-
macrodata数据集在Python统计建模和计量经济学中的应用
一、数据介绍
macrodata.csv是一个示例数据集,通常用于统计分析和计量经济学中的教育和训练目的。这个数据集通常包括以下列:
year(年份):表示数据观察的年份。
quarter(季度):表示数据观察的季度(通常是1至4)。
realgdp(实际国内生产总值):表示实际国内生产总值的数值,通常以美元为单位。
realcons(实际消费支出):表示实际消费支出的数值,通常以美元为单位。
realinv(实际投资支出):表示实际投资支出的数值,通常以美元为单位。
realgovt(实际政府支出):表示实际政府支出的数值,通常以美元为单位。
realdpi(实际可支配个人收入):表示实际可支配个人收入的数值,通常以美元为单位。
cpi(消费者物价指数):表示消费者物价指数的数值。
m1(货币供应量M1):表示M1货币供应量的数值。
tbilrate(国债利率):表示国债利率的数值。
unemp(失业率):表示失业率的百分比。
pop(人口):表示总人口数。
这些列通常用于经济数据分析和时间序列分析,以探讨宏观经济现象和趋势。您可以使用统计分析软件(例如Python中的Pandas和Statsmodels库)来导入和分析这些数据,以获取有关经济变量之间关系的见解。
下面进行可视化分析案例实现展示:
所需安装模块:
pip install numpy matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple pandas- 1
- 2
示例代码:
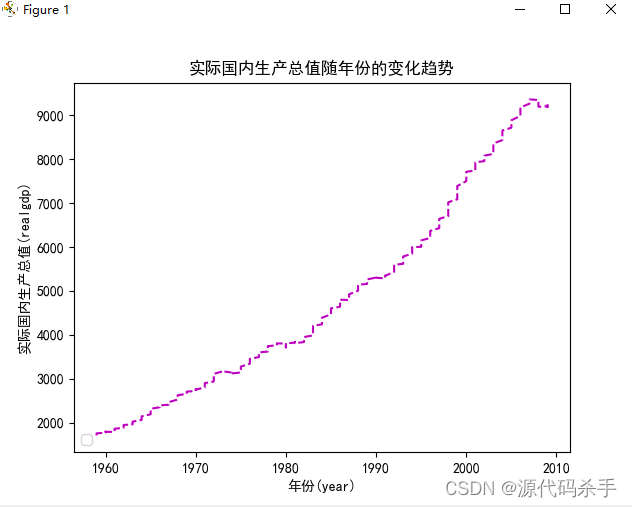
import numpy as np import pandas as pd import matplotlib.pyplot as plt plt.rcParams['axes.unicode_minus'] = False #解决坐标轴刻度负号乱码 plt.rcParams['font.sans-serif'] = ['Simhei'] #设置中文显示,字体为黑体 import pandas as pd data = pd.read_csv("macrodata.csv") print(data) # print(data['year'].values) # print(data["realgdp"].values) xs =np.array(data['year'].values) print(xs) ys = np.array(data["realcons"].values) print(ys) # #绘制 # plt.xlabel("年份(year)",fontsize = 15,color = 'r',rotation = 0 ) #添加x轴名称 plt.xlabel("年份(year)" ) #添加x轴名称 plt.ylabel("实际国内生产总值(realgdp)")#设置y轴名称 # plt.title("实际国内生产总值随年份的变化趋势", color = 'r', fontsize = 20, rotation = 0, alpha = 1) #添加标题,rotation角度 plt.title("实际国内生产总值随年份的变化趋势") plt.legend(loc='lower left') #显示图例 plt.plot(xs,ys,'m--') #划线,连线 plt.show() #显示- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
可视化结果:
二、应用
macrodata.csv 数据集在Python中的统计建模和计量经济学中应用广泛,特别是在使用Statsmodels等统计分析库进行经济数据分析时。以下是一些使用该数据集的典型应用场景:
时间序列分析:macrodata 数据集通常包含了多年的经济指标数据,可以用于时间序列分析。研究者可以使用这些数据来探索不同经济变量的趋势、季节性和周期性变化。
计量经济学模型:研究者可以使用这个数据集来估计和测试各种计量经济学模型,如线性回归、多元回归、时间序列模型和面板数据模型。这些模型可以用于研究不同经济变量之间的关系,例如 GDP 与消费支出之间的关系。
政策分析:政府和政策制定者可以使用 macrodata 数据集来评估不同政策措施对经济的影响。例如,他们可以分析政府支出与失业率之间的关系,以确定政府支出对就业的潜在影响。
预测和预测建模:研究者可以使用这个数据集来构建经济预测模型。这些模型可以用来预测未来的经济变量,帮助企业、投资者和政府做出决策。
教育和培训:macrodata 数据集也用于教育和培训,帮助学生和专业人士学习如何使用Python进行计量经济学分析。这个数据集通常用作教育材料的一部分。
在Python中,您可以使用众多的库和工具进行 macrodata 数据集的分析,包括:
Pandas:用于数据导入、清洗和转换。
NumPy:用于数值计算和数据操作。
Matplotlib 和 Seaborn:用于数据可视化和绘图。
Statsmodels:用于估计统计模型,如线性回归、时间序列模型和面板数据模型。
Scikit-learn:用于机器学习模型的建模和预测。
