-
python爬虫语法
注释
变量类型
和java不同不需要定义数据类型 变量名=变量值
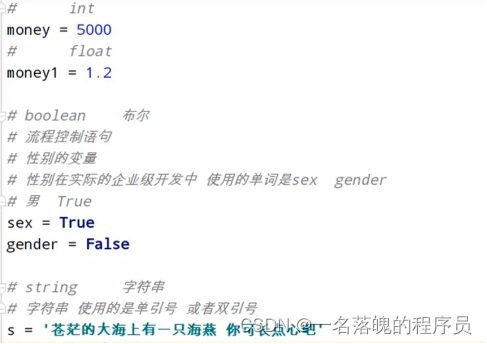
Numbers(数字):int(有符号整型)、long(长整型[也可以代表八进制和16进制])、float(浮点型)、complex(复数)
布尔类型:True、False
String(字符串)
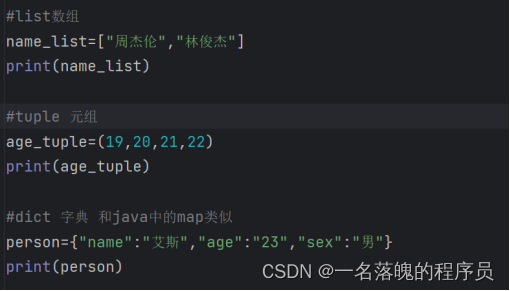
List(列表) 获取下标list[0]
Tuple(元组)
Dictionary(字典)
查看数据类型 type(变量)

类型转换
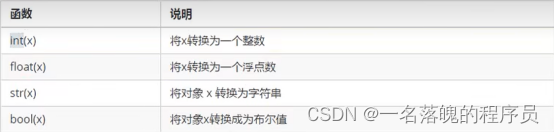
bool类型转换对非0的都是true,字符串、列表、元组、字典为空bool类型转换为false运算符

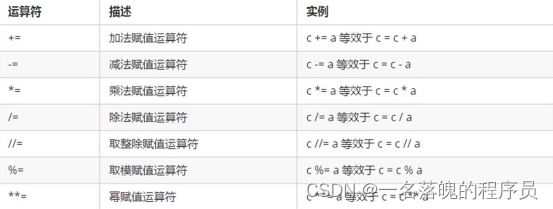
赋值运算符
单变量赋值:a=10、b=c=20 b=20、c=20
多变量赋值:d,e,f=1,2,3 d=1、e=2、f=3复合赋值运算符
比较运算符

逻辑运算符

输入(返回的值默认是str)
password=input(“请输入密码”)
print(password)输出为:
请输入密码8888
8888格式化输出
%s 代表的是字符串 %d 代表的是数值
age=18
name=”ssosn”
print(“我的名字是%s,我的年龄是%d” % (name,age))输出为:我的名字是ssosn,我的年龄是18
流程控制语句
if
if 判断条件:
代码(判断条件为true执行的内容)- 1
else:
判断条件为false执行的内容- 1
if 判断条件:
代码(判断条件为true执行的内容)- 1
elif 判断条件:
代码(判断条件为true执行的内容)- 1
else:
以上if判断条件均为false执行的内容- 1
for
for 变量 in 要遍历的数据:
方法体- 1

range(左闭右开区间)
range(起始值,结束值,步长)for i in range(5):
print(i) #输出:0 1 2 3 4- 1
for i in range(1,5):
print(i) #输出:1 2 3 4- 1
for i in range(1,5,2):
print(i) #输出:1 3- 1
可通过遍历列表下标:
a_list=[“周杰伦”,”林俊杰”,”许嵩”]
for i in range(len(a_list)):print(i) #输出数组下标:0 1 2- 1
字符串高级
获取长度:len len函数可以获取字符串的长度。

输出:5查找内容:find 查找指定内容在字符串中是否存在,如果存在就返回该内容在字符串中第一次出现的开始位置索引值,如果不存在,则返回-1.

输出:4判断:startswith,endswith 判断字符串是不是以谁谁谁开头/结尾计算对应true/false

输出:false false出现次数:count返回 str在start和end之间 在 mystr里面出现的次数

输出:2替换内容:replace 替换字符串中指定的内容,如果指定次数count,则替换不会超过count次。

输出:ddddd切割字符串:split 通过参数的内容切割字符串

输出:[‘1’,’2’,’3’]修改大小写:upper,lower 将字符串中的大小写互换

输出:china空格处理:strip 去空格

输出:1字符串拼接:join 字符串拼接

输出:haealalao列表高级 []


列表查找


列表删除
del:根据列表下标进行删除
a_list=[1,2,3,4]
del a_list[2]输出:[1,2,4]
pop:删除列表中的最后一个元素
a_list=[1,2,3,4]
a_list.pop()输出:[1,2,3]
remove:根据元素的值进行删除
a_list=[1,2,3,4]
a_list.remove(3)输出:[1,2,4]
元组高级 ()
元组的元素不能修改,列表的元素可以修改
a_tuple=(1,2,3,4)
通过下标获取值
a_tuple[0]
#元组中的元素只有一个,那么踏实整型数据
#定义只有一个元素的元组,需要在卫衣的元素后写一个逗号a_tuple=(5,)a_tuple=(5)
print(type(a_tuple))切片
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作
切片的语法:[起始:结束:步长]

