-
云服务器搭建Hadoop分布式
云服务器搭建hadoop分布式
1.服务器配置
服务器 主机名 配置 115.157.197.82 s1 10核 115.157.197.84 s2 10核 115.157.197.109 s3 10核 115.157.197.31 s4 10核 115.157.197.60 gracal 10核 所有的软件安装在/opt/module下,软件安装包在/opt/softs下
2.Java环境
-
所有的服务器的java统一1.8版本,查看java版本
java --version- 1
-
若存在java环境不统一,或者没有1.8版本的jdk
-
无1.8版本的java
yum install -y java-1.8.0-openjdk*- 1
-
环境不统一
#查看java版本 alternates --config java #选择1.8版本的数字- 1
- 2
- 3
-
相关的JAVA_HOME、Hadoop_HOME环境变量都保存在/etc/profile.d/my_env.sh中

3. 安装Hadoop
- 确保Hadoop统一版本:hadoop3.1.3
- 编写文件分发脚本,可以在一台服务器分发到其他服务器:xsync脚本,在 / h o m e / g a o c h u c h u / b i n /home/gaochuchu/bin /home/gaochuchu/bin目录下
4. 集群配置
- 各个组件的分布情况
s1 s2 s3 s4 gracal HDFS NameNode DataNode DataNode SecondaryNameNode DataNode DataNode DataNode YARN NodeManager ResourceManager NodeManager NodeManager NodeManager NodeManager -
常用端口配置 (分Hadoop2.x和Hadoop3.x的区别)
端口名称 Hadoop2.x Hadoop3.x NameNode内部通信端口 8020/9000 8020/ NameNode HTTP UI 50070 9870 MapReduce查看执行任务端口 8088 8088(容易和框架端口冲突,本文配置的7666) 历史服务器通信端口 19888 19888 -
在客户端机器(笔记本)配置ip和服务器主机名的映射,希望能通过主机名+端口号在浏览器访问各个Web页面
-
问题:通过s2:7666无法访问ResourceManger的web UI,而通过直接的ip:7666又可以访问其webUI
-
遇到这个问题我无法理解为什么会出问题
-
漫长的排错过程:
-
1.检查了服务器之间的ip和主机名的映射,各个服务器主机之间通过主机名可以ping通,说明映射没有问题,
-
2.检查客户端mac本机的hosts文件映射未发现问题,并且在客户端的终端也能ping通各个主机名,说明映射没有问题
-
3.且查看各个服务器的防火墙也处于关闭状态
-
4.通过
netstat -nltp|grep 7666查看端口的监听情况,也是正常监听状态 -
5.在网上搜索很多相关解决方案:关闭防火墙,设置etc/sysconfig/selinux的级别为disable,都没有结果
-
因此,我认为应该在客户端本机出现问题,验证问题过程
6.1 发现在本地主机
telnet s2 7666可以成功访问,但是curl s2:7666没有输出页面的任何信息6.2 使用cur -v s2:7666查看相关信息
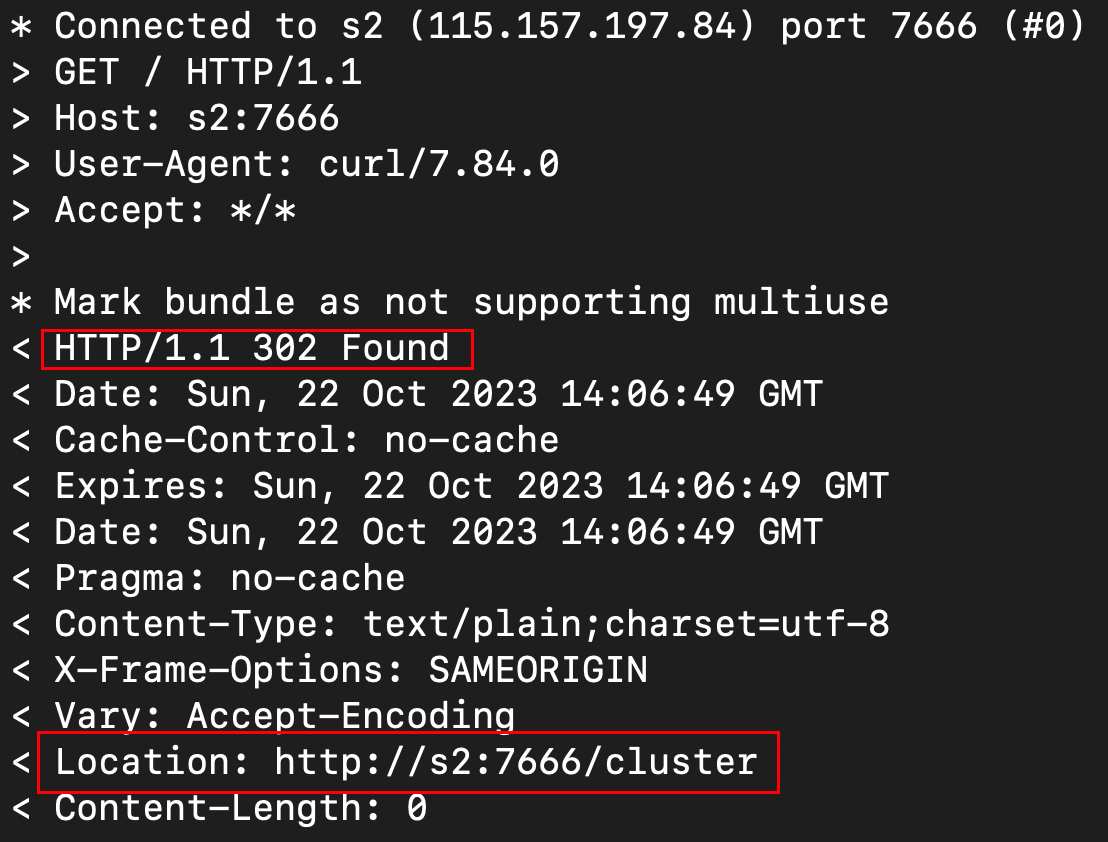
-
发生地址的重定位,然后使用命令
curl -v http://s2:7666/cluser成功返回了相关的html信息,说明页面其实是可以访问的
6.3 但是浏览器端还是无法访问:后查询到浏览器可能配置了代理服务器,而’curl’命令未配置代理。代理服务器会烦扰浏览器的访问。
因此我关闭了VPN代理,成功访问到s2:7666页面!!
以后VPN代理一定要慎用!!!排查了这么久发现最后居然是代理问题
-
-
-
-
-
启动集群测试
-
启动HDFS
[gaochuchu@s1 hadoop-3.1.3]$ sbin/start-dfs.sh- 1
-
启动YARN
[gaochuchu@s1 hadoop-3.1.3]$ sbin/start-yarn.sh- 1
-
问题:

