-
大语言模型(LLM)综述(二):开发大语言模型的公开可用资源
前言
随着人工智能和机器学习领域的迅速发展,语言模型已经从简单的词袋模型(Bag-of-Words)和N-gram模型演变为更为复杂和强大的神经网络模型。在这一进程中,大型语言模型(LLM)尤为引人注目,它们不仅在自然语言处理(NLP)任务中表现出色,而且在各种跨领域应用中也展示了惊人的潜力。从生成文本和对话系统到更为复杂的任务,如文本摘要、机器翻译和情感分析,LLM正在逐渐改变我们与数字世界的互动方式。
然而,随着模型规模的增加,也出现了一系列挑战和问题,包括但不限于计算复杂性、数据偏见以及模型可解释性。因此,对这些模型进行全面而深入的了解变得至关重要。
本博客旨在提供一个全面的大型语言模型综述,探讨其工作原理、应用范围、优点与局限,以及未来的发展趋势。无论您是该领域的研究者、开发者,还是对人工智能有广泛兴趣的读者,这篇综述都将为您提供宝贵的洞见。
本系列文章内容大部分来自论文《A Survey of Large Language Models》,旨在使读者对大模型系列有一个比较程序化的认识。
论文地址:https://arxiv.org/abs/2303.18223
3. RESOURCES OF LLMS
开发或复制大型语言模型(LLMs)绝非易事,考虑到复杂的技术问题和庞大的计算资源需求。一种可行的方法是从现有的LLMs中学习经验,并重复使用公开可用的资源来进行增量开发或实验研究。在本节中,我们将简要总结用于开发LLMs的公开可用资源,包括模型检查点(或API)、语料库和库文件。
3.1 公开可用的模型CheckPoints或 API
考虑到模型预训练的巨大成本,经过良好训练的模型检查点对于研究界开发LLMs至关重要。由于参数规模是使用LLMs时需要考虑的关键因素,我们将这些公开模型分为两个规模级别(即数百亿参数和数千亿参数),这有助于用户根据其资源预算来确定合适的资源。此外,对于推断任务,我们可以直接使用公开API执行任务,而无需在本地运行模型。接下来,我们将介绍公开可用的模型检查点和API。
100亿(10B)参数级别模型
在这个类别中,大多数模型的参数规模介于10亿到20亿之间,除了LLaMA [57]和LLaMA2 [90](最大版本包含70亿参数),NLLB [82](最大版本包含54.5亿参数),以及Falcon [121](最大版本包含40亿参数)。该范围内的其他模型包括mT5 [74],PanGu-α [75],T0 [28],GPT-NeoX-20B [78],CodeGen [77],UL2 [80],Flan-T5 [64]和mT0 [85]。其中,FlanT5(11B版本)可以作为研究指导调整的首选模型,因为它从三个方面探索了指导调整:增加任务数量,扩大模型规模,以及使用链式思考提示数据进行微调 [64]。此外,CodeGen(11B版本)作为一个用于生成代码的自回归语言模型,可以被认为是探索代码生成能力的良好选择。它还引入了一个新的基准测试MTPB [77],专门用于多轮程序合成,由115个专家生成的问题组成。为了解决这些问题,需要LLMs获得足够的编程知识(如数学、数组操作和算法)。最近,CodeGen2 [88]已经发布,以探索模型架构、学习算法和数据分布选择对模型的影响。作为另一个专注于编码能力的LLM,StarCoder [89]也取得了出色的成绩。对于多语言任务,mT0(13B版本)可能是一个不错的候选模型,它已经在多语言任务和多语言提示上进行了微调。此外,基于深度学习框架MindSpore [122]开发的PanGu-α [75]在零样本或少样本设置下在中文下游任务中表现良好。