(x,y,z))
- [(1, 4, 7), (2, 5, 8), (3, 6, 9)]
*用itertools模块中的zip_longest()来代替zip()时:传入不同迭代对象长度不一致时,以最长的为准,短的补None
- >>> import itertools
- >>> zipped=itertools.zip_longest(x,y,z)
- >>> list(zipped)
- [(1, 4, 7), (2, 5, 8), (3, 6, 9), (None, None, 10)]
4,map():第一个参数为函数,用于处理后面参数中的可迭代对象。
map()函数会根据提供的函数对指定的可迭代对象的每个元素进行运算,并将返回运算结果的迭代器。
- >>> mapped=map(ord,'FishC') //ord()函数只需要一个参数
- >>> list(mapped)
- [70, 105, 115, 104, 67]
- >>> mapped=map(pow,[2,3,10],[5,4,3]) //pow()函数需要两个参数
- >>> list(mapped)
- [32, 81, 1000]
- >>> mapped=map(max,[1,2,3],[2,5,3],[9,1,5,4,3]) //参数长度不一致时,以短的为准
- >>> list(mapped)
- [9, 5, 5]
5,filter()函数
filter()函数会根据提供的函数对指定的可迭代对象的每个元素进行运算,并将运算结果为真的元素,以迭代器的形式返回。
- >>> list(filter(str.islower,"Love Hzq"))
- ['o', 'v', 'e', 'z', 'q']
6,迭代器和可迭代对象的关系
(1)一个迭代器一定是一个可迭代对象
(2)可迭代对象可以重复利用,迭代器是一次性的
- >>> mapped=map(ord,"FishC")
- >>> for each in mapped:
- ... print(each)
- ...
- 70
- 105
- 115
- 104
- 67
- >>> list(mapped)
- []
7,
(1) iter():传入可迭代对象,返回对应的迭代器
- >>> x=[1,2,3,4,5]
- >>> y=iter(x)
- >>> type(x)
- <class 'list'>
- >>> type(y)
- <class 'list_iterator'>
(2) next():逐个将迭代器中的元素提取出来
- >>> next(y)
- 1
- >>> next(y)
- 2
- >>> next(y)
- 3
- >>> next(y)
- 4
- >>> next(y)
- 5
- >>> next(y)
- Traceback (most recent call last):
- File "
" , line 1, in - StopIteration
传入第二个参数,可防止迭代器为空时next()报错,
- >>> x=[1,2,3,4,5]
- >>> y=iter(x)
- >>> next(y,"没了")
- 1
- >>> next(y,"没了")
- 2
- >>> next(y,"没了")
- 3
- >>> next(y,"没了")
- 4
- >>> next(y,"没了")
- 5
- >>> next(y,"没了")
- '没了'
字典
P37
字典:python中唯一实现映射关系的内置类型。在python3.7及之前,字典中的元素是无序的,3.8之后有序。
P38、P39
1,
- >>> y={'1':'one','2':'two','3':'three'}
- >>> type(y)
- <class 'dict'>
- >>> y['1'] //写字典的键,就可以得到字典的值
- 'one'
- >>> y['4']='four' //对与字典中没有的键值对,可如此直接加入字典
- >>> y
- {'1': 'one', '2': 'two', '3': 'three', '4': 'four'}
2,创建字典的方法
- >>> a={'1':'one','2':'two','3':'three'}
- >>> b=dict(yi='one',er='two',san='three') //此方法键不加引号,键是数字时不能用此方法
- >>> c=dict([('1','one'),('2','two'),('3','three')])
- >>> d=dict({'1':'one','2':'two','3':'three'})
- >>> e=dict({'1':'one','2':'two'},san='three')
- >>> f=dict(zip(['1','2','3'],['one','two','three']))
- >>> a
- {'1': 'one', '2': 'two', '3': 'three'}
- >>> b
- {'yi': 'one', 'er': 'two', 'san': 'three'}
- >>> c
- {'1': 'one', '2': 'two', '3': 'three'}
- >>> d
- {'1': 'one', '2': 'two', '3': 'three'}
- >>> e
- {'1': 'one', '2': 'two', 'san': 'three'}
- >>> f
- {'1': 'one', '2': 'two', '3': 'three'}
3,字典的增删改查方法
增:
(1)fromkeys(iterable[,value]):可以使用iterable参数指定的可迭代对象来创建一个新的字典,并将所有的值初始化为values参数指定的值。
- >>> d=dict.fromkeys('Fish',25)
- >>> d
- {'F': 25, 'i': 25, 's': 25, 'h': 25}
- >>> x=dict.fromkeys('Fish')
- >>> x
- {'F': None, 'i': None, 's': None, 'h': None}
- >>> d['F']=30 //改字典中键的值
- >>> d
- {'F': 30, 'i': 25, 's': 25, 'h': 25}
- >>> d['C']=40 //增加字典中的元素
- >>> d
- {'F': 30, 'i': 25, 's': 25, 'h': 25, 'C': 40}
删:
(2)pop(key[,default]):删除字典中的键值对,返回的是键所对应的值,若字典中没有所传入的key,则抛出异常,添加参数可避免抛出异常。
- >>> d
- {'F': 30, 'i': 25, 's': 25, 'h': 25, 'C': 40}
- >>> d.pop('s')
- 25
- >>> d
- {'F': 30, 'i': 25, 'h': 25, 'C': 40}
- >>> d.pop('A')
- Traceback (most recent call last):
- File "
" , line 1, in - KeyError: 'A'
- >>> d.pop('A','字典中没有该键')
- '字典中没有该键'
(3)popitem():python3.7之前为随机删除一个键值对,python3.8及之后为删除最后加入的一个键值对。返回删除的键值对。
- >>> d
- {'F': 30, 'i': 25, 'h': 25, 'C': 40}
- >>> d.popitem()
- ('C', 40)
- >>> d
- {'F': 30, 'i': 25, 'h': 25}
(4)del :删除字典中的键值对或整个字典。
- >>> d
- {'F': 30, 'i': 25, 'h': 25}
- >>> del d['h']
- >>> d
- {'F': 30, 'i': 25}
- >>> del d
- >>> d
- Traceback (most recent call last):
- File "
" , line 1, in - NameError: name 'd' is not defined
(5)clear():清空字典
- >>> d=dict.fromkeys('Fish',25)
- >>> d
- {'F': 25, 'i': 25, 's': 25, 'h': 25}
- >>> d.clear()
- >>> d
- {}
改:
(6)update():修改字典中的某些键值
- >>> d=dict.fromkeys('Fish',25)
- >>> d
- {'F': 25, 'i': 25, 's': 25, 'h': 25}
- >>> d.update({'i':'103','h':'104'})
- >>> d
- {'F': 25, 'i': '103', 's': 25, 'h': '104'}
- >>> d.update(F='201',s='302')
- >>> d
- {'F': '201', 'i': '103', 's': '302', 'h': '104'}
查:
(7)get(key[,default]):当传入的键字典中没有时,没加default参数时无返回值,字典不改变,有default参数时打印default
- >>> d=dict.fromkeys('Fish',25)
- >>> d
- {'F': 25, 'i': 25, 's': 25, 'h': 25}
- >>> d['F']
- 25
- >>> d['f']
- Traceback (most recent call last):
- File "
" , line 1, in - KeyError: 'f'
- >>> d.get('F')
- 25
- >>> d.get('a')
- >>> d.get('a','字典中没有这个键')
- '字典中没有这个键'
(8)setdefault(key[,default]):若输入键值字典中有,则返回键对应的值,若输入键字典中没有,则添加此键和(值default或None)组成的键值对。
- >>> d=dict.fromkeys('Fish',25)
- >>> d
- {'F': 25, 'i': 25, 's': 25, 'h': 25}
- >>> d.setdefault('F',38)
- 25
- >>> d.setdefault('f',38)
- 38
- >>> d
- {'F': 25, 'i': 25, 's': 25, 'h': 25, 'f': 38}
- >>> d.setdefault('g')
- >>> d
- {'F': 25, 'i': 25, 's': 25, 'h': 25, 'f': 38, 'g': None}
