-
【Python · PyTorch】数据基础
本文介绍了PyTorch数据基础,Python版本3.9.0,代码于Jupyter Lab中运行,以尽可能简单的文字阐述相关内容。
1. 数据操作
1.1 入门
首先,我们先导入torch,在python中PyTorch被称作torch。
import torch- 1

张量表示一个由数值(元素)组成的数组,其可能具有多个维度,即可在多个坐标轴上表示。
- 一维张量:向量(vector)
- 二维张量:矩阵(matrix)
我们调用
arange函数创建一个行向量x,其包含从0开始前20个整数,默认为整数,也可被指定为浮点数。x = torch.arange(20)- 1

调用python内置函数
type可得知,创建的x为torch中的Tensor(张量)对象。type(x) #- 1
- 2

我们调用
reshape函数可以改变一个张量的形状且不改变元素数量、元素值,下面我们对x向量作变换,得到4*5矩阵y。y = x.reshape(4, 5) z = x.reshape(5, 6) # 当我们试图变换超过其总元素大小时,程序会抛出异常- 1
- 2

当矩阵元素数量足够多时,我们不需要手动指定每个维度改变形状,可以使用
-1来表示其中一个维度,如下所示。z = x.reshape(5,-1) y1 = x.reshape(4,-1)- 1
- 2

我们通过
shape属性访问张量的形状,通过numel获知其元素总量(大小),如下所示,我们分别对x和y做如上操作。x.shape # 表示x矩阵的形状 x.numel() # 表示x矩阵的元素总量 y.shape # 表示x矩阵的形状 y.numel() # 表示x矩阵的元素总量- 1
- 2
- 3
- 4
- 5

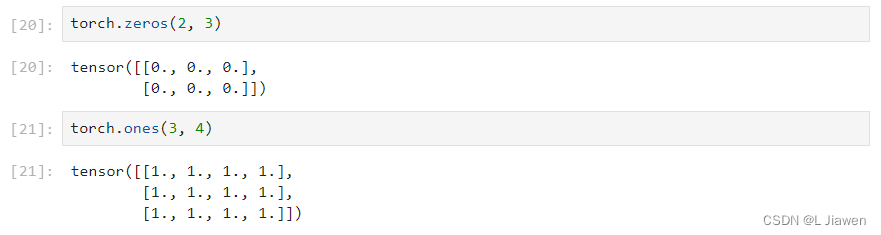
通过
zeros和ones函数创建任意形状的全0、全1元素矩阵。torch.zeros(2, 3) torch.ones(3, 4)- 1
- 2
- 3
有时我们想从某个特定的概率分布中随机采样得到每个元素的值,通过
randn函数创建一个每个元素都从均值为0、方差为1的标准高斯分布(正态分布)中随机采样的矩阵。torch.randn(3, 4)- 1

