-
Elasticsearch聚合----aggregations的简单使用
ES中的aggregations提供了数据分析能力,比如从数据中分组和提取数据的能力。最简单的聚合方法大致等于 SQL中GROU BY和SQL中的聚合函数。在 Elasticsearch 中,执行聚合返回 hits(命中结果)的同时还返回聚合结果。
测试数据(account.json)Getting started
基本语法,使用‘
aggs’属性进行标识NAME:自定义当前聚合的名称AGG_TYPE:指定当前聚合的类型
GET bank/_search { "aggs": { "NAME": { "AGG_TYPE": {} } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1、搜索 address 中包含 mill 的所有人的年龄分布以及平均年龄,但不显示这些人的详情
1、搜索 address 中包含 mill 的所有人的年龄分布
GET bank/_search { "query": { "match": { "address": "mill" } }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 10 } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
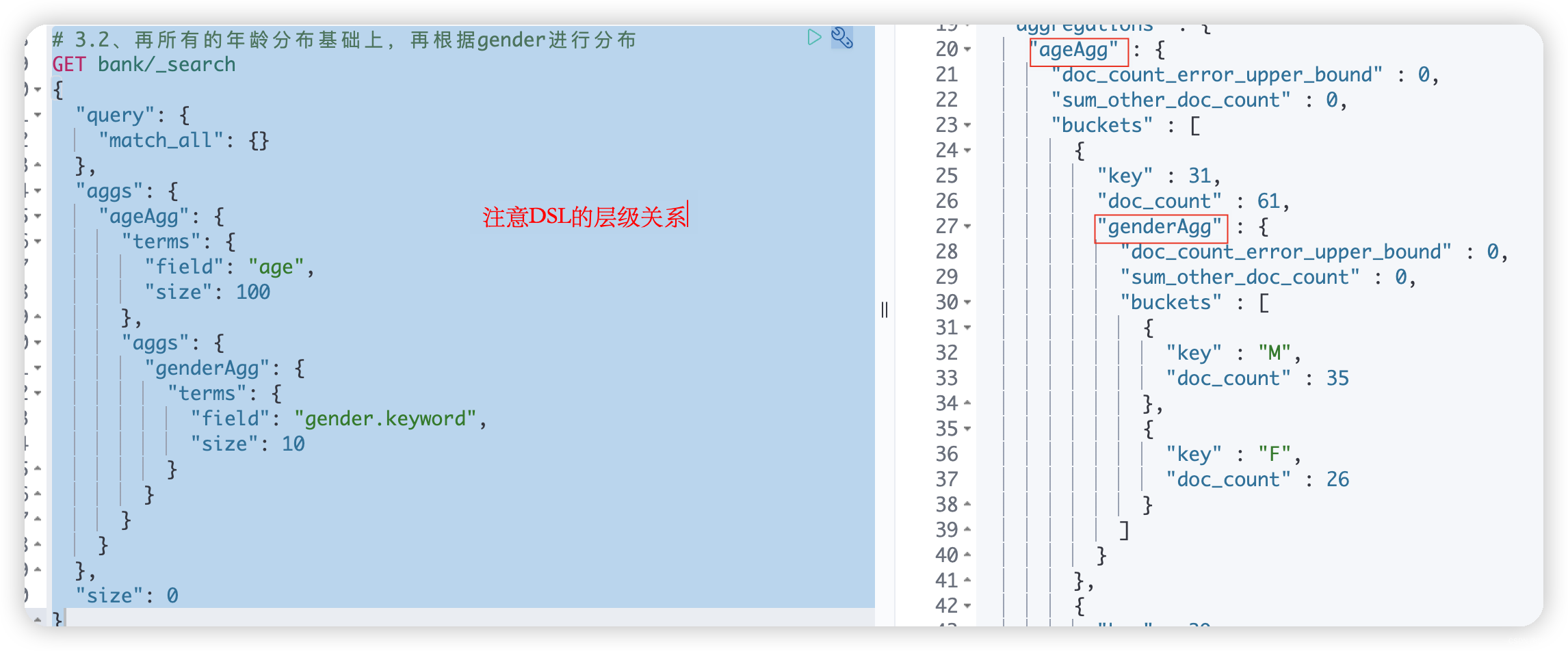
ageAgg:自定义的当前的聚合名称terms:是当前聚合的类型,terms表示分布情况field:表示当前聚合使用哪个字段size:表示显示多少条聚合的信息
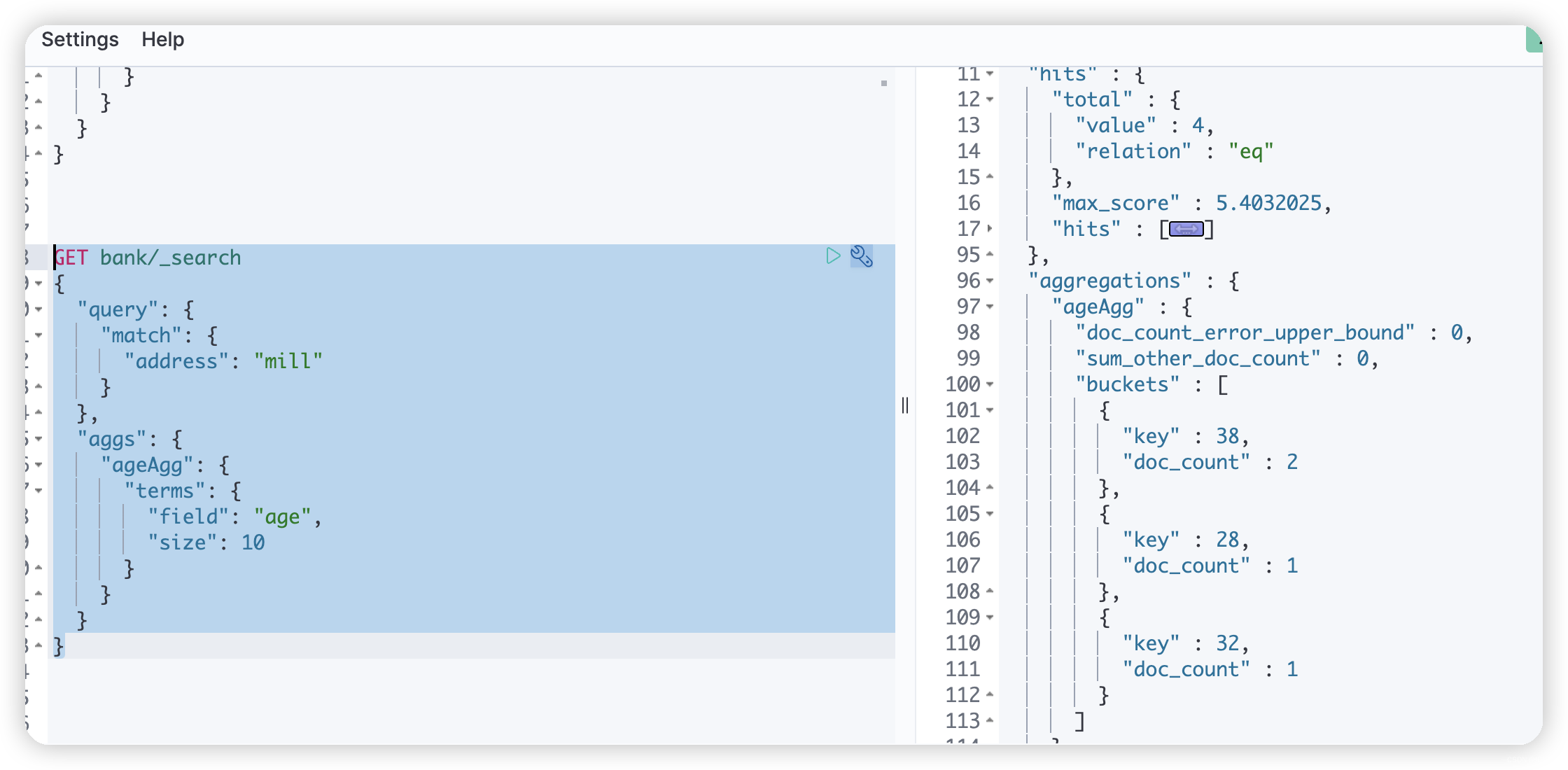
上图中,query的match一共命中了4条记录,其中的aggregations节点展示了当前聚合的结果 ;可以明显的看到ageAgg就是自定义的聚合名称,buckets节点统计的age的分别情况:- age=38的记录一共是2条
- age=28的记录一共是1条
- age=32的记录一共是1条
2、聚合第一步4个人的平均年龄
以上就是address 中包含 mill 的所有人的年龄分布,接下来聚合这四个人的平均年龄,同样ageAvg是给该聚合结果自定义的一个名称;avg是该聚合类型,表示聚合平均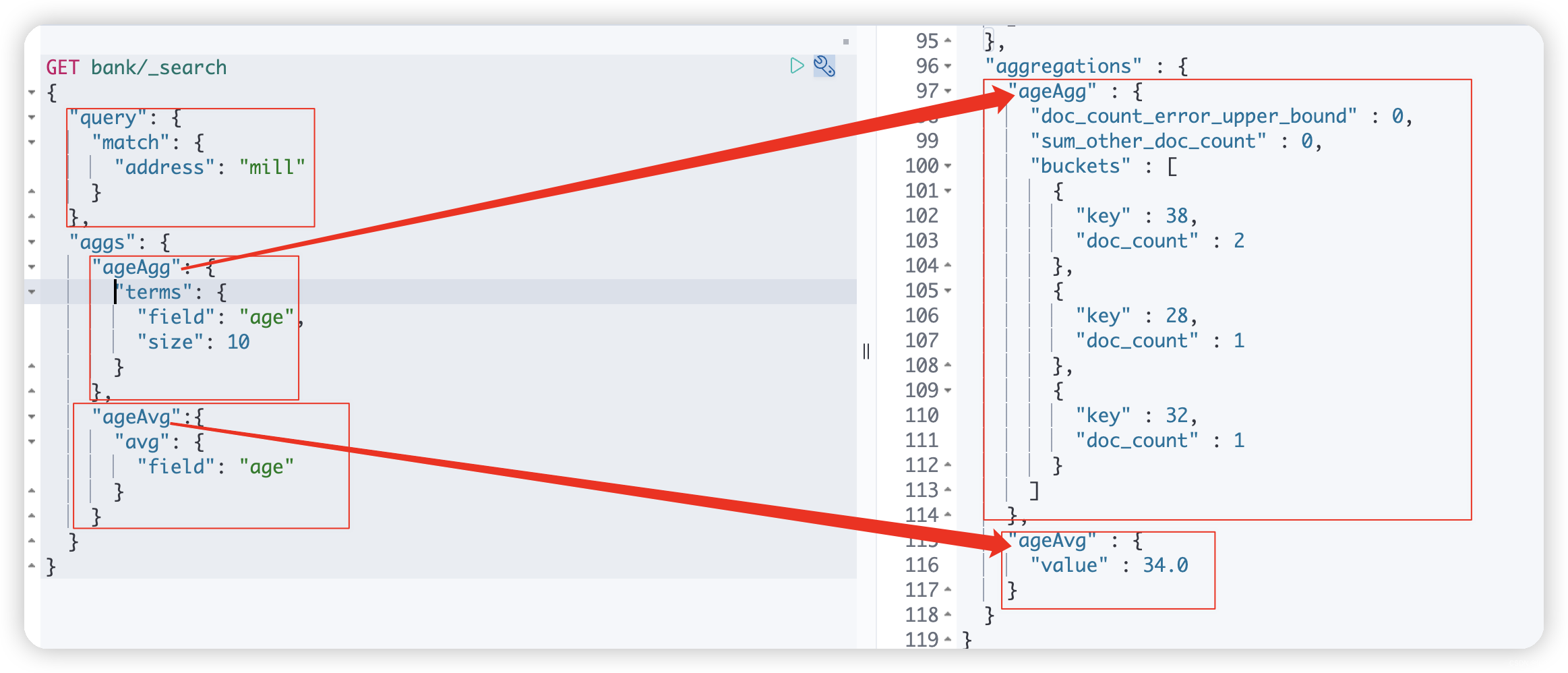