(9)items():获取字典的键值对的的视图对象(视图对象:随字典的变化实时变化)
(10)keys():获取字典的键的视图对象
(11)values():获取字典的值的视图对象
- >>> d=dict.fromkeys('Fish',25)
- >>> a=d.items()
- >>> b=d.keys()
- >>> c=d.values()
- >>> a
- dict_items([('F', 25), ('i', 25), ('s', 25), ('h', 25)])
- >>> b
- dict_keys(['F', 'i', 's', 'h'])
- >>> c
- dict_values([25, 25, 25, 25])
- >>> d['f']=38
- >>> a
- dict_items([('F', 25), ('i', 25), ('s', 25), ('h', 25), ('f', 38)])
- >>> b
- dict_keys(['F', 'i', 's', 'h', 'f'])
- >>> c
- dict_values([25, 25, 25, 25, 38])
(12)copy()方法,实现浅拷贝
(13)len(x)方法,获取键值对的数量
(14)in、not in :判断键是否在字典中
(15)list(x):字典键转化为列表,
(16)list(x.values):字典值转化为列表
(17)iter(x):返回字典的键转化为的迭代器
(18)
字典与字典的嵌套、字典与列表的嵌套
- >>> d={'吕布':{'语文':60,'数学':70,'英语':80},'关羽':{'语文':80,'数学':90,'英语':70}}
- >>> d['吕布']['语文']
- 60
- >>> d={'吕布':[60,70,80],'关羽':[80,90,70]}
- >>> d['吕布'][1]
- 70
(19)字典推导式
- >>> d={'F':70,'i':105,'s':115,'h':104,'C':67}
- >>> b={v:k for k,v in d.items()} //交换键值位置
- >>> b
- {70: 'F', 105: 'i', 115: 's', 104: 'h', 67: 'C'}
- >>> b={v:k for k,v in d.items() if v>100} //带条件筛选
- >>> b
- {105: 'i', 115: 's', 104: 'h'}
- >>> d={x:ord(x) for x in 'FishC'} //求字符编码
- >>> d
- {'F': 70, 'i': 105, 's': 115, 'h': 104, 'C': 67}
- >>> d={x:y for x in [1,3,5] for y in [2,4,6]} //嵌套的字典推导式
- >>> d
- {1: 6, 3: 6, 5: 6}
集合
P40
集合是无序的;集合(set)
集合中每个元素都是唯一的,可以实现去重的效果;
集合无序,不能用下标索引,可以用 in、not in 判断元素是否在集合中;
集合是可迭代的对象。
1,集合推导式- >>> {s for s in 'FishC'}
- {'C', 'F', 's', 'h', 'i'}
2,集合中的方法,既适用于set()创建的可变集合,又适用于frozenset()创建的不可变集合。因为以下方法并不对原集合做改变,而是返回一个新的集合

(1)copy()方法,浅拷贝
(2)isdisjoint(other):判断集合是否有交集
- >>> s=set('FishC')
- >>> s
- {'C', 'F', 's', 'h', 'i'}
- >>> s.isdisjoint(set('Python'))
- False
- >>> s.isdisjoint(set('JAVA'))
- True
- >>> s.isdisjoint('JAVA') //可以不加set()转化函数
- True
- >>> s.isdisjoint('Python') //可以不加set()转化函数
(3)issubset(other):判断是否是other的子集
- >>> s
- {'C', 'F', 's', 'h', 'i'}
- >>> s.issubset('FishC.com.cn')
- True
(4)issuperset():判断是否是other的超集
- >>> s
- {'C', 'F', 's', 'h', 'i'}
- >>> s.issuperset('Fi')
- True
(5)union(other1[,other2...]):求并集,(可以多参数)
- >>> s
- {'C', 'F', 's', 'h', 'i'}
- >>> s.union('1,2,3')
- {'C', '2', 's', '3', ',', 'i', 'F', 'h', '1'}
(6)intersection(other1[,other2...]):求交集,(可以多参数)
- >>> s
- {'C', 'F', 's', 'h', 'i'}
- >>> s.intersection('1,2,3ihk')
- {'i', 'h'}
(7)difference(other1[,other2...]):求差集,即存在于当前集合但不存在于other的元素,(可以多参数)
- >>> s
- {'C', 'F', 's', 'h', 'i'}
- >>> s.difference('1,2,3ihk')
- {'C', 'F', 's'}
(8)symmetric_difference(other):求对称差集,排除当前集合和other集合中共有的元素之后剩余的所有元素。(不能多参数,只支持一个参数)
- >>> s
- {'C', 'F', 's', 'h', 'i'}
- >>> s.symmetric_difference('1,2,3ihk')
- {'C', '2', 'F', 's', '3', '1', 'k', ','}
(9)集合的运算可以直接用符号,符号两边必须都是集合形式(上面的用方法运算右侧可以是任何可迭代对象): 子集(<=),真子集(<),超级(>=),真超集(>);并集(|)、交集(&)、差集(-)、对称差集(^)
P41
set()创建的集合可变;frozenset()创建的集合不可变
1,只适用于set()的方法,直接更改原集合中的内容:
(1)update(*others):向原集合中添加others,
(2)intersection_update(*others):将原集合更新为原集合与other的交集
(3)difference_update(*others):将原集合更新为原籍和与others的差集
(4)symmetric_difference_update(*others):将原集合更新为原集合与others的对称差集
(5)add()方法,用update向集合中添加字符串时,是将字符串的每个元素分开添加的,而add是整个字符串作为一个元素添加的。
(6)remove():删除集合中的元素,若没有在集合中找到元素,抛出异常
(7)discard():删除集合中的元素,若没有在集合中找到元素,抛出静默处理
(8)pop():随机弹出一个元素
(9)clear():清空集合
2,
(1)可哈希:不可变的对象是可哈希的,如字符串,元组
不可哈希:可变的对象是不可哈希的,
只有可哈希的对象才能作为字典的键;只有可哈希的对象才能作为集合中的元素。
(2)set()集合不可以嵌套,因为set()集合是可变的,可变的对象不能作为集合的元素。
frozenset()集合可以嵌套
函数
P42
函数
1,基本形式
- >>> def my_function():
- ... for i in range(3):
- ... print('I love Hzq')
- ...
- >>> my_function()
- I love Hzq
- I love Hzq
- I love Hzq
2,带一个参数的函数
- >>> def my_function(str):
- ... for i in range(3):
- ... print(f'I love {str}')
- ...
- >>> my_function('Python')
- I love Python
- I love Python
- I love Python
3,带两个参数的函数
- >>> def my_function(str,num):
- ... for i in range(num):
- ... print(f'I love {str}')
- ...
- >>> my_function('Python',5)
- I love Python
- I love Python
- I love Python
- I love Python
- I love Python
4,带返回值的函数
- >>> def div(x,y):
- ... z=x/y
- ... return z
- ...
- >>> div(2,4)
- 0.5
5,若函数不含返回值,则默认返回None
6,关键字参数:
- >>> def my_func(s,vt,o):
- ... return ''.join((o,vt,s))
- ...
- >>> my_func(o='我',vt='打了',s='小甲鱼')
- '我打了小甲鱼'
7,默认参数,在函数定义时,若使用默认参数,默认参数需要定义在参数列表的后面
- >>> def my_func(s,vt,o='小甲鱼'):
- ... return ''.join((o,vt,s))
- ...
- >>> my_func('我','打了')
- '小甲鱼打了我'
- >>> my_func('我','打了','老王八')
- '老王八打了我'
8,参数列表中的 * 和 / ,在函数定义中,参数列表中放一个 / ,表示在 / 的左侧只能是位置参数,不能说关键字参数;参数列表中放一个 * ,表示在 * 的右侧只能说关键字参数,不能是位置参数。
- >>> def abc(a,/,b,c):
- ... print(a,b,c)
- ...
- >>> abc(1,2,c=3)
- 1 2 3
- >>> abc(a=1,b=2,c=3)
- Traceback (most recent call last):
- File "
" , line 1, in - TypeError: abc() got some positional-only arguments passed as keyword arguments: 'a'
- >>> def abc(a,*,b,c):
- ... print(a,b,c)
- ...
