-
堆(二叉树,带图详解)
🗡CSDN主页:d1ff1cult.🗡
🗡代码云仓库:d1ff1cult.🗡
🗡文章栏目:数据结构专栏🗡
一.堆
1.堆的概念
如果有一个关键码的集合K = { , , ,…, },把它的所有元素按完全二叉树的顺序存储方式存储 在一个一维数组中,并满足: <= 且
<= ( >= 且 >= ) i = 0,1,
2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。堆是一种非线性结构,是完全二叉树
堆分为小根堆(小堆)和大根堆(大堆)两种,小堆中所有的父节点均小于他的子结点,大堆中所有的父结点均大于子节点。
堆的底层用数组存储
小根堆:
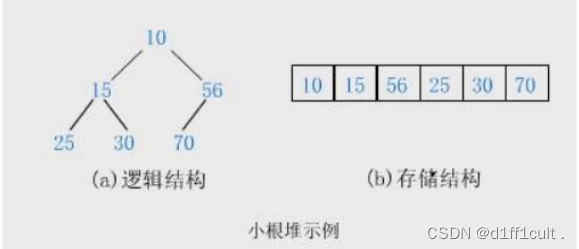
大根堆:

顺序存储下左右子树与父节点之间的关系:
leftchild=parent*2+1;rightchild=parent*2+2;
parent=(child-1)/2;
2.堆的存储方式
🗡逻辑结构
这里的逻辑结构是我们为了可以更好的李姐而想象出来的
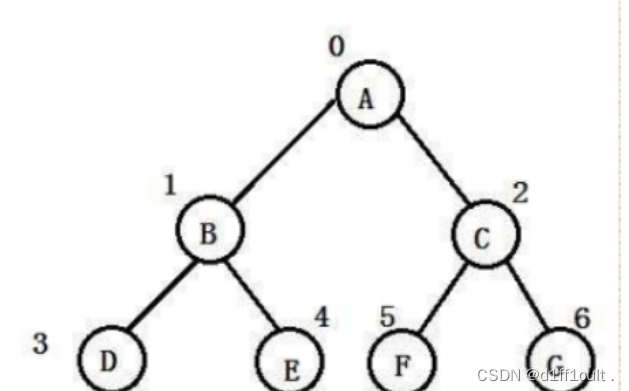
🗡物理结构
堆在内存中就是这样存储的

2.堆的插入问题


插入90我们发现该堆仍然是小堆,其实这是一个巧合,当我们插入50的时候发现该堆不再是一个小堆,我们此时需要不断地对50进行调整才能使得该堆重新成为小堆。
接下来继续向堆中插入一个5
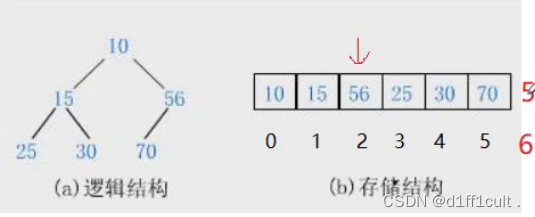
插入数据后调整的基本思路:此时5的下标为6,根据5的下标找到5的父亲结点(5-1)/2=2 ,5的父亲结点为56,再让5与56比较大小,发现56>5所以将56和5的位置进行交换,再继续让交换后的5找父亲节点,5的父亲结点的下标为(2-1)/2=0,5的父亲结点为10,再将5与10继续比较,10>5进行交换,此时5的下标为0为根节点,调整完毕。
第一次进行交换:56与5进行比较 5<56 交换5和56

