引言
在我们之前的章节中,我们着重讲解了CPU内部的处理过程,以及与之密切相关的数据总线知识。在这个基础上,我们今天将继续深入探讨CPU执行指令的相关知识,这对于我们理解计算机的工作原理至关重要。
CPU 是一系列寄存器的集合体
我们以使用的 Intel CPU 为例,其中包含数百亿个晶体管。在逻辑上,我们可以认为 CPU 实际上由一组寄存器组成。寄存器是 CPU 内部的简单电路,由多个触发器(Flip-Flop)或锁存器(Latches)组成。
触发器和锁存器实际上是由不同原理的数字电路组成的逻辑门。
一个 CPU 中包含许多不同功能的寄存器,我将介绍其中三种比较特殊的寄存器。
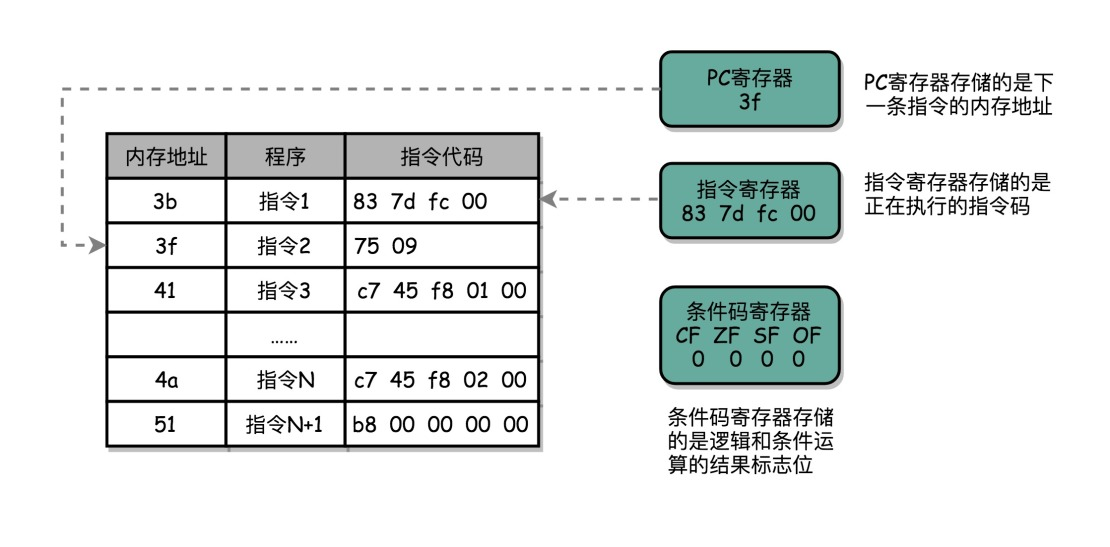
首先是 PC 寄存器(Program Counter Register),也称为指令地址寄存器(Instruction Address Register)。顾名思义,它用于存储下一条需要执行的计算机指令的内存地址。
第二个是指令寄存器(Instruction Register),用于存储当前正在执行的指令。
第三个是条件码寄存器(Status Register),其中的标志位(Flag)存储了 CPU 进行算术或逻辑计算的结果。
除了这些特殊的寄存器,CPU 还包含更多用于存储数据和内存地址的寄存器。通常每类寄存器不止一个,我们根据存储的数据内容给它们命名,比如整数寄存器、浮点数寄存器、向量寄存器和地址寄存器等。有些寄存器既可以存储数据,又可以存储地址,我们称之为通用寄存器。
程序计数器
程序计数器(Program Counter,简称PC)是用来存储下一条指令所在单元的地址的寄存器。在程序执行时,PC的初始值被设置为程序第一条指令的地址。当顺序执行程序时,控制器首先从内存中取出一条指令,该指令的地址由PC指示。然后,控制器分析和执行该指令,并将PC的值加1,指向下一条要执行的指令的地址。
让我们以一个相加操作的例子来详细解释程序计数器的执行过程。假设我们有一段程序,其目的是将数字123和456相加,并将结果输出到显示器上。

程序在启动时,经过编译和解析后,会被操作系统从硬盘复制到内存中。假设程序的起始位置是地址0100。操作系统会将程序计数器设置为0100作为起始位置,并开始执行程序。每执行一条指令后,程序计数器的值会增加1,或者直接指向下一条指令的地址。CPU根据程序计数器的值,从内存中读取指令并执行。换句话说,程序计数器控制着程序的执行流程。
而在Java虚拟机(JVM)中,程序计数器是一种虚拟机级别的数据结构,用于存储当前线程正在执行的JVM指令的地址或索引。它是线程私有的,每个线程都有自己独立的程序计数器。
程序计数器在Java虚拟机中的作用与在计算机体系结构中的作用类似,即控制程序执行流程。它会指示下一条要执行的指令,以便JVM能够顺序地执行程序。
区别在于,计算机体系结构中的程序计数器是硬件级别的寄存器,而Java虚拟机中的程序计数器是虚拟机级别的数据结构。
条件分支和循环机制
高级语言中的条件控制流程主要分为三种:顺序执行、条件分支和循环判断。顺序执行是按照地址的内容顺序执行指令。条件分支是根据条件执行任意地址的指令。循环是重复执行同一地址的指令。就跟Java中使用的判断类似。
顺序执行的情况比较简单,每执行一条指令程序计数器的值就是当前地址加一。
在程序中,条件分支语句可以使程序计数器的值指向任意的地址。这样一来,程序就可以返回到上一个地址,以便重复执行同一个指令,或者跳转到任意指令。下面以条件分支为例来详细说明程序的执行过程(循环也具有类似的原理和过程):