- >>> abc(1,b=2,c=3)
- 1 2 3
- >>> abc(1,2,c=3)
- Traceback (most recent call last):
- File "
" , line 1, in - TypeError: abc() takes 1 positional argument but 2 positional arguments (and 1 keyword-only argument) were given
P44
1,收集参数,可以传入一个或多个参数,形式是在形参前加一个*,收集参数是以元组的形式存储的,pirnt的参数就是收集参数,return后加返回值,也可以返回多个值,也是以元组形式存储的,因为元组具有打包解包的能力。
- >>> print('Hzq')
- Hzq
- >>> print('Hzq','Thy')
- Hzq Thy
- >>> def myfunc(*args):
- ... print(f'有{len(args)}个参数')
- ... print(f'第二个参数是{args[1]}')
- ...
- >>> myfunc('Hzq','Thy','Hhh')
- 有3个参数
- 第二个参数是Thy
- >>> def myfunc(*args):
- ... print(args)
- ...
- >>> myfunc('Hzq','Thy','Hhh')
- ('Hzq', 'Thy', 'Hhh') //元组形式存储,元组具有打包解包的能力
2,如果在收集参数后还有其他参数,在调用函数是收集参数后的参数需要用关键字赋值方式调用。因为收集参数会将尽可能多的参数纳入收集参数,收集参数后的参数若不用关键字参数的形式赋值,将得不到传入的参数,会报错。
3,收集参数将参数打包成字典,要在形参前加**,
- >>> def myfunc(**kwargs):
- ... print(kwargs)
- ...
- >>> myfunc(a='Hzq',b='Thy',c='Hhh')
- {'a': 'Hzq', 'b': 'Thy', 'c': 'Hhh'}
- >>> def myfunc(a,*b,**c):
- ... print(a,b,c)
- ...
- >>> myfunc(1,2,3,4,5,x=1,y=2)
- 1 (2, 3, 4, 5) {'x': 1, 'y': 2}
4,解包
- >>> args=(1,2,3,4)
- >>> def myfunc(a,b,c,d):
- ... print(a,b,c,d)
- ...
- >>> myfunc(*args)
- 1 2 3 4
- >>> kwargs={'a':1,'b':2,'c':3,'d':4}
- >>> def myfunc(a,b,c,d):
- ... print(a,b,c,d)
- ...
- >>> myfunc(**kwargs)
- 1 2 3 4
P45
作用域
1,在局部作用域调用全局作用域的变量:global语句
- >>> x=888
- >>> def myfunc():
- ... global x
- ... x=520
- ... print(x)
- ...
- >>> myfunc()
- 520
- >>> x
- 520
2,嵌套函数中内层函数想要修改外部函数的变量,用nonlocal
- >>> def funA():
- ... x=520
- ... def funB():
- ... nonlocal x
- ... x=888
- ... print(f'In funB,x={x}')
- ... funB()
- ... print(f'In funA,x={x}')
- ...
- >>> funA()
- In funB,x=888
- In funA,x=888
3,

P46
闭包
闭包(Closure)是函数式编程中的一个重要概念,它指的是一个函数捕获并记住了它被创建时的外部环境中的变量,即使在该外部环境不再存在的情况下,这些变量仍然可以被访问和使用。在Python中,闭包通常由嵌套函数实现。
下面是一个简单的 Python 闭包的示例:
- >>> def outer_function(x):
- ... def inner_function(y):
- ... return x + y
- ... return inner_function
- ...
- >>> closure = outer_function(10)
- >>> result = closure(5)
- >>> result
- 15
在这个示例中,
outer_function是一个外部函数,它接受一个参数x,并返回了一个内部函数inner_function。inner_function捕获了外部函数的参数x,即使outer_function执行完毕后,x仍然可以在inner_function中访问和使用。闭包在许多情况下非常有用,例如在装饰器、回调函数和函数工厂中。它允许你在函数中保留状态,并实现更复杂的功能。
P47
1,延时函数
- >>> import time
- >>> time.sleep(2) //延时2秒
2,修饰器
装饰器,顾名思义,对函数进行装饰的一种操作,既然是对函数的装饰,那么就一定加入的就是一下装饰性的东西,一般为以下5种情况:
(1)日志记录:记录函数的调用时间、参数和返回值等信息。
(2)性能分析:测量函数的执行时间,帮助优化性能。
(3)权限检查:验证用户是否有权限执行某个操作。
(4)缓存:缓存函数的结果,避免重复计算。
(5)修改参数或返回值:对函数的参数或返回值进行修改。
以下为一个装饰器的实现例子:
- >>> def my_decorator(func):
- ... def wrapper():
- ... print("Something is happening before the function is called.")
- ... func()
- ... print("Something is happening after the function is called.")
- ... return wrapper
- ...
- >>> def say_hello():
- ... print("Hello!")
- ...
- >>> say_hello = my_decorator(say_hello)
- >>> say_hello()
- Something is happening before the function is called.
- Hello!
- Something is happening after the function is called.
使用装饰器语法糖形式是:
- >>> def my_decorator(func):
- ... def wrapper():
- ... print("Something is happening before the function is called.")
- ... func()
- ... print("Something is happening after the function is called.")
- ... return wrapper
- ...
- >>> @my_decorator
- ... def say_hello():
- ... print("Hello!")
- ...
- >>> say_hello()
- Something is happening before the function is called.
- Hello!
- Something is happening after the function is called.
3,语法糖
Python语法糖(Syntactic sugar)是一种编程语言设计中的概念,它指的是一种语法上的改进或扩展,使代码更易于编写和阅读,但不会引入新的功能。这些改进通常使代码更加简洁和直观。Python以其清晰的语法和丰富的语法糖而著名。
以下是一些Python中常见的语法糖:
(1)列表推导式(List Comprehensions):允许你用一行代码创建新的列表,而不需要显式的循环。
- >>> numbers = [1, 2, 3, 4, 5]
- >>> squared_numbers = [x**2 for x in numbers]
- >>> squared_numbers
- [1, 4, 9, 16, 25]
(2)字典推导式(Dictionary Comprehensions):类似于列表推导式,用于创建字典。
- >>> names = ["Alice", "Bob", "Charlie"]
- >>> name_lengths = {name: len(name) for name in names}
- >>> name_lengths
- {'Alice': 5, 'Bob': 3, 'Charlie': 7}
(3)with 语句:用于简化资源管理,如文件处理和数据库连接。(还不懂with语句)
- with open("file.txt", "r") as file:
- data = file.read()
- # 不再需要手动关闭文件
(4)@ 装饰器:用于在函数定义之前应用修饰器,以扩展函数的功能。
- >>> def my_decorator(func):
- ... def wrapper():
- ... print("Something is happening before the function is called.")
- ... func()
- ... print("Something is happening after the function is called.")
- ... return wrapper
- ...
- >>> @my_decorator
- ... def say_hello():
- ... print("Hello!")
- ...
- >>> say_hello()
- Something is happening before the function is called.
- Hello!
- Something is happening after the function is called.
(5)f-字符串(Formatted Strings):用于创建带有变量插值的字符串。
- >>> name = "Alice"
- >>> age = 30
- >>> greeting = f"Hello, {name}. You are {age} years old."
- >>> greeting
- 'Hello, Alice. You are 30 years old.'
这些语法糖使Python代码更加易读和简洁,同时保持了语言的可读性和可维护性。它们是Python编程语言的重要特征之一,使编写Python代码变得愉快和高效。
4,同时使用多个装饰器
在Python中,你可以同时使用多个装饰器来装饰一个函数。这允许你在一个函数上应用多个不同的增强或修改操作。装饰器的顺序很重要,它们的应用顺序是从上到下的,从内到外的。也就是说,距离函数最近的装饰器最先应用,最远的最后应用。
以下是一个示例,演示如何同时使用多个装饰器:
- >>> def decorator1(func):
- ... def wrapper(*args, **kwargs):
- ... print("Decorator 1: Something before the function is called.")
- ... result = func(*args, **kwargs)
- ... print("Decorator 1: Something after the function is called.")
- ... return result
- ... return wrapper
- ...
- >>> def decorator2(func):
- ... def wrapper(*args, **kwargs):
- ... print("Decorator 2: Something before the function is called.")
- ... result = func(*args, **kwargs)
- ... print("Decorator 2: Something after the function is called.")