Jupyter Notebook:用于交互式分析和报告编写。三、statsmodels 统计模块
statsmodels 是一个 Python 包,它为 scipy 提供了统计计算的补充,包括描述性统计以及统计模型的估计和推理。
最新版本的文档位于https://www.statsmodels.org/stable/
开发版本的文档位于
https://www.statsmodels.org/dev/
发行说明中强调了最近的改进
https://www.statsmodels.org/stable/release/
文档备份可在https://statsmodels.github.io/stable/ 和https://statsmodels.github.io/dev/获取。
主要特点
- 线性回归模型:
普通最小二乘
广义最小二乘法
加权最小二乘法
具有自回归误差的最小二乘法
分位数回归
递归最小二乘法 - 具有混合效应和方差分量的混合线性模型
- GLM:广义线性模型,支持所有单参数指数族分布
- 二项式和泊松的贝叶斯混合 GLM
- GEE:单向聚类或纵向数据的广义估计方程
- 离散模型:
Logit 和 Probit
多项式 Logit (MNLogit)
泊松和广义泊松回归
负二项式回归
零膨胀计数模型
RLM:稳健的线性模型,支持多个 M 估计器。 - 时间序列分析:时间序列分析模型
完整的 StateSpace 建模框架
季节性 ARIMA 和 ARIMAX 模型
VARMA 和 VARMAX 模型
动态因子模型
未观察到的组件模型
马尔可夫切换模型 (MSAR),也称为隐马尔可夫模型 (HMM)
单变量时间序列分析:AR、ARIMA
向量自回归模型、VAR 和结构 VAR
矢量纠错模型,VECM
指数平滑、Holt-Winters
时间序列的假设检验:单位根、协整等
用于时间序列分析的描述性统计和过程模型 - 生存分析:
比例风险回归(Cox 模型)
幸存者函数估计 (Kaplan-Meier)
累积关联函数估计 - 多变量:
缺失数据的主成分分析
旋转因子分析
多元方差分析
典型相关性
四、使用 statsmodels 统计模块分析 macrodata.csv 数据集
要使用 statsmodels 统计模块分析 macrodata.csv 数据集,您需要执行以下一般步骤:
导入必要的库:首先,导入 Python 库,包括 pandas 用于数据操作和 statsmodels 用于统计分析。确保您已经安装了这些库,可以使用 pip 安装它们。
import pandas as pd import statsmodels.api as sm- 1
- 2
加载数据:使用 Pandas 加载 macrodata.csv 数据集,并查看数据的前几行,以确保数据正确加载。
data = pd.read_csv('macrodata.csv') print(data.head())- 1
- 2
数据准备:根据您的分析目标,选择感兴趣的自变量(解释变量)和因变量(响应变量)。将数据划分为 X(自变量)和 y(因变量)。
X = data[['realgdp', 'realcons', 'realinv', 'realgovt']] y = data['realdpi']- 1
- 2
添加截距项:通常,您会为模型添加一个截距项,除非您明确不希望添加。
X = sm.add_constant(X) # 添加常数(截距项)- 1
拟合模型:使用 statsmodels 来拟合您感兴趣的模型。以下是一个线性回归模型的示例:
model = sm.OLS(y, X).fit() # 拟合线性回归模型- 1
查看模型摘要:使用模型摘要方法来查看回归结果的详细信息,包括系数、标准误差、P-值等。
print(model.summary())- 1
进行统计测试:您可以使用模型进行统计测试,如假设检验,来评估模型的有效性。例如,检验系数是否显著不同于零。
print(model.t_test([0, 1, 0, 0, 0])) # 检验第一个系数是否等于零- 1
做出预测:使用拟合的模型进行预测。您可以预测因变量的值或进行其他类型的分析。
predictions = model.predict(X)- 1
以上是一个基本的分析框架,您可以根据具体的问题和分析目标进行进一步的自定义。statsmodels 还支持其他类型的模型,包括时间序列模型、逻辑回归模型等,具体操作方式可能会有所不同。根据您的需要,您可以选择适当的模型和方法进行分析。
参考
-
相关阅读:
[论文分享] Where’s Crypto?
【IEEE会议】第四届IEEE信息科学与教育国际学术会议(ICISE-IE 2023)
Nginx介绍
C语言八进制数(避坑指南)
怎样将PPT转成文本格式?PPT文本一键生成文本格式 工作经验分享
【Linux】基础:Linux环境基础开发工具——gcc与gdb
新生儿弱视:原因、科普和注意事项
数据结构笔记(王道考研) 第六章:图
DelayQueue的源码分析
C语言简易内存池实现
- 原文地址:https://blog.csdn.net/weixin_41194129/article/details/133981634