-
《数据结构与算法之美》读书笔记1
Java的学习
方法参数多态(向上和向下转型)
向上转型:
- class Text{
- public static void main(String[] args) {
- Animals people1 = new NiuMa();
- people1.eat1();//调用继承后公共部分的方法,没重写调用没重写的,重写了调用重写后的。
- }
- }
父类引用子类对象:Fu dui1 = new Zi();
可用该对象调用继承后公共部分的方法,若该方法被子类重写,则调用重写后的方法。
向下转型:
- class Text{
- public static void main(String[] args) {
- Animals people2 = new NiuMa();//要先发生一次向上转型
- NiuMa people3 = (NiuMa) people2; //将people2强制类型转换成NiuMa类,用people3接收
- people1.eat1();
- people3.sleep();
- }
- }
要先发生向上转换:Fu dui2 = new Zi();
向下转换:Zi dui3 = (ZI) dui3;
接下来是读书笔记:
时间复杂度
所有代码的执行时间T(n)与每行代码的执行次数n成正比,在分析一个算法或者一段代码的时间复杂度的时候,只关注循环执行次数最多的那一段代码就好了。
加法法则
总复杂度等于两级最大的那段代码的复杂度
乘法法则
嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
最好、最坏情况时间复杂度
分别对应着最理想的情况下或者最糟糕情况下,执行这段代码的时间复杂度
均摊时间复杂度
平均复杂度只在某些特殊情况下才会用到,而均摊时间复杂度应用的场景比它更加特殊、更加有限。
数组
线性表
线性表包括数组,链表、队列、栈等。
如果问到数组和链表的区别?
回答:链表适合插入删除,时间复杂度是O(1);数组适合查找,查找的时间复杂度是O(1)。
但是这个回答不是准确的,数组是适合查找操作,但是查找的时间复杂度不是O(1),即使是排序好的数据,用二分查找,时间复杂度也是O(logn)。正确的表述应该是,数组支持随机访问,根据下标随机访问的时间复杂度为O(1)
注意
1.防止数组越界问题
2.容器不能完全代替数组
容器的优势:可以将很多数组操作的细节封装起来,支持动态扩容(最好在创建ArrayList的时候指定数据大小)
数组的优势:
Java ArayList无法存储基本类型(int、long)需要封装为(Integer、Long)类,就会有一定的性能消耗
如果对数据操作非常简单,用数组更好
非线性表
非线性表包括二叉树、堆、图等。
链表
对于数组来说,需要一块连续的内存空间来存储,对内存的要求比较高,如果我们申请一个100Mb大小的数组,如果有充足的空间,但是没有连续的,足够大的空间,仍然会申请失败。