条件和循环分支会利用跳转指令(jump)来实现。程序的执行过程和顺序流程是相同的。CPU从地址0100开始执行指令。在地址0100和0101处的指令是按顺序执行的,程序计数器(PC)的值递增。当执行到地址0102处的指令时,会判断寄存器0106的数值是否大于0。如果满足条件,则会跳转(jump)到地址0104处的指令,将数值输出到显示器中,然后程序结束。这意味着地址0103处的指令被跳过了。这与我们在程序中使用if()条件判断的原理是相同的。在不满足条件的情况下,指令会直接跳过。因此,程序计数器的执行过程不是简单地递增1,而是跳转到下一条指令的地址。
函数调用机制
接下来,我们将继续介绍函数调用机制。即使是使用高级语言编写的程序,函数调用的处理也是通过将程序计数器的值设置为函数的存储地址来实现的。在函数执行跳转指令之后,必须进行返回处理,否则仅仅进行指令跳转是没有意义的。下面是一个实现函数跳转的示例:
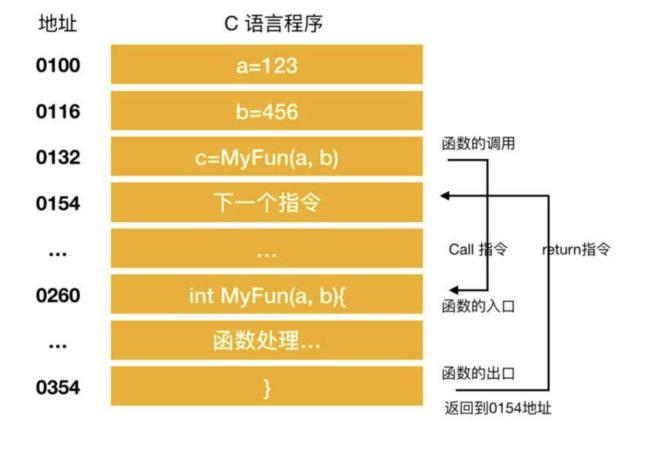
函数调用和返回是非常重要的两个指令,它们分别是call和return指令。在将函数的入口地址设置到程序计数器之前,call指令会将调用函数后要执行的指令地址存储在名为栈的主存中。函数处理完毕后,通过函数的出口执行return指令。return指令的功能是将保存在栈中的地址设置到程序计数器。
例如,当调用MyFun函数之前,地址0154被保存在栈中。在MyFun函数处理完成后,将会将0154的地址保存在程序计数器中。这样,程序就可以正确地返回到调用MyFun函数的地方继续执行后续的指令。函数调用和返回的机制确保了程序的流程能够正确地跳转和返回,使得程序的执行能够按照预期的顺序进行。
CPU 指令执行过程
冯·诺伊曼型计算机的CPU工作可以分为五个阶段:取指令、指令译码、执行指令、访存取数、结果写回。
在取指令阶段,CPU从内存中读取指令,并将下一条指令的地址存储在程序寄存器中。这个阶段主要涉及的是内存的读取操作,以获取下一条指令的地址。
指令译码阶段紧随其后,指令译码器根据指令的格式将其拆分和解释,识别指令的类型和操作数的获取方法。这个阶段的目的是将指令翻译成可执行的操作,为执行指令阶段做准备。
执行指令阶段是CPU执行指令的主要阶段。在这个阶段,CPU根据指令的要求完成各种操作,实现指令的功能。这可能涉及到算术运算、逻辑运算、数据传输等操作,具体取决于指令的类型。
访存取数阶段是在执行指令阶段之后进行的。根据指令的需求,可能需要从内存中获取数据。这个阶段的任务是根据指令的地址码找到操作数在主存中的地址,并从主存中读取该操作数用于运算。这个阶段与访问主存相关,确保指令所需的数据可供使用。
结果写回阶段是最后一个阶段,将执行指令阶段的运算结果数据写回到某种存储形式。通常情况下,结果数据被写入CPU的内部寄存器中,以便后续指令快速访问。这个阶段的目的是将计算得到的结果保存下来,供其他指令使用或输出。
这五个阶段的顺序保证了CPU的正常运行,并且每个阶段都有其特定的任务,以实现指令的正确执行和数据的处理。通过优化这些阶段的执行过程,可以提高计算机的性能和效率。
总结
在本章中,我们继续深入探讨了CPU如何执行指令的相关知识。首先,我们了解了CPU是由一系列寄存器组成的,包括PC寄存器、指令寄存器和条件码寄存器等。然后,我们讨论了程序计数器的作用,它控制着程序的执行流程,并且在条件分支和循环中起到关键作用。接着,我们介绍了函数调用机制,包括call和return指令的使用,以及如何正确地跳转和返回。最后,我们了解了CPU指令执行过程的五个阶段:取指令、指令译码、执行指令、访存取数和结果写回。通过优化这些阶段的执行过程,可以提高计算机的性能和效率。通过本章的学习,我们对CPU如何执行指令有了更深入的了解,进一步加深了对计算机工作原理的理解。