请注意,PanGu-α [75]拥有多个版本的模型(最多达到200亿参数),而最大的公开版本有13亿参数。作为一款受欢迎的LLM,LLaMA(65B版本)[57]拥有约五倍于其他模型的参数,在涉及指令遵循的任务中表现出卓越性能。与LLaMA相比,LLaMA2 [90]在人类反馈强化学习(RLHF)方面进行了更多的探索,并开发了一个面向聊天的版本,称为LLaMA-chat,在一系列有用性和安全性基准测试中通常优于现有的开源模型。由于其开放性和有效性,LLaMA引起了研究界的广泛关注,许多工作 [123–126]已经致力于微调或不断预训练其不同的模型版本,以实现新模型或工具的实施。最近,另一款开源LLM Falcon [121]也在开放基准测试中取得了非常出色的表现。它的特点是更加谨慎的数据清理过程,用于准备预训练数据(使用公开共享的数据集RefinedWeb [127])。通常,在这个规模下进行预训练模型需要数百甚至数千个GPU或TPU。例如,GPT-NeoX-20B使用12台超微服务器,每台配备8个NVIDIA A100-SXM4-40GB GPU,而LLaMA据其原始出版物报道使用了2,048个A100-80G GPU。为了准确估计所需的计算资源,建议使用衡量涉及计算数量的指标,例如FLOPS(即每秒浮点数操作数)[30]。
1000亿(100B)参数级别模型
在这个类别的模型中,只有少数几个模型已经公开发布。例如,OPT [81],OPT-IML [86],BLOOM [69]和BLOOMZ [85]的参数数量几乎与GPT-3(175B版本)相同,而GLM [84]和Galactica [35]分别有130B和120B的参数。其中,OPT(175B版本)以及专为开放共享而推出的instruction-tuned版本OPT-IML,旨在使研究人员能够进行可重复研究。对于跨语言通用化研究,由于在多语言语言建模任务中的竞争力,BLOOM(176B版本)和BLOOMZ(176B版本)可以作为基础模型使用。作为一款双语LLM,GLM还提供了一款受欢迎的小型中文聊天模型ChatGLM2-6B(ChatGLM-6B的升级版本),具有在效率和容量方面的许多改进(例如量化、32K长度上下文、快速推理速度)。这个规模的模型通常需要成千上万个GPU或TPU来训练。例如,OPT(175B版本)使用了992个A100-80GB GPU,而GLM(130B版本)使用了一个包含96个NVIDIA DGX-A100(8x40G)GPU节点的集群。
LLaMA模型系列
Meta AI在2023年2月推出了LLaMA模型系列[57],包括四个规模(7B,13B,30B和65B)。自发布以来,LLaMA引起了研究界和工业界的广泛关注。LLaMA模型在各种开放基准测试中表现出非常出色的性能,成为迄今为止最受欢迎的开放语言模型。许多研究人员通过指导调整或持续预训练来扩展LLaMA模型。特别是,由于相对较低的计算成本,指导调整LLaMA已成为开发定制或专业模型的主要方法之一。为了有效地在非英语语言中适应LLaMA模型,通常需要扩展原始词汇表(主要基于英语语料库训练)或使用目标语言中的指导或数据进行微调。在这些扩展模型中,Stanford Alpaca [128]是第一个基于LLaMA(7B)进行精细调整的开放指导模型。它是通过使用text-davinci-003生成的52K个指导示范来进行训练的。指导数据名为Alpaca-52K,训练代码已广泛用于后续工作,如AlpacaLoRA [130](使用LoRA [131]复制的Stanford Alpaca),Koala [132]和BELLE [133]。