- ... return result
- ... return wrapper
- ...
- >>> @decorator1
- ... @decorator2
- ... def my_function():
- ... print("My function is called.")
- ...
- >>> my_function()
- Decorator 1: Something before the function is called.
- Decorator 2: Something before the function is called.
- My function is called.
- Decorator 2: Something after the function is called.
- Decorator 1: Something after the function is called.
在这个示例中,
my_function上应用了两个装饰器:decorator1和decorator2。当my_function被调用时,它会按照装饰器的顺序执行。5,带参数的装饰器
带参数的装饰器允许你在应用装饰器时传递参数,以便自定义装饰器的行为。这可以用于更灵活地控制装饰器的行为,使其适应不同的情况。为了创建带参数的装饰器,你需要创建一个装饰器工厂函数,它返回一个实际的装饰器函数。
以下是一个示例,演示如何创建带参数的装饰器:
- >>> def repeat(n):
- ... def decorator(func):
- ... def wrapper(*args, **kwargs):
- ... for _ in range(n):
- ... result = func(*args, **kwargs)
- ... return result
- ... return wrapper
- ... return decorator
- ...
- >>> def greet(name):
- ... print(f"Hello, {name}!")
- ...
- >>> greet = repeat(3)(greet)
- >>> greet('Alice')
- Hello, Alice!
- Hello, Alice!
- Hello, Alice!
语法糖形式为:
- >>> def repeat(n):
- ... def decorator(func):
- ... def wrapper(*args, **kwargs):
- ... for _ in range(n):
- ... result = func(*args, **kwargs)
- ... return result
- ... return wrapper
- ... return decorator
- ...
- >>> @repeat(3)
- ... def greet(name):
- ... print(f"Hello, {name}!")
- ...
- >>> greet("Alice")
- Hello, Alice!
- Hello, Alice!
- Hello, Alice!
P48
lambda函数
Lambda函数,也称为匿名函数,是Python中一种轻量级的函数定义方式,通常用于编写简单的函数或表达式,它们可以在一行内定义,而不需要使用
def关键字来命名函数。Lambda函数通常用于传递给高阶函数(如map,filter,sorted等)或创建简单的函数对象。Lambda函数的一般语法如下:
lambda arguments: expressionarguments:这是lambda函数的参数列表,可以包含零个或多个参数。expression:这是一个表达式,lambda函数执行并返回这个表达式的结果。
以下是一些示例,展示了lambda函数的用法:
(1)使用lambda函数进行简单的加法操作:
- >>> add = lambda x, y: x + y
- >>> print(add(2, 3)) # 输出:5
- 5
(2)使用lambda函数作为排序的关键函数:
- >>> students = [
- ... {"name": "Alice", "age": 25},
- ... {"name": "Bob", "age": 22},
- ... {"name": "Charlie", "age": 28}
- ... ]
- >>>
- >>> # 按照年龄对学生列表进行排序
- >>> sorted_students = sorted(students, key=lambda student: student["age"])
- >>> print(sorted_students)
- [{'name': 'Bob', 'age': 22}, {'name': 'Alice', 'age': 25}, {'name': 'Charlie', 'age': 28}]
(3)使用lambda函数过滤列表中的偶数:
- >>> numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9]
- >>> even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
- >>> print(even_numbers) # 输出:[2, 4, 6, 8]
- [2, 4, 6, 8]
虽然lambda函数非常方便,但通常应该保持简短和简单,以便提高代码的可读性。对于更复杂的函数,尤其是需要多行代码或复杂逻辑的函数,通常建议使用普通的函数定义(使用
def关键字)。P49
1,生成器(Generator)是一种特殊的迭代器,它允许你在迭代中生成值而不需要一次性存储所有值在内存中。生成器可以用于处理大型数据集,而无需占用大量内存,因为它们按需生成数据,逐个产生值。
在Python中,生成器可以通过两种方式创建:使用生成器表达式或使用函数和
yield关键字来定义生成器函数。下面我们将介绍这两种方法:(1)生成器表达式:
生成器表达式类似于列表推导式,但它使用圆括号而不是方括号,并返回一个生成器对象。
- >>> generator = (x * 2 for x in range(5))
- >>> for value in generator:
- ... print(value)
- ...
- 0
- 2
- 4
- 6
- 8
(2)生成器函数:
生成器函数是通过定义函数,并在函数体中使用
yield关键字来生成值的方式创建的。当函数执行到yield语句时,它会产生一个值,并保留函数的状态,以便在下一次迭代时恢复执行。- >>> def my_generator():
- ... for i in range(5):
- ... yield i * 2
- ...
- >>> generator = my_generator()
- >>> for value in generator:
- ... print(value)
- ...
- 0
- 2
- 4
- 6
- 8
生成器非常有用,特别是在需要逐个处理大量数据或需要延迟计算值的情况下。它们可以提高程序的性能和内存效率。另外,Python中有内置的生成器函数如
range()和zip(),它们也返回生成器对象。2,生成器中的send()函数
send()是 Python 中用于与生成器协作的方法之一,它允许你向生成器发送数据,同时也可以接收生成器中yield语句产生的值。通常,send()用于在生成器内部控制生成器的状态和行为。要使用
send(),首先需要创建一个生成器函数,并在其中使用yield来暂停函数的执行,并等待外部通过send()方法向生成器发送数据。以下是一个简单的示例:- >>> def my_generator():
- ... for i in range(3):
- ... received = yield i
- ... if received is not None:
- ... print(f"Received: {received}")
- ...
- >>> gen = my_generator()
- >>> next(gen) # 启动生成器并执行到第一个 yield 语句
- 0
- >>>
- >>> print(gen.send("Hello")) # 向生成器发送数据并继续执行
- Received: Hello
- 1
- >>> print(gen.send("World")) # 向生成器发送更多数据并继续执行
- Received: World
- 2
在这个示例中,
my_generator是一个生成器函数,它通过yield语句生成数字并等待接收数据。在主程序中,我们首先使用next(gen)启动生成器并执行到第一个yield语句。然后,我们使用gen.send("Hello")向生成器发送数据,并接收生成器中yield语句生成的值。之后,我们再次使用gen.send("World")来与生成器互动。send()方法不仅可以发送数据给生成器,还可以用于控制生成器的状态,例如,可以用它来关闭生成器或在生成器中触发异常。要注意,当生成器已经完成时,继续使用send()会引发StopIteration异常。send()方法使得生成器可以实现更复杂的逻辑和状态管理,同时允许与生成器进行双向通信。但需要小心使用,确保生成器的状态和协作是正确的,以避免不必要的复杂性。P50
递归效率比迭代低。运行速度慢
P51
汉诺塔

P52
1,函数文档
查看函数文档的函数:help()
- >>> help(print)
- Help on built-in function print in module builtins:
- print(...)
- print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
- Prints the values to a stream, or to sys.stdout by default.
- Optional keyword arguments:
- file: a file-like object (stream); defaults to the current sys.stdout.
- sep: string inserted between values, default a space.
- end: string appended after the last value, default a newline.
- flush: whether to forcibly flush the stream.
函数文档(Function Documentation),通常称为文档字符串(Docstring),是一种用于解释和描述函数的文本信息,它通常包括函数的目的、参数、返回值以及使用示例等重要信息。良好的函数文档对于代码的可维护性和可理解性非常重要,因为它可以帮助其他开发人员或你自己更好地理解函数的作用和使用方法。
在Python中,函数文档通常位于函数定义的内部,并使用三重双引号
"""或三重单引号'''包裹起来。以下是一个示例函数文档的格式:- def my_function(param1, param2):
- """
- 这是函数的文档字符串。
- Args:
- param1: 描述参数1的说明
- param2: 描述参数2的说明
- Returns:
- 描述返回值的说明
- Example:
- 示例用法的描述
- """
- # 函数的实际代码
- return result
在这个示例中,函数文档包括了以下部分:
- 函数的目的和功能的简短描述。
- 参数说明,包括每个参数的名称和描述。
- 返回值说明,描述函数的返回值。
- 示例用法,展示如何使用函数。
编写好的函数文档可以通过
help()函数或在交互式解释器中使用help()命令来查看。例如:help(my_function)或者在交互式解释器中:
>>> my_function.__doc__编写良好的函数文档对于协作开发和代码维护非常有帮助,它可以使其他开发人员更容易理解和使用你的函数。同时,一些工具和IDE还可以自动生成文档,例如Sphinx和PyCharm。
2,类型注释
类型注释(Type Annotations)是一种在Python中用于为变量、函数参数和函数返回值指定类型信息的方法。类型注释并不会改变 Python 运行时的行为,但它们可以提供静态类型检查工具、IDE和其他开发工具关于代码的类型信息,从而提高代码的可读性和可维护性。
类型注释的主要方式是使用冒号
:,在变量名或函数参数后面指定其类型。以下是一些常见的类型注释示例:- name: str = "Alice"
- age: int = 30
- def greet(person: str) -> str:
- return f"Hello, {person}!"