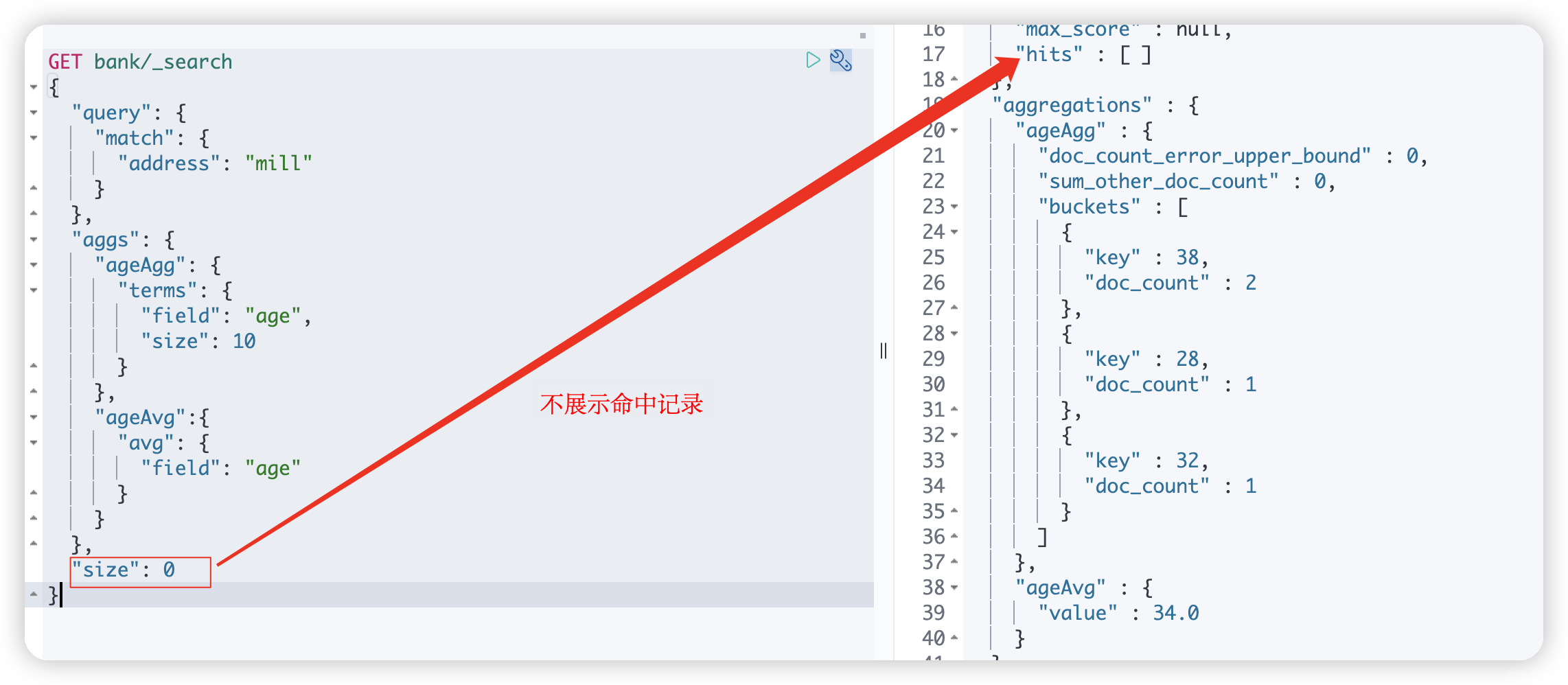
下面是**搜索 address 中包含 mill 的所有人的年龄分布以及平均年龄,但不显示这些人的详情 **的完整DSLGET bank/_search { "query": { "match": { "address": "mill" } }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 10 } }, "ageAvg":{ "avg": { "field": "age" } } }, "size": 0 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2、size=0不展示命中记录,只展示聚合结果
3、按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
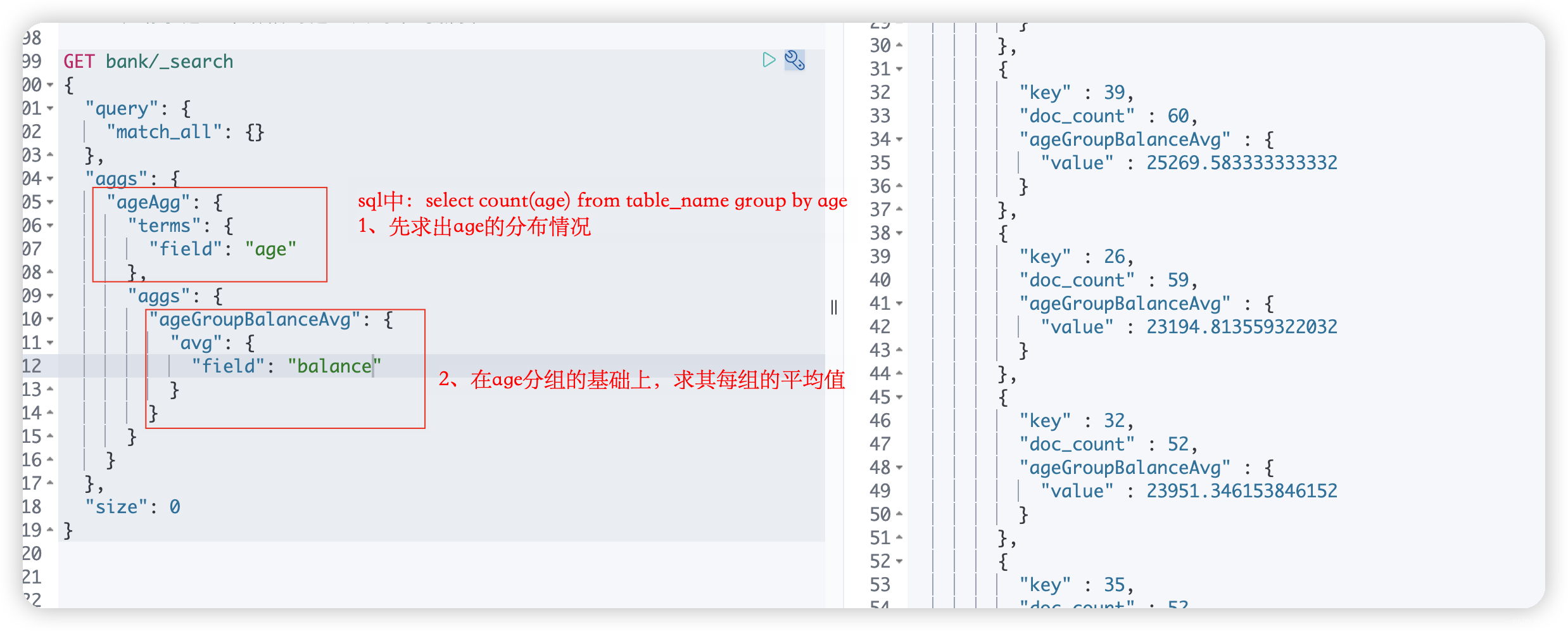