示例:获取字符串最后四位rs=“asdsa/ddsad/sssss.jpg”
rs=rs[-4:]
print(rs)或者使用
rs = “asdsa/ddsad/sssss.jpg”
dot_index = rs.rfind(“.”) # 找到最后一个"."
suffix = rs[dot_index:] # 获取".后面的数据"
print(suffix)
字典高级 {}(类似java中的map)
查看元素


修改元素
字典的每个元素中的数据是可以修改的,只要通过key找到,即可修改

添加元素

删除元素

del删除整个字典
del info

clear删除整个字典del clear() #清空指的是将字典中的所有数据都删除掉,保留字典的结构

字典遍历
1:遍历字典的keyfor key in info.keys():
print(key)2:遍历字典的value
for value in info.values():
print(value)3:遍历字典的key/value
for key,value in info.items():
print(key,value)4:遍历字典的项或者元素 ”name”:”monitor” 就是一个项或者元素
for item in info.items():
print(item)函数的定义和调用
函数定义def 函数名(参数名):
代码- 1
函数调用
#关键字传参
sum(b=200,a=100)
函数返回值

文件
打开/创建文件
访问模式:w(可写)r(可读)a(在原来的基础上追加)
fp=open(“test.txt”,“w”)
或者
with open(“douban.json”,“w”,encoding=“utf-8”) as fr:
fr.write(“内容”);写入内容 如果文件存在会覆盖原来的数据
fp.write(“hello world”*5)
#文件的关闭
fp.close()

读取文件
访问模式:w(可写) r(可读) a(在原来的基础上追加)
fp=open(“test.txt”,“r”)
或者with open(“douban.json”,“r”,encoding=“utf-8”) as fr:
content=fr.read();- 1
readlines按照行读取,会以列表的形式返回,每个下标就是一行的数据
readline读取第一行的数据
content=fp.readline()
print(content)序列化和反序列化
通过文件操作,我们可以将字符串写入到一个本地文件。但是,如果是一个对象(例如列表、字典、元组等),就无法直接写入到一个文件里,需要对这个对象进行序列化,然后才能写入到文件里。
设计一套协议,按照某种规则,把内存中的数据转换为字节序列,保存到文件,这就是序列化,反之,从文件的字节序列恢复到内存中,就是反序列化。
对象—》字节序列=序列化字节序列–》对象=反序列化
Python中提供了JSON这个模块用来实现数据的序列化和反序列化。序列化
导入json模块到该文件中
import json
名称数组
name_list=[“zs”,“ls”,“ww”]
创建文件
fp=open(“test.txt”,“w”)
dump:相当于json.dumps(name_list) 和 fp.write(names) 写法:json.dump(name_list,fp)
dumps:在使用scrapy框架时,框架会返回一个对象 我们要将对象写入到文件中 就要使用json.dumps
names=json.dumps(name_list)
写入文件
fp.write(names)
关闭文件
fp.close()
反序列化
导入json模块到该文件中
import json
将json的字符串变成一个python对象
fp=open(“test.txt”,“r”)
#读取文件
content=fp.read()
#将字符串变成python对象 loads
#load:相当于content=fp.read() 和 json.loads(content) 写法 result=json.load(fp)
result=json.loads(content)关闭文件
fp.close()
print(“变化之前%s,类型%s” % (content,type(content)))
print(“变化之后%s,类型%s” % (result,type(result)))异常捕获
#异常的格式
try:
可能出现异常的代码
except 异常的类型:
异常提示

编码问题
将\u格式的unicode转换成中文
支持‘/’这样的转义序列content = content.encode(‘utf-8’).decode(‘raw_unicode_escape’)
不支持‘/’这样的转义序列
content = content.encode(‘utf-8’).decode(‘unicode_escape’)
字符串解码报错问题
utf-8没有办法对这个字符串进行解码,因为没有合适的字符映射到该编码,大部分问题出现在字符串中存在类似\uD83C\uDF1D这种以\u开头的字符串,python会认为这是一个unicode编码,于是想办法把它解码成一个字符串,但发现编码映射表中没有这样的字符与之对应(可能这个编码是一个emoji表情)#print(s) 直接打印输出会报以上错误,需要进行替换,意思是遇到不可unicode解码的字符,就用?替换
s2 = s.encode(‘utf-8’, ‘replace’).decode()
因为encode的函数原型是encode([encoding], [errors=‘strict’]),可以用第二个参数控制错误处理的策略,默认的参数就是strict,代表遇到非法字符时抛出异常;
如果设置为ignore,则会忽略非法字符;
如果设置为replace,则会用?取代非法字符;
如果设置为xmlcharrefreplace,则使用XML的字符引用。 -
相关阅读:
基于单片机的汽车防盗报警系统设计与实现
cv::Mat 的常见操作方法
ERROR 6400 --- [ main] com.zaxxer.hikari.pool.HikariPool : root - Exception
使用C语言实现双向链表(带头结点)
R语言顶级期刊配色
【网络安全】使用meterpreter进行远控、Mysql注入、反弹型XSS攻防
0门槛!用ChatGPT只花1天批量生成300个爆火TikTok视频
【爬虫实战】利用代理爬取电商数据
百度 T4 幕后揭秘!这份 Java 面试全栈手册竟让面试官节节败退
游戏模板:MFPS 2.0: Multiplayer FPS
- 原文地址:https://blog.csdn.net/pengxiaozhong/article/details/133976434