第二次进行交换: 找到交换后的5的父节点10,将10与5进行比较5<10则交换5与10的位置

很奇怪,这个最后插入的5 从孙子一跃成为了爷爷(bushi
3.堆的基本实现(代码)(以小堆为例)
下面介绍几个主要的实现堆的函数。
- typedef int HPDataType;
- typedef struct Heap
- {
- HPDataType* a;
- int size;
- int capacity;
- }HP;
- void Swap(HPDataType* a, HPDataType* b);
- void HeapPrint(HP* php);
- void HeapInit(HP* php);
- void HeapDestroy(HP* php);
- void HeapPush(HP* php, HPDataType x);
- void HeapPop(HP* php);
- HPDataType HeapTop(HP* php);
- void AdjustUp(HPDataType* a, int child);
- void AdjustDown(HPDataType* a,int n,int parent);
- bool HeapEmpty(HP* php);
- void HeapInitArray(HP* php, int* a, int n);
- void HeapSor
🗡堆的初始化
将数组和容量以及数组大小全部置空。
- void HeapInit(HP* php)
- {
- assert(php);
- php->a = NULL;
- php->capacity = 0;
- php->size = 0;
- }
🗡向上调整
将插入的结点一步步调整,使该堆再次成为小堆
向上调整的前提:前面的数据是堆
- AdjustUp(HPDataType* a, int child)
- {
- int parent = (child - 1) / 2;
- while (child>0)
- {
- if (a[child] < a[parent])
- {
- Swap(&a[child], &a[parent]);
- child = parent;
- parent = (parent - 1) / 2;
- }
- else
- {
- break;
- }
- }
- }
🗡插入结点
插入一个结点,并将其调整成为一个小堆
- void HeapPush(HP* php, HPDataType x)
- {
- assert(php);
- if (php->size == php->capacity)
- {
- int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;
- HPDataType* tmp = (HPDataType*)realloc(php->a,sizeof(HPDataType) * newcapacity);
- if (tmp == NULL)
- {
- perror("realloc fail");
- }
- php->a = tmp;
- php->capacity = newcapacity;
- }
- php->a[php->size] = x;
- php->size++;
- AdjustUp(php->a, php->size-1);
- }
🗡交换函数、堆的打印
- void Swap(HPDataType* p1, HPDataType* p2)
- {
- HPDataType tmp = *p1;
- *p1 = *p2;
- *p2 = tmp;
- }//交换函数
- void HeapPrint(HP* php)
- {
- assert(php);
- for (int i = 0; i < php->size; i++)
- {
- printf("%d ", php->a[i]);
- }
- printf("\n");
- }//堆的打印函数
🗡向下调整
向下调整的前提:根结点左右子树都是堆
- void AdjustDown(HPDataType* a, int n, int parent)
- {
- int child = parent * 2 + 1;
- while(child{if (child+1{++child;}if (a[child] < a[parent])// 父节点与两个儿子中较小的一个交换位置{Swap(&a[child], &a[parent]);parent = child;child = child * 2 + 1;}else{break;}}}
🗡删除根节点并调整成小根堆
- void HeapPop(HP* php)
- {
- assert(php);
- assert(php->size > 0);