-
解决:
- 这里的hadoop是root用户创建的hadoop,本地用户无权限
- 修改环境变量/etc/profile,注释配置的HADOOP_HOME,重新source
-
-
关闭YARN的时候警告
gracal: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9 s4: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9 s1: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9 s3: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9 Stopping resourcemanager- 1
- 2
- 3
- 4
- 5
解决方案:
由于YARN也还是能够关闭,但是是通过kill -9的方式进行杀死进程,这种方式其实很暴力,会导致数据的丢失
查看报错各个节点的node manager日志:
发现nodemanager上报错:
2023-11-13 07:47:51,005 ERROR org.apache.hadoop.yarn.server.nodemanager.NodeManager: RECEIVED SIGNAL 15: SIGTERM
resourcemanager的日志显示:
2023-11-13 07:47:57,886 ERROR org.apache.hadoop.security.token.delegation.AbstractDelegationTokenSecretManager: ExpiredTokenRemover received java.lang.InterruptedException: sleep interrupted 2023-11-13 07:47:57,903 ERROR org.apache.hadoop.yarn.event.EventDispatcher: Returning, interrupted : java.lang.InterruptedException
排错过程:
-
首先知道表明 NodeManager 收到了 SIGTERM 信号,这是一个标准的终止进程的请求。这通常是在您尝试停止 Hadoop 服务时发送的信号。说明这是kill 进程产生的信号
-
Resource manager表明在停止过程中,ResourceManager 中的某些线程被中断了。这通常发生在服务停止时,正在运行的线程被强制中断以关闭服务。这些信息表明在停止过程中,并没有出现异常行为。当你发送停止命令时,系统会尝试优雅地关闭所有服务,但如果某些服务或线程无法在给定的时间内完成其关闭流程,系统会发送 SIGTERM 信号来强制关闭它们。
-
之后查找到did not stop gracefully after 5 seconds: Trying to kill with kill -9执行函数所在的脚本,通过stop-yarn.sh 调用yarn-daemon.sh,又调用了libexec/hadoop-functions.sh
function hadoop_stop_daemon { local cmd=$1 local pidfile=$2 shift 2 local pid local cur_pid if [[ -f "${pidfile}" ]]; then pid=$(cat "$pidfile") kill "${pid}" wait_process_to_die_or_timeout "${pid}" "${HADOOP_STOP_TIMEOUT}" if kill -0 "${pid}" > /dev/null 2>&1; then hadoop_error "WARNING: ${cmd} did not stop gracefully after ${HADOOP_STOP_TIMEOUT} seconds: Trying to kill with kill -9" kill -9 "${pid}" >/dev/null 2>&1 fi wait_process_to_die_or_timeout "${pid}" "${HADOOP_STOP_TIMEOUT}" if ps -p "${pid}" > /dev/null 2>&1; then hadoop_error "ERROR: Unable to kill ${pid}" else cur_pid=$(cat "$pidfile") if [[ "${pid}" = "${cur_pid}" ]]; then rm -f "${pidfile}" >/dev/null 2>&1 else hadoop_error "WARNING: pid has changed for ${cmd}, skip deleting pid file" fi fi fi }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
从上述方法中看出,首先尝试使用常规的
kill命令发送SIGTERM信号给进程,然后等待一定的时间(HADOOP_STOP_TIMEOUT),如果进程仍然存在,则使用kill -9发送SIGKILL信号强制停止进程。如果该脚本总是使用kill -9而不是正常的kill -
首先排查pid是否为自己设置的pid地址,由于默认的pid是在/tmp目录下,但是tmp目录下的东西是会定期清理的,因此在hadoop-env.sh和yarn-env.sh中配置了新的pid地址,为$HADOOP_HOME/pid。修改脚本,检查打印的pid是否为该目录;检查pid目录位置无错
-
增加超时时间,但是无论将超时时间设置为10秒,15秒,或者更长,仍然报相同的错误kill -9
-
而且观察到resource manager所在的节点的nodemanager正常关闭;这就说明resourcemanager和其他节点的nodemanager的通信被阻碍,导致了其他节点只能通过kill -9暴力关闭
-
查看resource manager日志发现几个端口,其中8031端口的作用为:NodeManager 使用此端口与 ResourceManager 进行通信以报告节点资源使用情况。但是resource manager所在的节点防火墙没有开启8031端口,这就导致了其他节点无法与其进行通信。