在这个示例中,
name和age变量都带有类型注释,以说明它们的类型。greet函数的参数person和返回值都有类型注释。Python的类型注释是可选的,不会对代码的实际运行产生影响。但是,当使用类型注释时,你可以获得以下好处:
(1)代码可读性提高:类型注释提供了对变量和函数参数的类型的明确描述,让其他开发人员更容易理解代码。
(2)类型检查工具:可以使用静态类型检查工具,如
mypy,来检查代码中的类型错误和潜在问题。(3)IDE支持:类型注释有助于提供更好的IDE支持,例如代码自动完成和类型检查。
(4)文档生成:类型注释可以用于生成更好的文档,以帮助其他开发人员了解函数的参数和返回值的类型。
需要注意的是,Python的类型注释是可选的,因此你可以选择在哪些情况下使用它们。但对于大型项目和协作开发,使用类型注释通常是一个良好的实践,可以提高代码的可维护性和质量。
3,内省
指的是在运行时检查对象的类型、属性和方法,以获取关于对象本身的信息。
P53
1,reduce()函数
reduce()函数是 Python 内置的函数,位于functools模块中,用于对一个序列的元素依次执行某个函数,并累积结果。它的主要作用是将一个可迭代对象中的元素通过一个给定的函数依次累积计算,并返回最终的结果。reduce()函数的基本语法如下:functools.reduce(function, iterable, initializer=None)function:一个二元函数,接受两个参数,用于对序列中的元素进行累积计算。iterable:一个可迭代对象,包含要执行累积计算的元素。initializer:可选参数,用于指定初始累积值。如果提供了初始值,计算会从初始值开始;如果未提供初始值,则计算会从可迭代对象的第一个元素开始。
下面是一个简单的示例,演示如何使用
reduce()函数来计算列表中元素的累积乘积:- from functools import reduce
- numbers = [1, 2, 3, 4, 5]
- result = reduce(lambda x, y: x * y, numbers)
- print(result) # 输出:120
在这个示例中,
reduce()函数将传递给它的 lambda 函数应用于序列中的元素,依次计算累积乘积。初始累积值默认为第一个元素(1),然后依次执行 lambda 函数,得到最终结果 120。需要注意的是,
reduce()函数在 Python 3 中被移到了functools模块,因此需要导入该模块以使用reduce()函数。另外,reduce()在某些情况下可以用更简单的方式替代,因此在实际使用中要慎重考虑是否使用它。2,偏函数
偏函数(Partial Function)是一种函数式编程的概念,在Python中可以通过
functools.partial来实现。偏函数允许你固定函数的一个或多个参数,以创建一个新的函数,该新函数在调用时只需要提供剩余的参数。functools.partial函数的基本语法如下:functools.partial(function, *args, **kwargs)function:要偏函数化的函数。*args:要固定的位置参数。**kwargs:要固定的关键字参数。
以下是一个示例,演示如何使用偏函数创建一个新的函数,将原函数的某个参数固定:
- from functools import partial
- def power(base, exponent):
- return base ** exponent
- square = partial(power, exponent=2)
- cube = partial(power, exponent=3)
- print(square(4)) # 输出:16
- print(cube(2)) # 输出:8
在这个示例中,我们定义了一个
power函数,然后使用partial创建了两个新函数square和cube,分别将exponent参数固定为 2 和 3。这样,当我们调用square(4)时,实际上相当于调用power(4, 2),返回 16。偏函数非常有用,可以在需要多次调用具有相同参数的函数时,减少冗余的代码。它允许你在不修改原函数的情况下,为不同的使用情况创建新的函数。
3,偏函数和闭包的联系和区别
偏函数(Partial Function)和闭包(Closure)是两个不同的概念,它们用于不同的编程情境,但都涉及到函数的使用。
(1)偏函数
- 偏函数是一种用于创建新函数的技术,该新函数是原函数的一个特殊版本,通过固定部分参数值来减少函数的参数个数。
- 偏函数是一个高阶函数,它接受一个函数和一组参数,并返回一个新函数,这个新函数可以在调用时不提供已经固定的参数。
- 偏函数通常用于消除重复的代码,减少参数的传递和提高代码的可读性。
- from functools import partial
- def power(base, exponent):
- return base ** exponent
- square = partial(power, exponent=2)
(2)闭包
- 闭包是一种编程模式,它允许在函数内部嵌套函数,并且内部函数可以访问外部函数的变量。
- 闭包是函数和与其相关的引用环境的组合,内部函数可以“捕获”外部函数的变量,即使外部函数已经执行完毕。
- 闭包通常用于在函数内部维护状态,或者实现函数工厂。
- def outer_function(x):
- def inner_function(y):
- return x + y
- return inner_function
- add_five = outer_function(5)
在总结上述区别时,可以说偏函数是用于创建新函数,而闭包是一种编程模式,用于实现函数内部状态的保持。尽管它们都涉及函数的使用,但目的和用法有所不同。
4,wraps()函数
wraps()是 Python 中的一个装饰器函数,它通常与装饰器一起使用,用于保留被装饰函数的元信息,如函数名、文档字符串、参数列表等。这对于维护代码的可读性和调试非常重要,因为装饰器可能会修改原函数的行为。wraps()函数属于functools模块,它可以用来创建装饰器,确保被装饰的函数保持其原始的元信息。通常,wraps()装饰器会嵌套在你的自定义装饰器内部,以确保原函数的信息得以保留。以下是一个示例,演示如何使用
wraps()装饰器来保留被装饰函数的元信息:- from functools import wraps
- def my_decorator(func):
- @wraps(func)
- def wrapper(*args, **kwargs):
- """This is the wrapper function."""
- print(f"Calling {func.__name__}")
- return func(*args, **kwargs)
- return wrapper
- @my_decorator
- def my_function():
- """This is the original function."""
- print("Hello, World!")
- # 输出函数名和文档字符串
- print(my_function.__name__) # 自省输出:my_function
- print(my_function.__doc__) # 自省输出:This is the original function.
在这个示例中,
my_decorator是一个自定义装饰器,它使用wraps()来确保my_function保留了原始的函数名和文档字符串。如果不使用wraps(),my_function的元信息可能会被修改成wrapper函数的信息。wraps()的使用有助于在编写装饰器时保持代码的清晰和可维护,因为它可以确保装饰器不会无意中破坏原函数的元信息。永久存储
P54
永久存储

- >>> f = open("D:FishC.txt","w")
- >>> f.write("I love you.")