此外,Vicuna [124]是另一种流行的LLaMA变体,是基于来自ShareGPT的用户共享对话进行训练的。由于LLaMA模型系列的出色性能和可用性,许多多模态模型将它们作为基础语言模型,以实现强大的语言理解和生成能力。与其他变体相比,Vicuna在多模态语言模型中更受欢迎,这导致了许多受欢迎模型的出现,包括LLaVA [134],MiniGPT4 [135],InstructBLIP [136]和PandaGPT [137]。LLaMA的发布极大推动了LLM研究的进展。为了总结在LLaMA上进行的研究工作,我们在图4中呈现了一个简要的演化图。
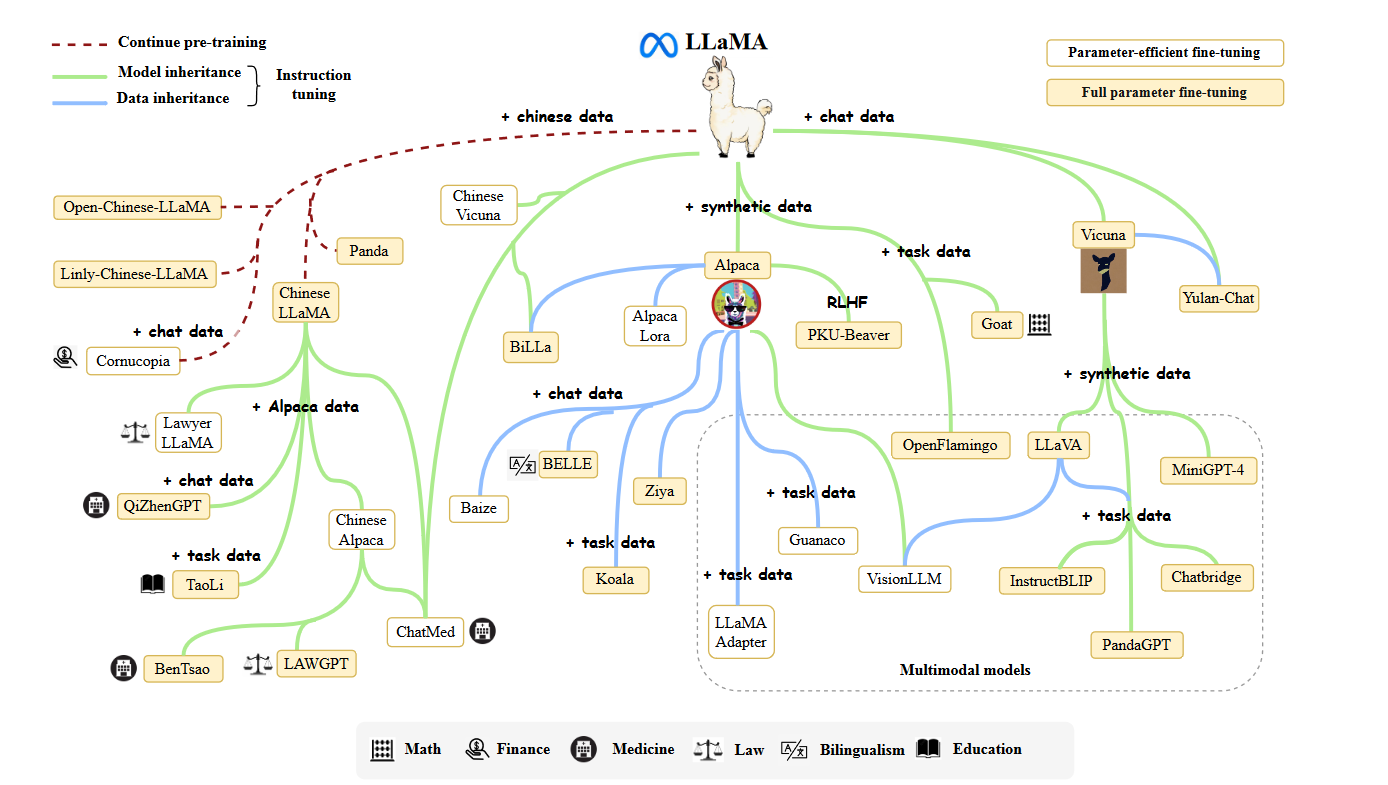
图 4:LLaMA 研究工作的演化图。由于数量巨大,我们无法在此图中包含所有 LLaMA 变体,即使是很多优秀的作品。
公开的大语言模型API
与直接使用模型副本相比,API提供了一个更便捷的方式,使普通用户能够使用LLMs,而无需在本地运行模型。作为使用LLMs的代表性接口,GPT系列模型[46, 55, 61, 92]的API已广泛用于学术界和工业界17。OpenAI为GPT-3系列模型提供了七个主要的接口:ada,babbage,curie,davinci(GPT-3系列中最强大的版本),text-ada-001,text-babbage-001和text-curie-001。其中,前四个接口可以在OpenAI的主机服务器上进一步进行微调。特别是,babbage,curie和davinci分别对应于GPT-3(1B),GPT-3(6.7B)和GPT-3(175B)模型[55]。此外,还有两个与Codex [92]相关的API,称为code-cushman-001(Codex(12B)的强大和多语言版本[92])和code-davinci-002。此外,GPT-3.5系列包括一个基础模型code-davinci-002和三个增强版本,即text-davinci-002,text-davinci-003和gpt-3.5-turbo-0301。值得注意的是,gpt-3.5-turbo-0301是调用ChatGPT的接口。最近,OpenAI还发布了GPT-4的相应API,包括gpt-4,gpt-4-0314,gpt-4-32k和gpt-4-32k-0314。总的来说,API接口的选择取决于具体的应用场景和响应要求。详细的使用说明可以在它们的项目网站上找到。
3.2 常用语料库
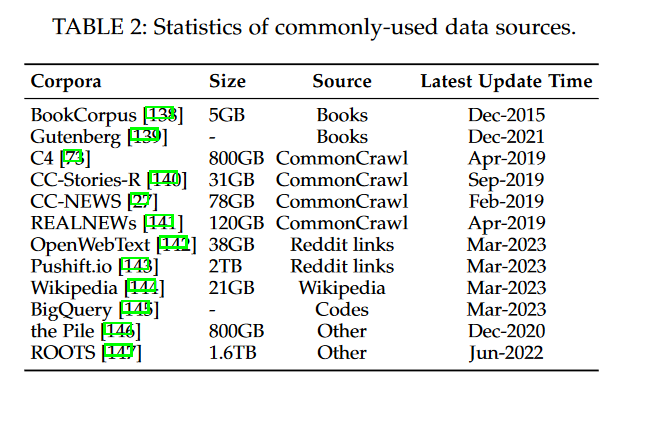
相对于早期的PLMs,包含大量参数的LLMs需要更多的训练数据,涵盖了广泛的内容范围。为了满足这个需求,越来越多的可访问的训练数据集已经发布供研究使用。在本节中,我们将简要总结用于训练LLMs的几个广泛使用的语料库。根据它们的内容类型,我们将这些语料库分为六组:书籍、CommonCrawl、Reddit链接、维基百科、代码和其他。
书籍
BookCorpus [138]是以前小规模模型(例如,GPT [109]和GPT-2 [26])中常用的数据集,包括超过11,000本涵盖广泛主题和类型(例如小说和传记)的书籍。另一个大规模的书籍语料库是Project Gutenberg [139],包括超过70,000本文学作品,包括小说、散文、诗歌、戏剧、历史、科学、哲学和其他类型的公共领域作品。它目前是最大的开源书籍集合之一,用于MT-NLG [100]和LLaMA [57]的训练。至于GPT-3 [55]中使用的Books1 [55]和Books2 [55],它们比BookCorpus要大得多,但目前尚未公开发布。
CommonCrawl.