-
解决,开启8031端口
sudo firewall-cmd --add-port=8031/tcp --permanent sudo firewall-cmd --reload #查看开放的端口 sudo firewall-cmd --list-ports- 1
- 2
- 3
- 4
-
另外NodeManager Localizer的默认端口地址为8040,用于管理节点上的资源本地化,此时8040端口已被使用,因此在yarn-site.xml中配置新端口
<property> <name>yarn.nodemanager.localizer.addressname> <value>0.0.0.0:8050value> property>- 1
- 2
- 3
- 4
还是建议将服务器的防火墙暂时关闭,因为hadoop的节点之间的网络通信涉及了太多复杂的端口,原先按照开放端口的方式不足以应对通信过程中可能产生的端口号,导致运行MR程序卡顿
-
运行hadoop自带的wordcount示例程序报错,并且一直卡在Running Job位置,报错信息如下:
java.io.IOException: Got error, status=ERROR, status message , ack with firstBadLink as [某ip]:9866 at org.apache.hadoop.hdfs.protocol.datatransfer.DataTransferProtoUtil.checkBlockOpStatus(DataTransferProtoUtil.java:134) at org.apache.hadoop.hdfs.protocol.datatransfer.DataTransferProtoUtil.checkBlockOpStatus(DataTransferProtoUtil.java:110) at org.apache.hadoop.hdfs.DataStreamer.createBlockOutputStream(DataStreamer.java:1778) at org.apache.hadoop.hdfs.DataStreamer.nextBlockOutputStream(DataStreamer.java:1679) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:716) ...... Caused by: java.net.NoRouteToHostException: No route to host at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:716) at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531) at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:700) at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:804) at org.apache.hadoop.ipc.Client$Connection.access$3800(Client.java:421) at org.apache.hadoop.ipc.Client.getConnection(Client.java:1606) at org.apache.hadoop.ipc.Client.call(Client.java:1435) ... 19 more- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
-
如何解决这种问题?
-
注意报错信息:No route to host ,说明没有到host的路由,排查思路,确定与对应服务器端口是否联通
-
首先测试某ip自身9866端口是否联通,说明联通

说明s1服务器和…31:9866可能是不连通的
-
经查找相关资料说明是…31服务器的icmp(Internet Control Message Protocol)被禁用导致
命令查看iptable是否有防火墙设置:
iptables -L INPUT --line-numbers- 1
发现:

命令删除这条记录:
iptables -D INPUT 28- 1
-
5. 编写集群的启动脚本
-
因为每次集群启动需要在NameNode节点的HADOOPHOME目录下使用命令启动HDFS
sbin/start-dfs.sh- 1
-
在Yarn节点上通过命令启动Yarn(ResourceManager)
sbin/start-yarn.sh- 1
-
配置了历史服务器,还需要在历史服务器的节点上使用命令启动历史服务器
mapred --daemon start historyserver- 1
-
相应的停止集群也需要通过以下三个命令来停止集群
sbin/stop-dfs.sh sbin/stop-yarn.sh mapred --daemon stop historyserver- 1
- 2
- 3
-
因此,可以编写相关的脚本启停(HDFS Yarn Historyserver)
-
在
/home/gaochuchu/bin目录下编写myhadoop.sh脚本启停Hadoop集群#启动Hadoop集群 myhadoop.sh start #停止Hadoop集群 myhadoop.sh stop- 1
- 2
- 3
- 4
-
-
服务器各节点的状态都需要通过在笔不同服务器上通过
jps命令查看,比较麻烦- 在
/home/gaochuchu/bin目录下编写jpsall脚本,可以查看所有服务器上的节点状态
- 在
-
-
相关阅读:
MySQL之JDBC编程
我的周刊(第045期)
【中秋国庆不断更】OpenHarmony多态样式stateStyles使用场景
前端优化渲染:长列表渲染
Python爬虫实战系列4:天眼查公司工商信息采集
Selenium 中的 XPath
企业图档加密系统
jeecgboot-前端组件封装代码示例
Unity通过Framwork类库中的Regex类实现了一些特殊功能数据检查
手动下载/安装Xcode的simulator
- 原文地址:https://blog.csdn.net/weixin_44911248/article/details/133979585
