-
MySQL 排名函数 RANK, DENSE_RANK, ROW_NUMBER
1 排名函数有哪些?
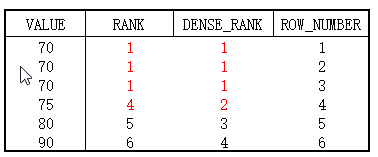
- RANK(): 并列跳跃排名, 并列即相同的值, 相同的值保留重复名次, 遇到下一个不同值时, 跳跃到总共的排名
- DENSE_RANK(): 并列连续排序, 并列即相同的值, 相同的值保留重复名次, 遇到下一个不同值时, 依然按照连续数字排名
- ROW_NUMBER(): 连续排名, 即使相同的值, 依旧按照连续数字进行排名
RANK, DENSE_RANK, ROW_NUMBER 函数在查询结果上的区别
2 SQL 代码实现
t_scores 表
+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | score | decimal | +-------------+---------+- 1
- 2
- 3
- 4
- 5
- 6
在 SQL 中, id 是该表的主键
该表的每一行都包含了一场比赛的分数, score 是一个有两位小数点的浮点值2.1 RANK
RANK(): 并列跳跃排名, 并列即相同的值, 相同的值保留重复名次, 遇到下一个不同值时, 跳跃到总共的排名
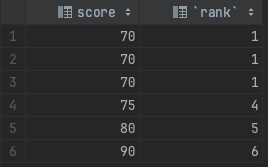
RANK() OVER(ORDER BY score DESC)对 score 字段升序排序, 进行排名SELECT score, RANK() OVER(ORDER BY score ASC) as "rank" FROM t_scores;- 1
查询结果:
2.2 DENSE_RANK
DENSE_RANK(): 并列连续排序, 并列即相同的值, 相同的值保留重复名次, 遇到下一个不同值时, 依然按照连续数字排名
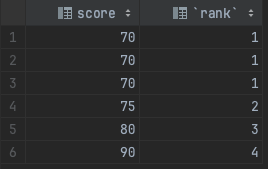
SELECT score, DENSE_RANK() OVER(ORDER BY score ASC) as "rank" FROM t_scores;- 1
查询结果:
2.3 ROW_NUMBER
ROW_NUMBER(): 连续排名, 即使相同的值, 依旧按照连续数字进行排名
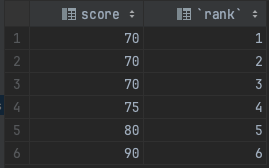
SELECT score, ROW_NUMBER() OVER(ORDER BY score ASC) as "rank" FROM t_scores;- 1
查询结果:
2.4 OVER
函数语法
OVER (PARTITION BY (expr) ORDER BY (expr))- 1
思路: 按照部门统计, 前三高薪水的员工信息, 需要用到排名函数, 需要保持排名的连续性, 结合
partition by e.departmentId按部门统计dense_rank() over(partition by e.departmentId order by e.salary desc)- 1
Employee 表:
+----+-------+--------+--------------+ | id | name | salary | departmentId | +----+-------+--------+--------------+ | 1 | Joe | 85000 | 1 | | 2 | Henry | 80000 | 2 | | 3 | Sam | 60000 | 2 | | 4 | Max | 90000 | 1 | | 5 | Janet | 69000 | 1 | | 6 | Randy | 85000 | 1 | | 7 | Will | 70000 | 1 | +----+-------+--------+--------------+- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Department 表:
+----+-------+ | id | name | +----+-------+ | 1 | IT | | 2 | Sales | +----+-------+- 1
- 2
- 3
- 4
- 5
- 6
输出:
+------------+----------+--------+ | Department | Employee | Salary | +------------+----------+--------+ | IT | Max | 90000 | | IT | Joe | 85000 | | IT | Randy | 85000 | | IT | Will | 70000 | | Sales | Henry | 80000 | | Sales | Sam | 60000 | +------------+----------+--------+- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
最终SQL
select ed.Department, ed.Employee, ed.Salary from (select d.name as Department, e.name as Employee, e.salary as Salary, dense_rank() over(partition by e.departmentId order by e.salary desc) as denseRank from Employee as e inner join Department as d on e.departmentId = d.id) ed where ed.denseRank <= 3- 1
- 2
- 3
- 4
- 5
-
相关阅读:
(1) 初识QT5
黑暗爆炸 #1059. [ZJOI2007]矩阵游戏
OpenFunction v0.8.0 发布:通过 Dapr Proxy 加速函数启动
vue antv g6 编辑器
C++——异常
CentOS7图文详细安装教程
js...
浮点数计算精度问题decimal.js
Servlet 技术
vue项目问题记录 pdf.js解决跨域问题 版本v2.16.105
- 原文地址:https://blog.csdn.net/weixin_57672329/article/details/133971569