-
hadoop伪分布式安装部署
首先jdk安装完毕
jdk安装文档参考:
Linux 环境下安装JDK1.8并配置环境变量_linux安装jdk1.8并配置环境变量_Xi-Yuan的博客-CSDN博客
准备好hadoop的安装包
我的下载地址如下:
We Transfer Gratuit. Envoi sécurisé de gros fichiers.
将hadoop包上传到随便一个目录,但是解压缩到/opt/ 目录下
tar -zvxf /home/hadoop-3.1.3.tar.gz -C /opt/
cd /opt/hadoop-2.9.2/etc/hadoop
vi hadoop-env.sh
#修JAVA_HOME
export JAVA_HOME=/usr/opt/java/jdk1.8.0_339
cd /opt/hadoop-2.9.2/etc/hadoop/
vi core-site.xml
#要添加的配置内容
fs.default.name
hdfs://192.168.137.15:9000
fs.defaultFS
hdfs://192.168.137.15:9000
hadoop.tmp.dir
/home/hadooptmp

配置hdfs-site.xml,制定hdfs保存数据的副本数量,伪分布式只有一个节点,所以填写1
dfs.replication
1
dfs.name.dir
/home/hadoopname
dfs.data.dir
/home/hadoopdata
配置mapred-site.xml:原本hadoop文件下没有这个文件,我们copy一个出来
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
#添加以下内容
mapreduce.framework.name
yarn
vi yarn-site.xml
添加两个属性,第一个告诉nodemanager获取数据的方式为shuffle
yarn.nodemanager.aux-service
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop
添加hadoop的路径
vi /etc/profile
export HADOOP_HOME=/opt/hadoop-2.9.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
然后生效
source /etc/profile

域名hosts绑定
vi /etc/hosts
#添加本机ip与hosts的绑定
192.168.137.15 hadoop

配置主机的免密登录
cd /root/
# 如果本机没有登录过其它机器时,本地是没有/root/.ssh文件夹的,只需要 ssh hadoop 登录一次就会自动创建了
cd .ssh
ssh-keygen -t rsa
cat id_rsa.pub >> authorized_keys
#测试免输入密码
ssh hadoop

开始初始化和启动hadoop
初始化:
先格式化:
cd /opt/hadoop-2.9.2/etc/hadoop/
hadoop namenode -format

启动
cd /opt/hadoop-2.9.2/sbin
./start-all.sh

jps命令查看已经启动的进程

测试hdfs命令
查看根目录下是否有东西,如果没有则自己新建两个看下哦效果
cd /opt/hadoop-2.9.2/bin
hadoop fs -ls /

hadoop fs -mkdir /test
hadoop fs -mkdir /rt

再次查看
 #浏览器测试,输入地址http://192.168.137.15:50070/
#浏览器测试,输入地址http://192.168.137.15:50070/ip地址为hadoop虚拟机的ip
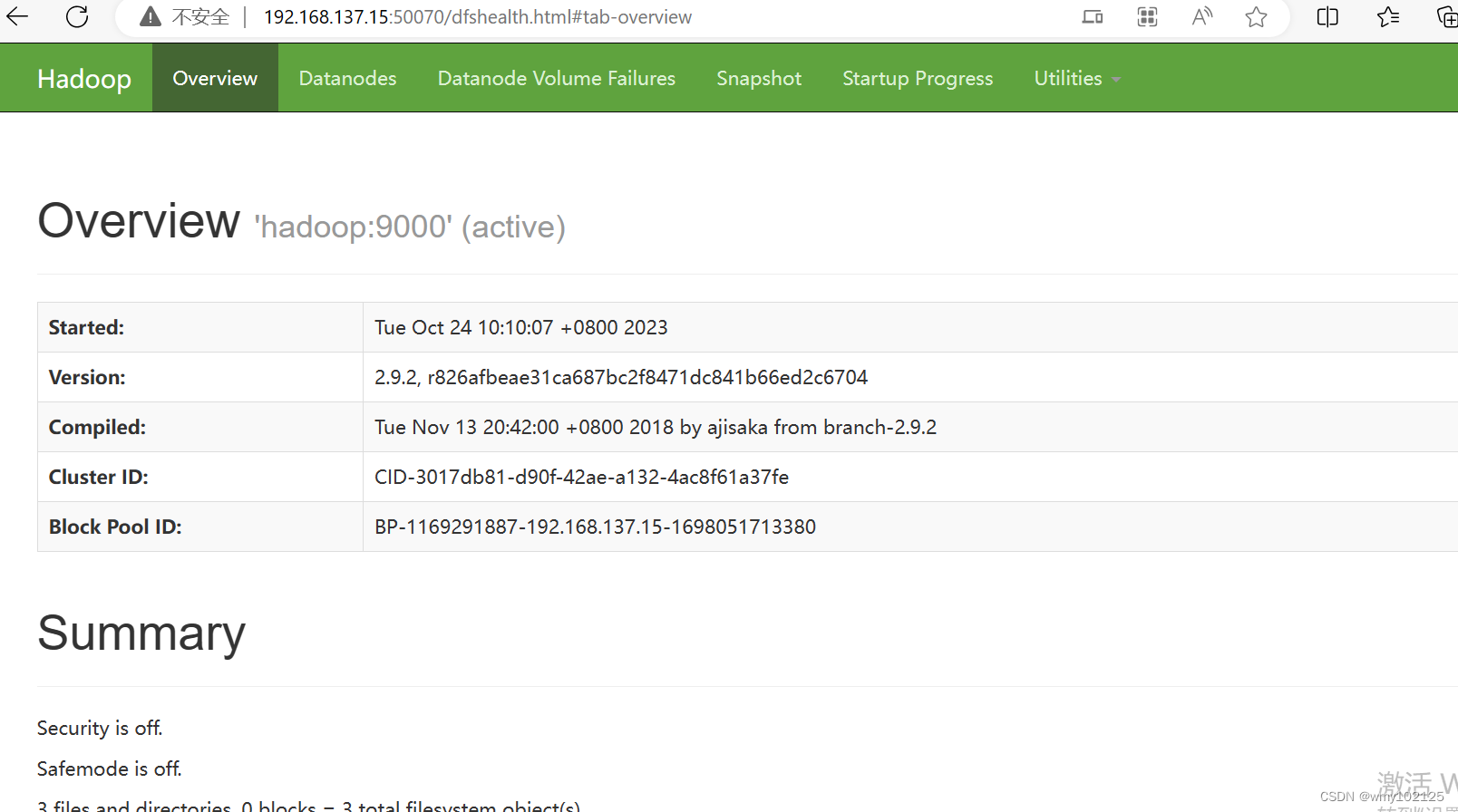


-
相关阅读:
Air72XUX平台secure boot使用说明
敏捷12原则
51.HarmonyOS鸿蒙系统 App(ArkUI)通知
Linux期末复习总结
Linux下发生几个字节内存泄露检测方法
294_C++_报警状态bit与(&)上通道bit,然后检测置位的通道,得到对应置位通道的告警信息,适用于多通道告警,组成string字符串发送
IDEA 快捷键
接口自动化测试介入项目管理流程
SQL查询本年每月的数据
iOS 无宿主App源码时,真机环境一键调试动态库
- 原文地址:https://blog.csdn.net/u012558695/article/details/133993472