- 11
- >>> f.close()
open()函数

P55
pathlib--面向对象的文件系统路径
1,导入模块,从pathlib模块中单独导入Path,在使用Path时不需要再加上模块名。
>>> from pathlib import Path2,获取目录
(1)Path.cwd(),返回文件当前所在目录。
(2)Path.home(),返回用户的主目录。
- >>> from pathlib import Path
- >>> currentPath = Path.cwd()
- >>> homePath = Path.home()
- >>> print("文件当前所在目录:%s\n用户主目录:%s" %(currentPath, homePath))
- 文件当前所在目录:C:\Users\Administrator
- 用户主目录:C:\Users\Administrator
3,目录拼接
斜杠 / 操作符用于拼接路径,比如创建子路径。
- >>> from pathlib import Path
- >>> currentPath = Path.cwd()
- >>> newPath = currentPath / '123'
- >>> print("新目录为:%s" %(newPath))
- 新目录为:C:\Users\Administrator\123
4,文件,路径是否存在判断
(1)Path.is_dir(),判断路径是否是一个文件夹
- >>> from pathlib import Path
- >>> f = open('C:/Users/Administrator/FishC.txt',"w")
- >>> p = Path.cwd()
- >>> q = Path('C:/Users/Administrator/FishC.txt')
- >>> p
- WindowsPath('C:/Users/Administrator')
- >>> q
- WindowsPath('C:/Users/Administrator/FishC.txt')
- >>> p.is_dir()
- True
- >>> q.is_dir()
- False
(2)Path.is_file(),判断路径是否是一个文件
- >>> p.is_file()
- False
- >>> q.is_file()
- True
(3)Path.exists()
- >>> p.exists()
- True
- >>> q.exists()
- True
- >>> Path('p/123.txt').exists()
- False
5,获取文件及其路径信息
(1)name属性,Path.name 获取路径最后一字段
- >>> p.name
- 'Administrator'
- >>> q.name
- 'FishC.txt'
(2)stem属性,Path.stem 获取路径最后一级的文件名,若是文件夹路径则获取路径的最后一级文件夹名
- >>> p.stem
- 'Administrator'
- >>> q.stem
- 'FishC'
(3)suffix属性,Path.suffix 获取路径最后一级文件后缀,若最后一级是文件夹,则返回空字符串。
- >>> p.suffix
- ''
- >>> q.suffix
- '.txt'
(4)parent属性,Path.parent 返回文件所在文件夹的名字。即父级路径名
- >>> p.parent
- WindowsPath('C:/Users')
- >>> q.parent
- WindowsPath('C:/Users/Administrator')
(5)parents属性,Path.parents 获取逻辑祖先路径构成的序列,支持索引
- >>> q.parents
- >>> qs=q.parents
- >>> for each in qs:
- ... print(each)
- ...
- C:\Users\Administrator
- C:\Users
- C:\
- >>> qs[0]
- WindowsPath('C:/Users/Administrator')
- >>> qs[1]
- WindowsPath('C:/Users')
- >>> qs[2]
- WindowsPath('C:/')
(6)parts属性,Path.parts 将路径各个组件拆分成元组
- >>> q.parts
- ('C:\\', 'Users', 'Administrator', 'FishC.txt')
(7)stat属性,Path.stat 查询文件或文件夹信息
- >>> p.stat()
- os.stat_result(st_mode=16895, st_ino=2251799813686070, st_dev=2656065922, st_nlink=1, st_uid=0, st_gid=0, st_size=24576, st_atime=1698803335, st_mtime=1698803335, st_ctime=1631158526)
- >>> p.stat().st_size
- 24576
(8)resolve(),Path.resolve(),将相对路径转化为绝对路径
- >>> Path('./FishC.txt')
- WindowsPath('FishC.txt')
- >>> Path('./FishC.txt').resolve()
- WindowsPath('C:/Users/Administrator/FishC.txt')
(9)Path.iterdir(),返回 Path 目录文件夹下的所有文件,返回的是一个生成器类型。
- >>> pi = p.iterdir()
- >>> pi
object Path.iterdir at 0x00000208828CD890> - >>> for each in pi:
- ... print(each)
- ...
- C:\Users\Administrator\.anaconda_backup
- C:\Users\Administrator\.android
- C:\Users\Administrator\.astropy
- C:\Users\Administrator\.bash_history
6,创建,删除,修改,查找文件(夹)
(1)mkdir(),创建文件夹
- >>> n = p/"FishC"
- >>> n.mkdir()
- >>> m = p/"FishC/A/B/C"
- >>> m.mkdir(parents=True)
(2)replace(),a.replace(b) 用a文件取代b文件
(3)rmdir(),删除文件夹,必须是空文件夹才能删除;使用格式:b.rmdir()
(4)unlink(),删除文件;使用格式:a.unlink()
修改:
(5)rename(),给文件(夹)修改名字
- >>> n
- WindowsPath('C:/Users/Administrator/FishC/FishC.txt')
- >>> n.rename("C:/Users/Administrator/FishC/FishA.txt")
- WindowsPath('C:/Users/Administrator/FishC/FishA.txt')
- >>> k = Path("C:/Users/Administrator/FishC/A")
- >>> k.rename("C:/Users/Administrator/FishC/a")
- WindowsPath('C:/Users/Administrator/FishC/a')
查找:
(6)glob(),查找,返回生成器对象
- >>> a=p.glob("*.txt")
- >>> for each in a:
- ... print(each)
- ...
- C:\Users\Administrator\FishA.txt
- C:\Users\Administrator\FishC.txt
- C:\Users\Administrator\quartus_full_rules_file.txt
- #在当前文件(夹)前一级中寻找
- >>> b=p.glob("*/*.txt")
- >>> for each in b:
- ... print(each)
- ...
- C:\Users\Administrator\Desktop\github使用方法.txt
- C:\Users\Administrator\Desktop\深度学习链接.txt
- C:\Users\Administrator\FishC\FishA.txt
- #进行向下的搜索,查找当前目录和该目录下的所有子目录
- list(p.glob("**/*.txt"))
7,Path中的open()
(1)open()
- >>> n
- WindowsPath('C:/Users/Administrator/FishC')
- >>> n = n/"FishC.txt"
- >>> n
- WindowsPath('C:/Users/Administrator/FishC/FishC.txt')
- >>> f = n.open("w")
- >>> f
- <_io.TextIOWrapper name='C:\\Users\\Administrator\\FishC\\FishC.txt' mode='w' encoding='cp936'>
- >>> f.write("I love you.")
- 11
- >>> f.close()
P56
1,with语句
with语句在 Python 中用于创建一个上下文管理器,这是一种在进入和离开某个特定上下文时执行特定操作的方法。最常见的用途是文件处理和资源管理,如打开文件、锁定资源等。with语句确保在进入和离开上下文时资源会被正确分配和释放,即使在发生异常的情况下也是如此。with语句的一般语法如下:- with expression as variable:
- # 在上下文中执行操作
其中:
expression是一个返回上下文管理器对象的表达式,通常是一个对象,它具有__enter__和__exit__方法。variable是一个可选的变量,它将引用上下文管理器返回的对象。
下面是一个使用
with语句来打开和关闭文件的示例:- # 打开文件并使用 with 语句管理它
- with open('example.txt', 'r') as file:
- data = file.read()
- # 在此块中执行文件操作
- # 离开上下文后,文件已自动关闭
在这个示例中,
open('example.txt', 'r')返回一个文件对象,它充当上下文管理器。在进入with代码块之前,file变量被赋值为这个文件对象。当离开with代码块时,__exit__方法会被调用,它会关闭文件,确保资源被正确释放。with语句在许多情况下都非常有用,特别是在需要管理资源的情况下,以确保资源的正确分配和释放。这使得代码更加健壮和容易维护。2,
pickle是 Python 中的一个模块,用于对象的序列化和反序列化。序列化是将对象转换为字节流的过程,以便将其保存到文件、传输到网络或在程序之间传递。反序列化则是将字节流重新转换为对象的过程。pickle模块提供了一种将 Python 对象转换为字节流并从字节流重新构建对象的方法。下面是
pickle模块的一些常见用法:(1)序列化对象:使用
pickle.dump()函数将 Python 对象序列化为字节流,然后可以将其保存到文件或发送到网络。- import pickle
- data = {'name': 'Alice', 'age': 30, 'city': 'Wonderland'}
- with open('data.pkl', 'wb') as file:
- pickle.dump(data, file)
(2)反序列化对象:使用
pickle.load()函数从字节流中反序列化对象,以便重新创建原始对象。- import pickle
- with open('data.pkl', 'rb') as file:
- loaded_data = pickle.load(file)
- print(loaded_data)
注意事项:需要注意的是,
pickle可以序列化大多数 Python 对象,包括自定义类的实例。但它不是完全安全的,因为反序列化来自不受信任源的数据可能会导致安全问题(例如,恶意代码执行)。因此,在从不受信任的源加载pickle数据之前要格外小心。协议版本:
pickle模块支持不同的协议版本,可以使用pickle.dump()的protocol参数来指定所使用的协议版本。更高的协议版本通常会产生更小、更高效的序列化数据。总之,
pickle是 Python 中一种方便的方式,用于将对象序列化和反序列化,以便在不同时间或不同程序之间传递数据。它是一种强大的工具,但要小心在不受信任的环境中使用它,以避免潜在的安全风险。P59
1,类和对象
类(Class):
(1)类是一种蓝图或模板,用于创建对象的定义。
(2)它包含属性(也称为字段或成员变量)和方法(函数),这些描述了对象的特征和行为。
(3)类定义了对象的结构,它是一个抽象概念。
(4)通过类的实例化,可以创建多个对象,这些对象基于类的定义拥有相同的属性和方法。
(5)类通常用大写字母开头,如
Person。- class Person:
- def __init__(self, name, age):
- self.name = name
- self.age = age
- def greet(self):
- return f"Hello, my name is {self.name} and I am {self.age} years old."