- Swap(&php->a[0], php->a[php->size - 1]);
- --php->size;
- AdjustDowm(php->a, php->size, 0);
- }
🗡获取堆顶的元素
- HPDataType HeapTop(HP* php)
- {
- assert(php);
- assert(php->size > 0);
- return php->a[0];
- }
🗡判断栈是否为空
- bool HeapEmpty(HP* php)
- {
- assert(php);
- return php->size == 0;
- }
🗡另一种初始化数组的方法
- void HeapInitArray(HP* php, int* a, int n)
- {
- assert(php);
- assert(a);
- php->a = (HPDataType*)malloc(sizeof(HPDataType) * n);
- if (php->a == NULL)
- {
- perror("malloc fail");
- exit(-1);
- }
- php->size = n;
- php->capacity = n;
- memcpy(php->a, a, sizeof(HPDataType) * n);
- for (int i = 0; i < n; i++)
- {
- AdjustUp(php->a, i);
- }
- }
🗡两种实现堆排序的方法的比较
下面是使用HeapPush()函数实现堆排的过程 :
- void AdjustUp(HPDataType* a, int child)
- {
- int parent = (child - 1) / 2;
- while (child>0)
- {
- if (a[child] < a[parent])
- {
- Swap(&a[child], &a[parent]);
- child = parent;
- parent = (parent - 1) / 2;
- }
- else
- {
- break;
- }
- }
- }
- void HeapPush(HP* php, HPDataType x)
- {
- assert(php);
- if (php->size == php->capacity)
- {
- int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;
- HPDataType* tmp = (HPDataType*)realloc(php->a,sizeof(HPDataType) * newcapacity);
- if (tmp == NULL)
- {
- perror("realloc fail");
- }
- php->a = tmp;
- php->capacity = newcapacity;
- }
- php->a[php->size] = x;
- php->size++;
- AdjustUp(php->a, php->size-1);
- }
这种方法是通过malloc函数开辟一块一块的空间,并通过不断地扩容将数据push到数组中,再对数组中的内容进行不断的向上调整从而达到堆排的目的。
下面是用AdjustUp()函数实现堆排的过程:
- void AdjustUp(HPDataType* a, int child)
- {
- int parent = (child - 1) / 2;
- while (child>0)
- {
- if (a[child] < a[parent])
- {
- Swap(&a[child], &a[parent]);
- child = parent;
- parent = (parent - 1) / 2;
- }
- else
- {
- break;
- }
- }
- }
- void HeapSort(int* a, int n)
- {
- for (int i = 0; i < n; i++)
- {
- AdjustUp(a, i);
- }
- }
这种方法与HeapPush函数不同的地方在于该函数传参数时直接传入一个数组,省去了malloc开辟空间的消耗。
二、堆的应用与实现
🗡堆的升序写法
通常这里我们都会问一个问题,实现升序排序我们应该建一个小堆还是一个大堆?
答案是,升序时我们应该建一个大堆,那么为什么呢?
我们都知道小堆的根节点是整棵二叉树中最小的值,选出了最小的值之后,我们还要去找次小的值
首先是建小堆不适用的原因,这里有这样一个数组,我们将这个数组展开:
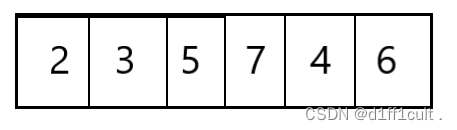
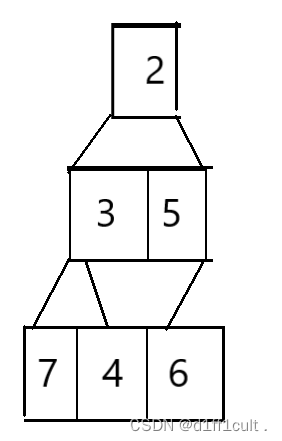
按照我们需要建升序堆的要求,我们会将最小的根节点删除掉,删除后如下图所示