# 2、按照年龄聚合,并且请求这些年龄段的这些人的平均薪资 # 2.1、求出所有的年龄分布 GET bank/_search { "query": { "match_all": {} }, "aggs": { "ageAgg": { "terms": { "field": "age" } } }, "size": 0 } # 2.2、最终;请求这些年龄段的这些人的平均薪资 GET bank/_search { "query": { "match_all": {} }, "aggs": { "ageAgg": { "terms": { "field": "age" }, "aggs": { "ageGroupBalanceAvg": { "avg": { "field": "balance" } } } } }, "size": 0 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
4、查出所有年龄分布,并且这些年龄段中性别M的平均薪资和性别F的平均薪资以及这个年龄段的总体平均薪资
4.1、聚合所有人的年龄分布
GET bank/_search { "query": { "match_all": {} }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 100 } } }, "size": 0 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4.2、在4.1的基础上再对每组中的gender进行分布聚合
# 再所有的年龄分布基础上,再根据gender进行分布 GET bank/_search { "query": { "match_all": {} }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 100 }, "aggs": { "genderAgg": { "terms": { "field": "gender.keyword", "size": 10 } } } } }, "size": 0 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
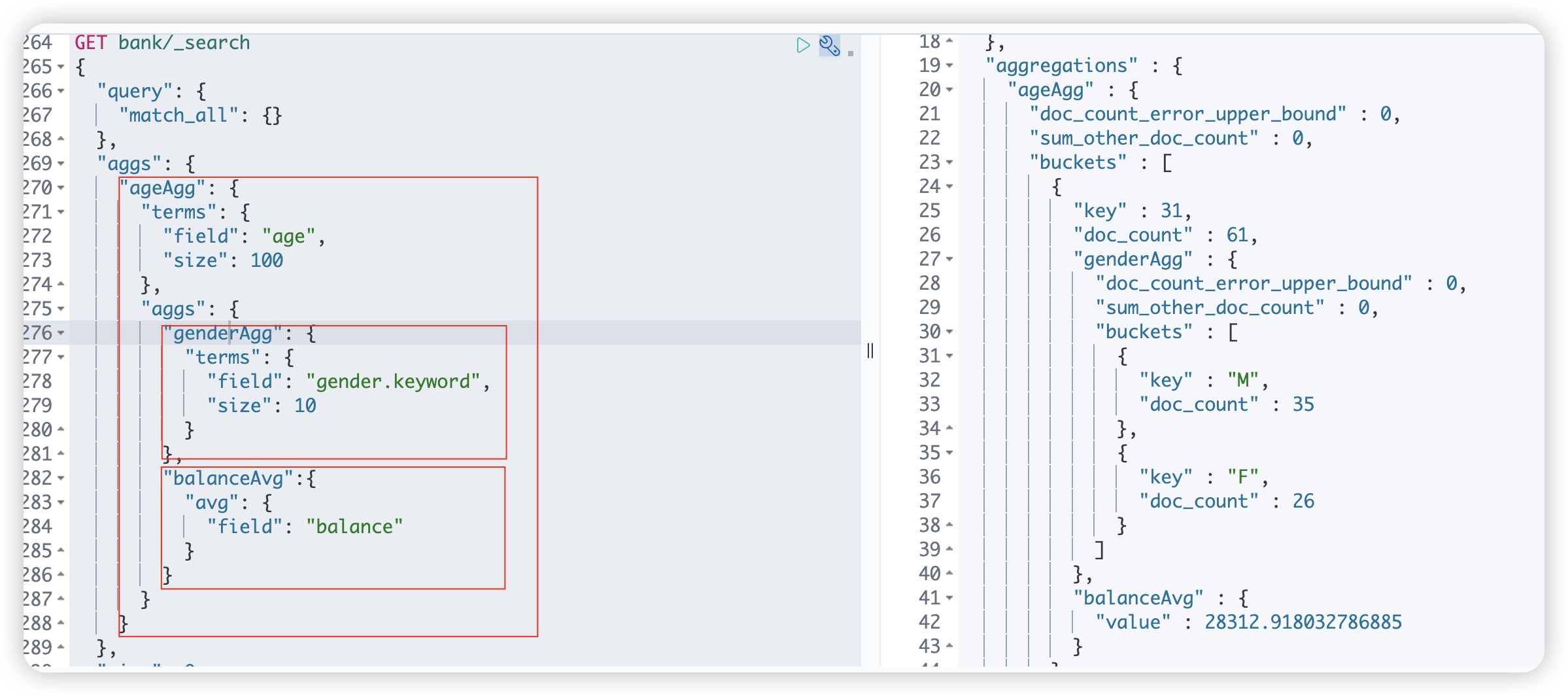
4.3、最后求得每个年龄段的平均薪资GET bank/_search { "query": { "match_all": {} }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 100 }, "aggs": { "genderAgg": { "terms": { "field": "gender.keyword", "size": 10 } }, "balanceAvg":{ "avg": { "field": "balance" } } } } }, "size": 0 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
-
相关阅读:
ARM GIC 和NVIC的区别
一些流程图(自用)
【Linux杂货铺】调试工具gdb的使用
[LeetCode][LCR169]招式拆解 II——巧妙利用字母的固定顺序实现查找复杂度为O(1)的哈希表
Django REST项目实战:在线中文字符识别
后端都需要学习什么?
常见的浏览器跨域解决方法
SpringCloud
Oracle.xs.dll‘ for module DBD::Oracle: load_file:找不到指定的模块
React基础汇总
- 原文地址:https://blog.csdn.net/weixin_43859011/article/details/134016872