- # 创建类的实例
- person1 = Person("Alice", 30)
- person2 = Person("Bob", 25)
- # 调用对象的方法
- print(person1.greet())
- print(person2.greet())
对象(Object):
(1)对象是类的实例,它基于类的定义创建。
(2)每个对象都有自己的属性值,但这些属性值基于类的属性定义。
(3)对象是类的具体实例,它具体化了类的抽象概念。
(4)对象通常用小写字母开头,如
person1和person2。在上述示例中,
person1和person2是类Person的两个对象。它们都具有类定义的属性(name和age)和方法(greet)。类和对象是面向对象编程的核心,它们使您能够创建具有不同特征和行为的对象,并在代码中组织和管理这些对象。类定义了对象的结构和方法,而对象是类的具体实例,具有特定的属性值。这种抽象和实例化的概念是OOP的基础,它有助于编写模块化、可维护和可扩展的代码。
2,self参数
在 Python 类的方法中,
self是一个特殊参数,它表示方法的实例自身。self参数允许您在方法内部访问和操作对象的属性和方法。虽然self是约定俗成的名称,但您也可以使用其他名称,只要它遵循相同的约定。每个类方法的第一个参数通常都是
self,并且它在方法调用时不需要显式传递,Python 会自动将实例作为self传递给方法。这样,您可以在方法内部访问对象的属性和方法,而不需要显式传递对象本身。下面是一个示例,说明了如何在类方法中使用
self:- class Person:
- def __init__(self, name, age):
- self.name = name
- self.age = age
- def greet(self):
- return f"Hello, my name is {self.name} and I am {self.age} years old."
- # 创建类的实例
- person1 = Person("Alice", 30)
- person2 = Person("Bob", 25)
- # 调用对象的方法,不需要显式传递 self
- print(person1.greet())
- print(person2.greet())
在上述示例中,
self在__init__构造函数和greet方法中使用。当您调用person1.greet()时,Python会自动将person1作为self传递给greet方法,使您可以访问person1对象的属性(name和age)。使用
self参数是 Python 面向对象编程的核心,它允许您在方法内部操作对象的状态和行为,使类的方法能够与其实例进行交互。P60
1,继承
继承是面向对象编程中的一个重要概念,它允许您创建一个新的类,基于现有类的属性和方法来定义新类。新类通常被称为子类(Derived Class)或派生类,而现有类通常被称为父类(Base Class)或基类。继承允许子类继承父类的特征和行为,同时可以添加或修改子类独有的属性和方法。
以下是继承的基本概念:
(1)父类(基类):父类是已经定义的类,它包含一些通用的属性和方法。子类将继承这些属性和方法。
(2)子类(派生类):子类是基于父类创建的类,它继承了父类的属性和方法。子类可以添加新属性和方法,或者覆盖(重写)父类的方法。
(3)继承关系:继承建立了父类和子类之间的关系,子类可以访问父类的属性和方法。这种关系通常被称为"is-a"关系,例如,如果有一个父类
Animal,则可以创建子类Dog和Cat,这两个子类是Animal的子类,因为它们都是动物。下面是一个示例,说明如何创建一个基类和一个子类,以及如何使用继承:
- # 基类(父类)
- class Animal:
- def __init__(self, name):
- self.name = name
- def speak(self):
- pass
- # 子类
- class Dog(Animal):
- def speak(self):
- return f"{self.name} says Woof!"
- class Cat(Animal):
- def speak(self):
- return f"{self.name} says Meow!"
- # 创建子类的实例
- dog = Dog("Buddy")
- cat = Cat("Whiskers")
- # 调用子类的方法
- print(dog.speak()) # 输出: Buddy says Woof!
- print(cat.speak()) # 输出: Whiskers says Meow!
在上述示例中,
Animal类是基类,它有一个属性name和一个抽象方法speak,这个方法在子类中被覆盖。Dog和Cat类是子类,它们继承了Animal类的属性和方法,并在speak方法中提供了不同的实现。继承允许您重用和扩展现有的类,提高了代码的可重用性和可维护性,同时使类的设计更具层次结构。这是面向对象编程中一个强大的概念,允许您创建更有结构的代码。
2,isinstance(),
3,issubclass(),
4,多重继承
当继承的两个类中有相同的属性或方法时,以左侧的为准,因为是从左侧开始继承的。
P61
绑定
1,一个类创建众多对象,方法是众多对象公用的,属性是每个对象独有的。
通过self将对象与属性绑定
2,通过__dict__进行内省来获取对象具有哪些属性
- c.__dict__
- d.__dict__
3,类中有某个属性,他实例出的所有对象共享这个属性,当对某个对象进行自省查看属性时,并没有类中的属性,当对某个对象的这个属性进行赋值时,这个对象就有了自己的这个属性,不再与类共享,这个对象就与自己的这个属性绑定了。
4,类属性和对象属性
在 Python 中,类属性(class attributes)是属于类本身的属性,而对象属性(instance attributes)是属于类的实例的属性。这两者之间存在差异,主要体现在绑定方式和访问方式上。
类属性(Class Attributes):
(1)类属性是定义在类中的属性,它们属于类本身,而不是类的实例。
(2)所有该类的实例共享相同的类属性,这意味着它们在所有实例之间是共享的。
(3)类属性通常在类的顶层定义,不在任何方法内。
(4)类属性可以通过类名或类的实例来访问。
以下是一个示例:
- class MyClass:
- class_attr = 10 # 这是一个类属性
- obj1 = MyClass()
- obj2 = MyClass()
- # 访问类属性
- print(MyClass.class_attr) # 10
- print(obj1.class_attr) # 10
- print(obj2.class_attr) # 10
- # 修改类属性
- MyClass.class_attr = 20
- print(MyClass.class_attr) # 20
- print(obj1.class_attr) # 20
- print(obj2.class_attr) # 20
对象属性(Instance Attributes):
(1)对象属性是属于类的实例的属性,每个实例都有自己的对象属性。
(2)对象属性通常在构造函数
__init__中初始化,并在实例化时分配给对象。(3)对象属性可以通过实例来访问。
以下是一个示例:
- class MyClass:
- def __init__(self, value):
- self.instance_attr = value # 这是一个对象属性
- obj1 = MyClass(10)
- obj2 = MyClass(20)
- # 访问对象属性
- print(obj1.instance_attr) # 10
- print(obj2.instance_attr) # 20
总结:
- 类属性是与类关联的属性,所有实例共享它们。
- 对象属性是与类的实例关联的属性,每个实例有自己的属性。
- 通常,当您希望属性对所有实例都是相同的时候,使用类属性。当您希望每个实例都有自己的属性时,使用对象属性。
5,对象属性覆盖类属性
当一个实例修改了类属性,它实际上会创建一个属于该实例的新对象属性,覆盖类属性。其他实例的类属性仍然保持不变。
- class MyClass:
- class_attr = 10 # 这是一个类属性
- obj1 = MyClass()
- obj2 = MyClass()
- # 初始情况下,类属性的值为 10
- print(obj1.class_attr) # 输出: 10
- print(obj2.class_attr) # 输出: 10
- # 现在,obj1 修改了类属性的值
- obj1.class_attr = 20
- # 修改后,查看类属性和对象属性
- print(MyClass.class_attr) # 输出: 10,类属性没有改变
- print(obj1.class_attr) # 输出: 20,对象属性已被创建并设置为 20
- print(obj2.class_attr) # 输出: 10,类属性对 obj2 没有影响
在上述示例中,
obj1修改了类属性class_attr的值,但实际上它创建了一个新的对象属性class_attr,覆盖了类属性。这是因为 Python 会首先查找对象属性,如果找到则使用它,否则会使用类属性。所以,虽然obj1修改了class_attr,但它只影响了自己的对象属性,而没有影响其他实例或类本身的类属性。如果要在所有实例之间共享一个类属性并且希望修改该类属性,则应通过类本身来进行修改,而不是通过实例。例如:
MyClass.class_attr = 20这将修改类属性,对所有实例都会产生影响。
P62
1,构造函数:__init__()
- >>> class C:
- ... def __init__(self,x,y):
- ... self.x=x
- ... self.y=y
- ... def add(self):
- ... return self.x + self.y
- ... def mul(self):
- ... return self.x * self.y
- ...