1.2 运算符
下面介绍张量如何逐元素运算。
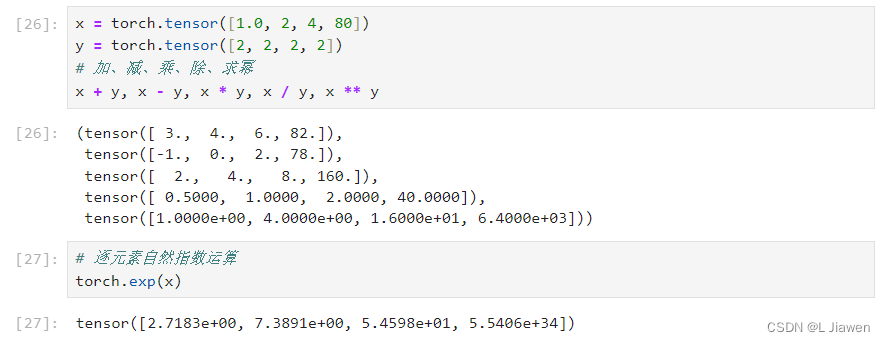
x = torch.tensor([1.0, 2, 4, 8]) y = torch.tensor([2, 2, 2, 2]) # 加、减、乘、除、求幂 x + y, x - y, x * y, x / y, x ** y # 逐元素自然指数运算 torch.exp(x) # tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
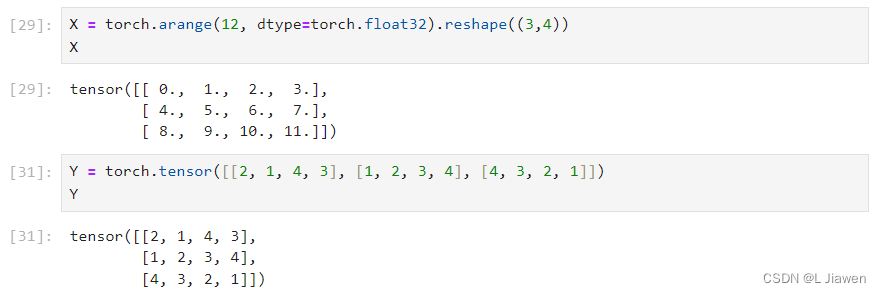
下面介绍如何将多个张量连接在一起,首先创建两个矩阵
X = torch.arange(12, dtype=torch.float32).reshape((3,4)) Y = torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])- 1
- 2
分别对矩阵做纵向、横向拼接。
# 纵向拼接 torch.cat((X, Y), dim=0) # 横向拼接 torch.cat((X, Y), dim=1)- 1
- 2
- 3
- 4
- 5

我们可以通过
==对两矩阵逐元素进行比较,可以得到各元素均为布尔型的矩阵。X == Y- 1

对张量中所有元素求和,会产生一个单元素张量。
X.sum()- 1

1.3 广播机制
广播机制的工作方式如下:
- 通过适当复制元素来扩展一个或两个数组,使其转换后具有相同的形状
- 对生成的数组执行按元素操作
多数情况下,我们沿着数组中长度为1的轴进行广播。
a = torch.arange(3).reshape((3,1)) b = torch.arange(2).reshape((1,2))- 1
- 2

其形状不匹配,我们可以将其广播为一个更大的3×2的矩阵。
a + b- 1

1.4 索引和切片
我们可以使用[-1]选择最后一个元素,可以用[1:3]选择第二个和第三个元素:
X[-1], X[1:3]- 1

我们还可以通过索引的方式将单个元素写入矩阵:
X[1,2] = 9 X- 1
- 2

我们还可以通过这种方式为多个元素赋予相同的值,只需索引所有元素,如:
X[0:2, :] = 12 # 本例代表访问第1行和第2行,其中":"代表沿轴(列)的所有元素 X- 1
- 2

以上方法均适用于超过2个轴的其他类型的张量。
1.5 节省内存
当我们执行
Y = Y + X操作后,Python会首先计算Y + X,为结果分配新的内存,然后使Y指向内存中的这个新位置。这是不可取的:
- 机器学习中,可能有数百兆参数,我们希望原地执行这些更新。
- 若不原地更新,其他引用可能仍会指向旧的位置,可能会无形中引用旧的参数。
执行原地操作的方法很简单,可以使用切片操作执行。如
Y[:]=我们可以先创建一个新的矩阵Z,其为全零矩阵,与先前X的形状相同,然后比较其ID:
print('id(Z):', id(Z)) # id(Z): 2502249091776 Z[:] = X + X print('id(Z):', id(Z)) # id(Z): 2502249091776- 1
- 2
- 3
- 4
- 5

1.6 转化为其他Python对象
将张量在torch框架与numpy框架间转换很容易,它们将共享底层内存,就地操作一个也会改变另一个张量。
A = X.numpy() B = torch.tensor(A) type(A), type(B) # (, ) - 1
- 2
- 3
- 4

将大小为1的张量转化为Python标量,有多种方法:
a = torch.tensor([3.5]) a, a.item(), float(a), int(a) # (tensor([3.5000]), 3.5, 3.5, 3)- 1
- 2
- 3