而链表将一组零散的内存块串联在一起,其中吧内存块称为链表的结点,为了把所有结点串起来,每个链表的结点出来存储数据之外,还需要记录链上下一个结点的地址,把这个记录下一个结点地址的指针称为后继指针next。

单链表
第一个结点是头结点,最后一个结点是尾结点,尾结点的后继指针是指向NULL(空地址)的。
在进行数组的插入、删除操作时,为了保持内存数据的连续性,需要做大量的数据搬移,所以时间复杂度是O(n)。而在链表中插入或者删除一个数据,我们并不需要为了保持内存的连续性而搬移结点,因为链表的存储空间本身就不是连续的。所以,在链表中插入和删除一个数据是非常快速的。
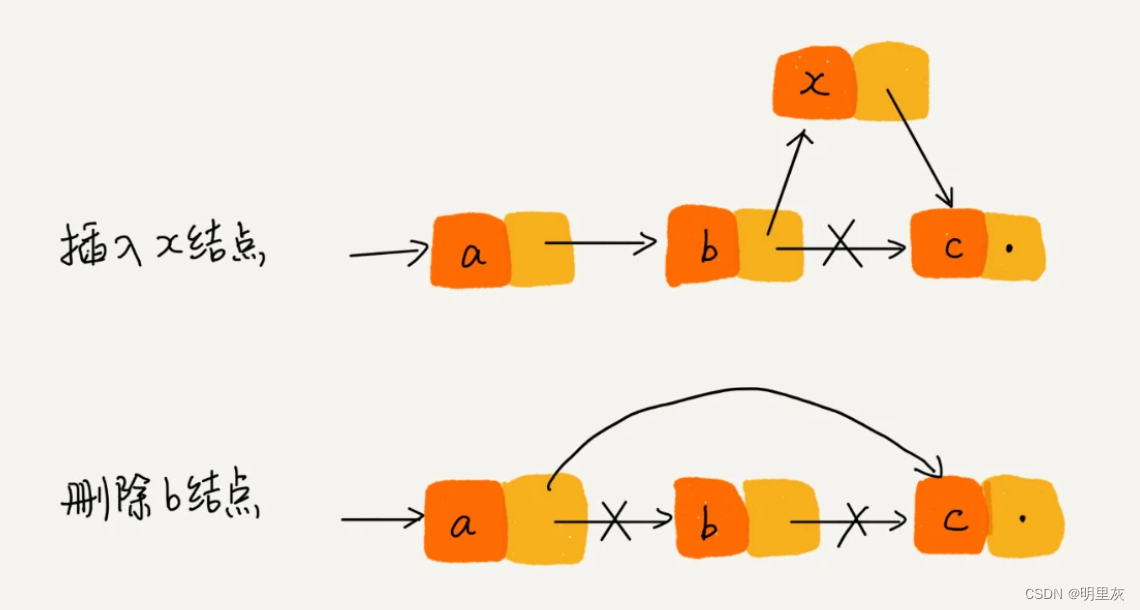
但是对于随机访问第k个元素,就没有数组那么高效,根据指针一个结点一个结点地依次遍历,直到找到相应的结点。
循环列表
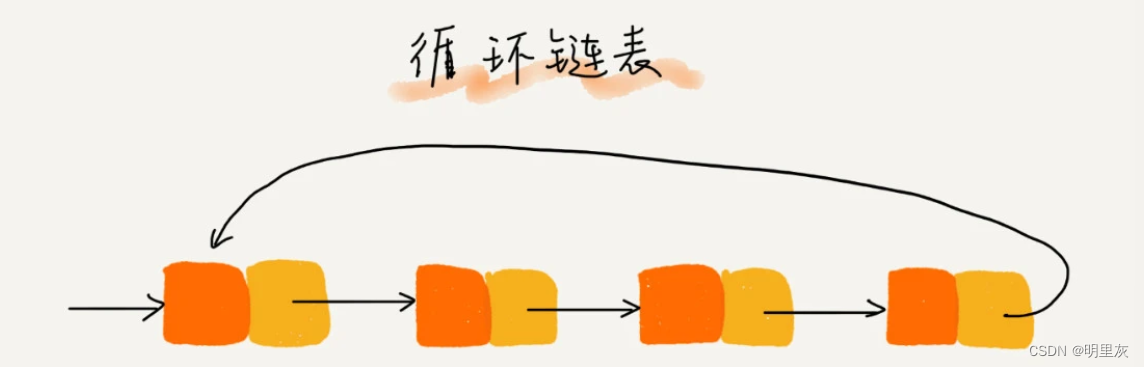
和单链表有一个区别:尾结点指向的是头结点,此时首尾相连,循环链表的优点是从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就适合采用循环链表。
双向链表
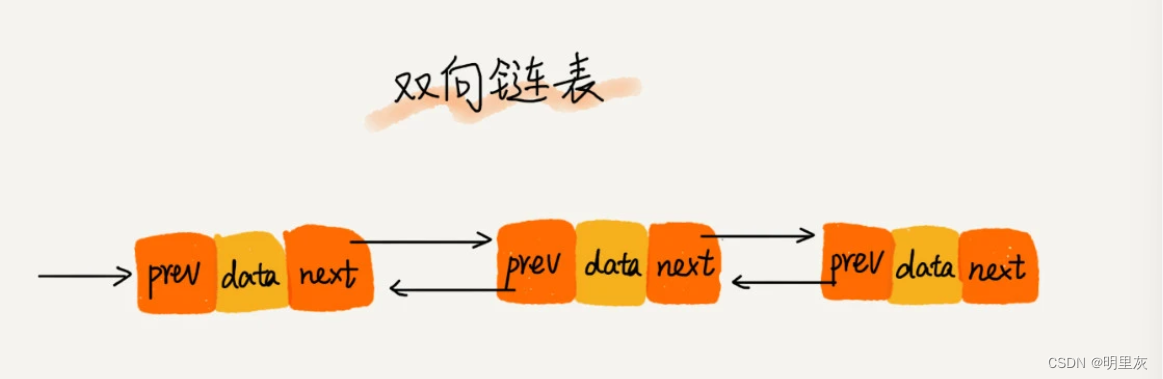
单向链表只有一个方向,因为节点只有一个后继指针next指向后面的结点。但是双向链表的结点还有一个前驱指针prev指向前面的结点。
如果存储同样多的数据,双向链表要比单链表占用更多的内存空间。虽然两个指针比较浪费存储空间,但可以支持双向遍历,这样也带来了双向链表操作的灵活性。
链表的删除操作
-
删除结点中“值等于某个给定值”的结点;
-
删除给定指针指向的结点。
第一种删除的情况,对于单链表和双链表来说,为了找到给定值的结点,都需要从头开始遍历比对,知道找到给定值的结点,然后进行删除。
第二种删除的情况,是知道要删除的结点,但是我们要知道该结点的前驱指针和后继指针,才能连接前一个结点和后一个结点,从而删除结点。对于单链表来说,为了找到前驱结点,需要从头结点开始遍历链表,知道p->next=q,说明p是q的前驱结点,时间复杂度为O(n)。而双向链表直接存在一个前驱指针,可以直接连接要删除结点的前驱结点和后继结点,达到删除的效果,时间复杂度为O(1)。
-
相关阅读:
java集合
除了SD Web UI 或comfyUI,还有更简单的运行SDXL的方法吗?
ARM按键中断实验
树莓派|采集视频并实时显示画面
四种经典限流算法的实现思路以及各自的优缺点
NProgress进度条的使用
全国快递查询接口,快递,全球快递,配送,物流管理,物流数据,电子商务
【周赛364-单调栈】美丽塔 II-力扣 2866
Linux安全基线-审计配置9小项
尚品汇_第5章_ 商品sku保存
- 原文地址:https://blog.csdn.net/m0_73172034/article/details/133523357