CommonCrawl [148]是最大的开源网络爬取数据库之一,包含PB级别的数据量,已被广泛用作现有LLMs的训练数据。由于整个数据集非常大,现有的研究主要从中提取特定时期的网页子集。然而,由于网络数据中存在大量嘈杂和低质量信息,因此在使用之前需要进行数据预处理。基于CommonCrawl,有四个常用于现有工作的经过筛选的数据集:C4 [73],CCStories [140],CC-News [27]和RealNews [141]。巨大的干净爬虫语料库(C4)包括五个变种19,分别是en(806G),en.noclean(6T),realnewslike(36G),webtextlike(17G)和multilingual(38T)。en版本已被用于T5 [73]、LaMDA [63]、Gopher [59]和UL2 [80]的预训练。多语言的C4,也称为mC4,已被用于mT5 [74]。CC-Stories(31G)由CommonCrawl数据的子集组成,其中内容以故事方式呈现。由于CC-Stories的原始来源目前不可用,我们在表2中包含了一个复制版本,即CC-Stories-R [149]。此外,从CommonCrawl中提取的两个新闻语料库,即REALNEWS(120G)和CC-News(76G),也常用作预训练数据。
Reddit链接
Reddit是一个社交媒体平台,允许用户提交链接和文本帖子,其他用户可以通过“赞成”或“反对”来投票。被高度赞成的帖子通常被认为很有用,并可以用来创建高质量的数据集。WebText [26]是一个众所周知的语料库,由Reddit上被高度赞成的链接组成,但它并没有公开发布。作为替代,有一个易于访问的开源替代品,称为OpenWebText [142]。从Reddit中提取的另一个语料库是PushShift.io [143],这是一个实时更新的数据集,包含了Reddit自创建以来的历史数据。Pushshift不仅提供每月的数据转储,还提供有用的实用工具,支持用户在整个数据集上进行搜索、摘要和初步调查。这使得用户可以轻松地收集和处理Reddit数据。
维基百科
维基百科[144]是一个在线百科全书,包含大量关于各种主题的高质量文章。这些文章大多以解释性的写作风格(附有支持参考文献)编写,涵盖了多种语言和领域。通常,维基百科的仅英语筛选版本在大多数LLMs中被广泛使用(例如,GPT-3 [55],LaMDA [63]和LLaMA [57])。维基百科提供多种语言版本,因此可以在多语言环境中使用。
代码
为了收集代码数据,现有的工作主要从互联网上爬取具有开源许可的代码。两个主要来源是开源许可的公共代码存储库(例如GitHub)和与代码相关的问答平台(例如StackOverflow)。Google已经公开发布了BigQuery数据集[145],其中包含各种编程语言中的大量开源许可的代码片段,作为代表性的代码数据集。CodeGen已经利用了BigQuery数据集的一个子集BIGQUERY [77],用于训练CodeGen的多语言版本(CodeGen-Multi)。
其他
Pile [146]是一个大规模、多样化且开源的文本数据集,包括来自多个来源的800多GB数据,包括书籍、网站、代码、科学论文和社交媒体平台。它由22个多样化的高质量子集构成。Pile数据集被广泛用于不同参数规模的模型,例如GPT-J(6B)[150],CodeGen(16B)[77]和Megatron-Turing NLG(530B)[100]。ROOTS [147]由各种较小的数据集组成(共计1.61 TB的文本),涵盖了59种不同的语言(包括自然语言和编程语言),已被用于训练BLOOM [69]。
在实际应用中,通常需要混合不同的数据源来进行LLMs的预训练(见图5),而不是单一的语料库。因此,现有研究通常混合几个现成的数据集(例如C4、OpenWebText和Pile),然后进行进一步的处理以获取预训练语料库。此外,为了训练适用于特定应用的LLMs,从相关来源(例如维基百科和BigQuery)提取数据以丰富预训练数据中的相应信息也非常重要。为了快速查看现有LLMs中使用的数据源,我们展示了三个代表性LLMs的预训练语料库:
• GPT-3 (175B) [55] 在一个混合数据集上进行了训练,包括300B Tokens,其中包括CommonCrawl [148]、WebText2 [55]、Books1 [55]、Books2 [55]和Wikipedia [144]。
• PaLM (540B) [56] 使用了一个预训练数据集,包含780B Tokens,数据源包括社交媒体对话、筛选的网页、书籍、GitHub、多语言维基百科和新闻。
• LLaMA [57] 从各种来源中提取训练数据,包括CommonCrawl、C4 [73]、GitHub、维基百科、书籍、ArXiv和StackExchange。LLaMA (6B) 和 LLaMA (13B) 的训练数据大小为1.0T Token,而LLaMA (32B) 和LLaMA (65B) 使用了1.4T Tokens。
3.3 库资源
在这一部分中,我们简要介绍了一系列用于开发 LLM 的可用库。
• Transformers [151] 是一个由Hugging Face开发和维护的用于构建使用Transformer架构的模型的开源Python库。它具有简单且用户友好的API,使得使用和定制各种预训练模型变得容易。这是一个功能强大的库,拥有庞大而活跃的用户和开发者社区,他们定期更新和改进模型和算法。
• DeepSpeed [65] 是由微软开发的深度学习优化库(与PyTorch兼容),已被用于训练多个LLMs,例如MTNLG [100] 和BLOOM [69]。它提供了各种优化技术的支持,用于分布式训练,如内存优化(ZeRO技术、梯度检查点)和流水线并行。
• Megatron-LM [66–68] 是由NVIDIA开发的用于训练大规模语言模型的深度学习库。它还提供了丰富的分布式训练优化技术,包括模型和数据并行、混合精度训练和FlashAttention。这些优化技术可以极大地提高训练效率和速度,实现了在多个GPU上的高效分布式训练。
• JAX [152] 是由Google开发的用于高性能机器学习算法的Python库,允许用户在具有硬件加速(例如GPU或TPU)的数组上轻松执行计算。它支持在各种设备上进行高效计算,还支持一些特色功能,如自动微分和即时编译。
• Colossal-AI [153] 是由HPC-AI Tech开发的深度学习库,用于训练大规模AI模型。它是基于PyTorch实现的,并支持丰富的并行训练策略。此外,它还可以通过PatrickStar [154]提出的方法优化异构内存管理。最近,基于LLaMA [57],使用Colossal-AI开发的ColossalChat [126]已经公开发布了两个版本(7B和13B),这是一个类似于ChatGPT的模型。
• BMTrain [155] 是由OpenBMB开发的一个高效的库,用于以分布式方式训练具有大规模参数的模型,强调代码简单性、低资源和高可用性。BMTrain已经将一些常见的LLMs(例如Flan-T5 [64]和GLM [84])纳入其ModelCenter中,开发人员可以直接使用这些模型。
• FastMoE [156] 是MoE(即专家混合)模型的专用训练库。它是基于PyTorch开发的,在设计中注重效率和用户友好性。FastMoE简化了将Transformer模型转换为MoE模型的过程,并支持在训练过程中的数据并行和模型并行。
除了上述库资源外,现有的深度学习框架(例如,PyTorch [157]、TensorFlow [158]、MXNet [159]、PaddlePaddle [160]、MindSpore [122] 和 OneFlow [161])也提供了支持用于并行算法,通常用于训练大型模型。
-
相关阅读:
新手小白前端学习艰辛之路
【perl】环境搭建
ubuntu 给meld加上右键菜单
Jetson查看JetPack版本(tool)
接口文档生成工具JAPiDocs
Nginz静态资源缓存
初识多线程
实战!工作中常用的设计模式
C++ —— Tinyxml2在Vs2017下相关使用2(较文1更复杂,附源码)
【安全】经典面试题总结-史上最全面试题思维导图总结(2022最新版)
- 原文地址:https://blog.csdn.net/qq_51957239/article/details/133970536