2. 数据预处理
2.1 读取数据集
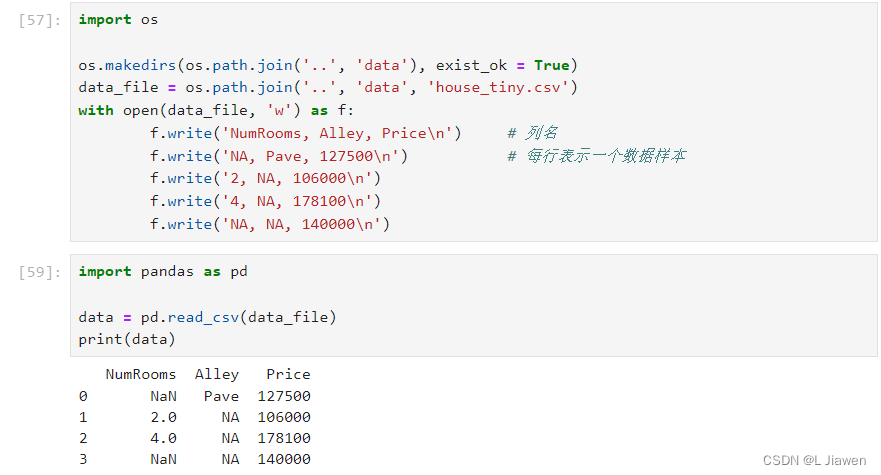
我们先创建一个数据集,并按行写入CSV文件中:
import os os.makedirs(os.path.join('..', 'data'), exist_ok = True) data_file = os.path.join('..', 'data', 'house_tiny.csv') with open(data_file, 'w') as f: f.write('NumRooms, Alley, Price\n') # 列名 f.write('NA, Pave, 127500\n') # 每行表示一个数据样本 f.write('2, NA, 106000\n') f.write('4, NA, 178100\n') f.write('NA, NA, 140000\n')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
随后导入pandas包,并调用read_csv函数
import pandas as pd data = pd.read_csv(data_file) print(data)- 1
- 2
- 3
- 4
2.2 处理缺失值
NaN代表缺失值,处理的典型方法包括插值法和删除法,插值法即用替代值弥补,删除法则忽视缺失值。
本例中,我们采用插值法。
通过位置索引函数
iloc将数据分成inputs和outputs,其中inputs为data前两列,outputs为最后一列。fillna函数可以使用传入参数值代替NaN缺失值,而mean函数可以求得其对应的平均值。inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2] inputs = inputs.fillna(inputs.mean()) print(inputs)- 1
- 2
- 3
iloc函数,属于pandas库,全称为index location,即对数据进行位置索引,从而在数据表中提取出相应的数据。
对于inputs中的类别值或离散值,NaN可视作一个类别,而NA被视为字符串。由于Alley列有NA、Pave和NaN三个类别,Pandas可自动将其分为三列
Alley_NA、Alley_Pave和Alley_nan。值激活为1,不激活为0。inputs = pd.get_dummies(inputs, dummy_na=True) print(inputs)- 1
- 2
pd.get_dummies相当于onehot编码,常用与把离散的类别信息转化为onehot编码形式。

2.3 转换为张量格式
通过调用
type函数,我们发现pandas及分割后的数据均为我们可调用
tneser函数将上述类型的数据转化为PyTorch张量(即import torch X, y = torch.tensor(inputs.values), torch.tensor(outputs.values) X, y- 1
- 2
- 3
- 4

-
相关阅读:
一台服务器成了哆啦A梦的神奇口袋
【JavaScript】video标签配置及相关事件:
数据结构- 树
C/C++语言100题练习计划 74——全排列问题(借助STL实现)
Windows中的用户帐户与组账户
我的 Kafka 旅程 - 文件存储机制
青龙脚本分享(不断更新完善)
国赛练习(1)
BeanFactory和FactoryBean的区别
docker理论+部署(一)
- 原文地址:https://blog.csdn.net/Bitter_Li/article/details/133997243