-
基于斑马优化的BP神经网络(分类应用) - 附代码
基于斑马优化的BP神经网络(分类应用) - 附代码
摘要:本文主要介绍如何用斑马算法优化BP神经网络,利用鸢尾花数据,做一个简单的讲解。1.鸢尾花iris数据介绍
本案例利用matlab公用的iris鸢尾花数据,作为测试数据,iris数据是特征为4维,类别为3个类别。数据格式如下:
特征1 特征2 特征3 类别 单组iris数据 5.3 2.1 1.2 1 3种类别用1,2,3表示。
2.数据集整理
iris数据总共包含150组数据,将其分为训练集105组,测试集45组。如下表所示:
训练集(组) 测试集(组) 总数据(组) 105 45 150 类别数据处理:原始数据类别用1,2,3表示为了方便神经网络训练,类别1,2,3分别用1,0,0;0,1,0;0,0,1表示。
当进行数据训练对所有输入特征数据均进行归一化处理。
3.斑马优化BP神经网络
3.1 BP神经网络参数设置
通常而言,利用智能算法一般优化BP神经网络的初始权值和阈值来改善BP神经网络的性能。本案例基于iris数据,由于iris数据维度不高,采用简单的BP神经网络。神经网络参数如下:
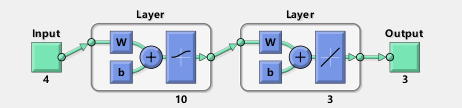
图1.神经网络结构 神经网络参数如下:
%创建神经网络 inputnum = 4; %inputnum 输入层节点数 4维特征 hiddennum = 10; %hiddennum 隐含层节点数 outputnum = 3; %outputnum 隐含层节点数 net = newff( minmax(input) , [hiddennum outputnum] , { 'logsig' 'purelin' } , 'traingdx' ) ; %设置训练参数 net.trainparam.show = 50 ; net.trainparam.epochs = 200 ; net.trainparam.goal = 0.01 ; net.trainParam.lr = 0.01 ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.2 斑马算法应用
斑马算法原理请参考:https://blog.csdn.net/u011835903/article/details/130565746
斑马算法的参数设置为:
popsize = 10;%种群数量 Max_iteration = 15;%最大迭代次数 lb = -5;%权值阈值下边界 ub = 5;%权值阈值上边界 % inputnum * hiddennum + hiddennum*outputnum 为阈值的个数 % hiddennum + outputnum 为权值的个数 dim = inputnum * hiddennum + hiddennum*outputnum + hiddennum + outputnum ;% inputnum * hiddennum + hiddennum*outputnum维度- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这里需要注意的是,神经网络的阈值数量计算方式如下:
本网络有2层:
第一层的阈值数量为:4*10 = 40; 即inputnum * hiddennum;
第一层的权值数量为:10;即hiddennum;
第二层的阈值数量为:3*10 = 30;即hiddenum * outputnum;
第二层权值数量为:3;即outputnum;
于是可知我们优化的维度为:inputnum * hiddennum + hiddennum*outputnum + hiddennum + outputnum = 83;
适应度函数值设定:
本文设置适应度函数如下:
f i t n e s s = a r g m i n ( T r a i n D a t a E r r o r R a t e + T e s t D a t a E r r o r R a t e ) fitness = argmin(TrainDataErrorRate + TestDataErrorRate) fitness=argmin(TrainDataErrorRate+TestDataErrorRate)
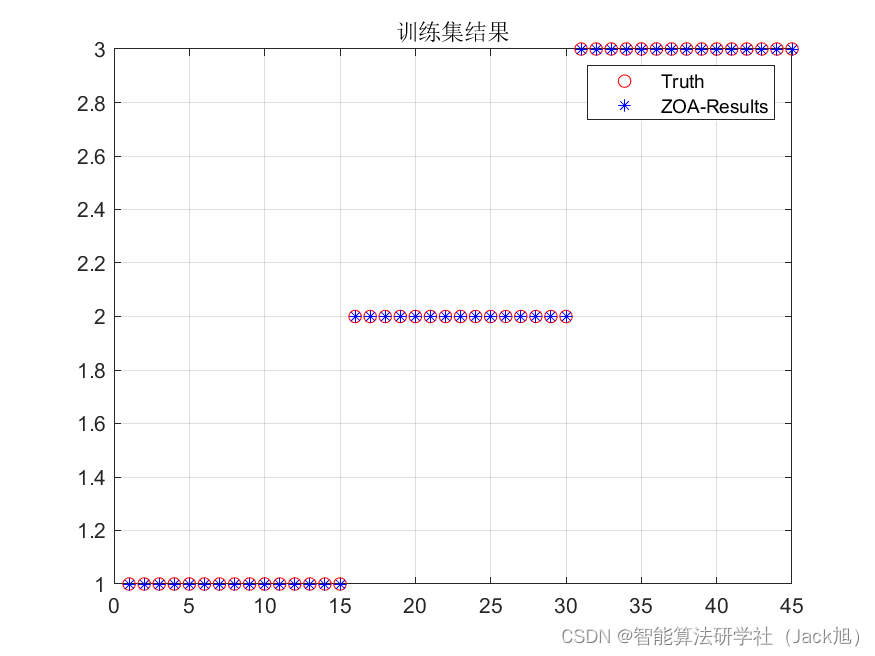
其中TrainDataErrorRate,TestDataErrorRate分别为训练集和测试集的错误分类率。适应度函数表明我们最终想得到的网络是在测试集和训练集上均可以得到较好结果的网络。4.测试结果:
从斑马算法的收敛曲线可以看到,整体误差是不断下降的,说明斑马算法起到了优化的作用:

5.Matlab代码
-
相关阅读:
软文推广提升品牌曝光的技巧,媒介盒子告诉你
一款采用于LSOP-6封裝MPCS-343 4.0 A门驱动器光电耦合器 代替ACPL-P343 反应速度快 适用于工业逆变器
为什么要改变this指向?
实战指南:如何在企业环境中精细配置百数报表访问权限
做接口测试都测什么?有哪些通用测试点?
大学生面试JAVA程序员应该具备的JAVA面试题库
QtC++与QCheckBox详解
OpenMPI的安装与运行分布式项目
SwiftUI AR教程之应用程序中使用 RealityKit 生成 3D 文本(教程含完整源码)
使用poco出现Cannot find any visible node by query UIObjectProxy of “xxx“怎么办
- 原文地址:https://blog.csdn.net/u011835903/article/details/133969190