我们发现这个二叉树不再是堆,但是我们要选择次小值的话需要进行调整,就需要重新建堆,建堆的时间复杂度为o(n)=n*logn,代价还是比较大的,甚至不如遍历一遍来的快,所以我们这里摒弃了建小堆的想法,那么接下来就看看建大堆的优势在哪里了
建大堆的基本思想以及优势:
我们排升序,建一个大堆,将根节点和最后一个结点交换位置,那么最大的数就被交换到了数组的最后面,此时一个数字已经排好了,原本根节点的左右子树还是堆,我们就可以通过向下调整,来找出次打的值,此时我们不再把交换到数组最后的根节点看作树的结点,对剩下的数字进行向下调整,找出了次小的值,这里的时间复杂度O(n)仅仅为logn合计起来n个结点的时间复杂度O(n)=n*logn,消耗比较小。再与树的最后一个结点进行交换。过程我们用下面的数组进行演示。

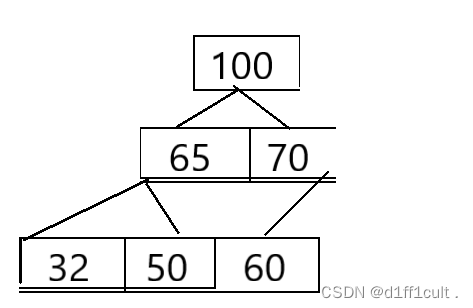
将根节点的数字与树的最后一个结点的数字进行交换,并不再把交换到后面的根节点看作树的内容
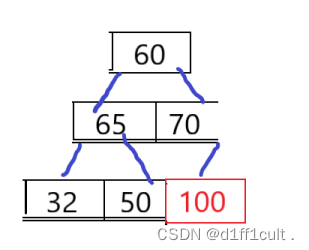
🗡升序堆:
- void AdjustUp(HPDataType* a, int child)
- {
- int parent = (child - 1) / 2;
- while (child>0)
- {
- if (a[child] > a[parent])
- {
- Swap(&a[child], &a[parent]);
- child = parent;
- parent = (parent - 1) / 2;
- }
- else
- {
- break;
- }
- }
- }
- void AdjustDown(HPDataType* a, int n, int parent)
- {
- int child = parent * 2 + 1;
- while(child{if (child+1{++child;}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = child * 2 + 1;}else{break;}}}void HeapSort(int* a, int n){for (int i = 0; i < n; i++){AdjustUp(a, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}}
🗡向下调整建堆(大堆)
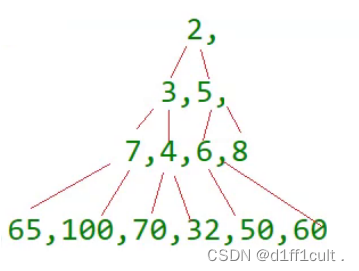
有这样一个数组,我们如果想通过用根节点直接向下调整建大堆,就必须保证根节点的左右子树都是大堆,所以我们就想出了倒着调整树的方法:
需要注意的是:单个叶子结点,既是大堆也是小堆。
这种建堆方法是从树的末尾开始找到第一个非叶子结点然后对其进行向下调整,从数组后面查找的第一个非叶子结点也就是树中最后一个结点的父节点,最后一个结点的下标为n-1,则它的父结点的下标为(n-1-1)/2 ,这棵树从后面查找的第一个非叶子结点是6,对6进行向下调整,如下图
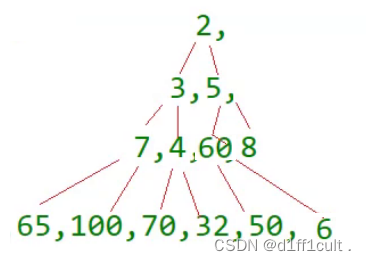
我们发现调整完成之后,结点5的左子树已经成为了大堆,右子树也是大堆,那我们就应该对下一个非叶子结点进行调整了,我们只需要将60位置的下标+1,就得到了下一个非叶子结点的下标,同理也对他进行调整,直到2的左右子树都调整为大堆
- void AdjustDown(HPDataType* a, int n, int parent)
- {
- int child = parent * 2 + 1;
- while(child{if (child+1{++child;}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = child * 2 + 1;}else{break;}}}void HeapSort(int* a, int n){//向上调整建堆(大堆或者小堆)//for (int i = 0; i < n; i++)//{// AdjustUp(a, i);//}//向下调整建堆for (int i = (n - 2) / 2; i >= 0; i--){AdjustDown(a, n, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}}
向上调整建堆,时间复杂度O(n)=n*logn,而向下调整建堆的时间复杂度O(n)=n.
总结
上述就是关于堆的一些知识,有不懂的地方欢迎提问。
-
相关阅读:
Bootstrap 框架学习笔记(基础)
C语言之动态内存分配二
HashMap为什么会发生死循环?
20231017定时任务
opencv python截取圆形区域
【Java八股文总结】之异常
【Leetcode】【C语言】【合并两个升序单链表】
Docker的安装以及使用
关于架构的一些理念
Java异常、SpringBoot中全局捕获处理异常
- 原文地址:https://blog.csdn.net/qq_74732628/article/details/133961364