- >>> c=C(2,3)
- >>> c.__dict__
- {'x': 2, 'y': 3}
- >>> c.add()
- 5
2,重写
- >>> class D(C):
- ... def __init__(self,x,y,z):
- ... C.__init__(self,x,y)
- ... self.z=z
- ... def add(self):
- ... return C.add(self)+self.z
- ... def mul(self):
- ... return C.mul(self)*self.z
- ...
- >>> d=D(2,3,4)
- >>> d.add()
- 9
- >>> d.mul()
- 24
3,菱形继承
- >>> class A:
- ... def __init__(self):
- ... print("hello,A")
- ...
- >>> class B1(A):
- ... def __init__(self):
- ... A.__init__(self)
- ... print("hello,B1")
- ...
- >>> class B2(A):
- ... def __init__(self):
- ... A.__init__(self)
- ... print("hello,B2")
- ...
- >>> class C(B1,B2):
- ... def __init__(self):
- ... B1.__init__(self)
- ... B2.__init__(self)
- ... print("hello,C")
- ...
- >>> c=C()
- hello,A
- hello,B1
- hello,A
- hello,B2
- hello,C
解决方法:super()函数
将上面的B1,B2,C改为
- >>> class B1(A):
- ... def __init__(self):
- ... super().__init__()
- ... print("hello,B1")
- ...
- >>> class B2(A):
- ... def __init__(self):
- ... super().__init__()
- ... print("hello,B2")
- ...
- >>> class C(B1,B2):
- ... def __init__(self):
- ... super().__init__()
- ... print("hello,C")
- ...
- >>> c=C()
- hello,A
- hello,B2
- hello,B1
- hello,C
4,方法解析顺序mro
super()函数遵循mro顺序
- >>> C.mro()
- [<class '__main__.C'>, <class '__main__.B1'>, <class '__main__.B2'>, <class '__main__.A'>, <class 'object'>]
- >>> B1.mro()
- [<class '__main__.B1'>, <class '__main__.A'>, <class 'object'>]
- >>> A.mro()
- [<class '__main__.A'>, <class 'object'>]
object为所有类都继承的基类
P63
关于supper()函数和mro顺序的一个很繁琐的例子

P64
多态
多态(Polymorphism)是面向对象编程中的一个重要概念,它允许不同的对象对相同的方法做出不同的响应。多态性使得代码更加灵活和可扩展,同时提高了代码的可维护性和可读性。
多态性的主要概念包括以下几点:
(1)方法重载:多态性允许在父类中定义一个通用的方法,子类可以覆盖该方法,根据子类的需求实现不同的行为。这样,不同的子类对象可以调用相同的方法名称,但实际上执行不同的操作。
(2)接口:多态性允许使用接口来描述对象的一组通用行为,而不必关心对象的具体类型。这使得代码更加通用,能够与多个不同类型的对象一起工作。
(3)抽象类和抽象方法:多态性可以通过抽象类和抽象方法来实现,抽象类定义通用接口,子类实现具体行为。
下面是一个示例,演示了多态性的概念:
- class Animal:
- def speak(self):
- pass
- class Dog(Animal):
- def speak(self):
- return "Woof!"
- class Cat(Animal):
- def speak(self):
- return "Meow!"
- def animal_speak(animal):
- return animal.speak()
- # 创建不同的动物对象
- dog = Dog()
- cat = Cat()
- # 调用通用的 animal_speak 方法,不同的对象有不同的响应
- print(animal_speak(dog)) # 输出: Woof!
- print(animal_speak(cat)) # 输出: Meow!
在上述示例中,
Animal类定义了一个通用的speak方法,而Dog和Cat类分别覆盖了这个方法以提供不同的行为。animal_speak函数接受一个Animal对象,但实际上它可以接受任何派生自Animal的对象,并调用相应的speak方法,实现了多态性。多态性使得代码更具通用性,同时也提高了代码的可扩展性,因为您可以轻松地添加新的子类来扩展现有的功能而不必修改现有的代码。这是面向对象编程的重要概念之一。
P65
1,私有属性
属性名前加双下划线
- >>> class Myclass:
- ... def __init__(self):
- ... self._a=42
- ... self.__b=43
- ... def _func1(self):
- ... return "This is func1."
- ... def __func2(self):
- ... return "This is func2"
- ...
- >>> obj = Myclass()
- >>> obj._a
- 42
- >>> obj.__b #无法直接外部调用
- Traceback (most recent call last):
- File "
" , line 1, in - AttributeError: 'Myclass' object has no attribute '__b'
- >>> obj._Myclass__b
- 43
- >>> obj._func1()
- 'This is func1.'
- >>> obj.__func2() #无法直接外部调用
- Traceback (most recent call last):
- File "
" , line 1, in - AttributeError: 'Myclass' object has no attribute '__func2'
- >>> obj._Myclass__func2()
- 'This is func2'
对对象属性自省
- >>> obj.__dict__
- {'_a': 42, '_Myclass__b': 43}
2,__slots__()类属性
python中对类属性的存储是以字典的形式,速度快,可以自由添加属性,但消耗大量空间,对于一些类,对其属性变化的要求比较小,,使用__slots__()来使存储方式不是字典形式。
- >>> class C:
- ... __slots__ = ["x","y"]
- ... def __init__(self,x):
- ... self.x = x
- ...
- >>> c=C(1)
- >>> c.__dict__
- Traceback (most recent call last):
- File "
" , line 1, in - AttributeError: 'C' object has no attribute '__dict__'
- >>> c.x
- 1
- >>> c.y
- Traceback (most recent call last):
- File "
" , line 1, in - AttributeError: y
- >>> c.y=2
- >>> c.y
- 2
继承自父类的__slots__属性是不会在子类中生效的,
- >>> class E(C):
- ... pass
- ...
- >>> e=E(250)
- >>> e.__dict__
- {}
- >>> e.x
- 250
- >>> e.y=2
- >>> e.y
- 2
- >>> e.__dict__
- {}
- >>> e.z=666
- >>> e.z
- 666
- >>> e.__dict__
- {'z': 666}
P66
魔法方法
1,__init__()方法:构造函数
2,__new__(cls[,...])方法,在__init__之前自动调用,返回self
两种情况下需要重写new方法
(1)在元类中定制类
(2)继承不可变数据类型时,可以通过重写new方法进行拦截,
- >>> class CapStr(str):
- ... def __new__(cls,string):
- ... string = string.upper()
- ... return super().__new__(cls,string)
- ...
- >>> cs = CapStr("FishC")
- >>> cs
- 'FISHC'
在对象被创建之前进行拦截,改变传入的参数,使用改变后的参数用于创建对象。
-
相关阅读:
webscoket学习
从0搭建Vue3组件库之Icon组件
Redis从入门到放弃(9):集群模式
Linux-unbuntu修改apt源
(Java版)转反串符字累很天聊他和长学海云 ,话说着倒欢喜三张身彼施还道之彼以算打长学海云是于
IDEA2020创建JavaSE项目改造成JavaWeb项目并配置tomcat
Spring Boot技术知识点:Bean Validation
前端工程化——前后端分离,进化流程
springboot整合SSE
输入回车换行,div标签可编写
- 原文地址:https://blog.csdn.net/m0_56997192/article/details/134019758
