-
GO学习之 goroutine的调度原理
GO系列
1、GO学习之Hello World
2、GO学习之入门语法
3、GO学习之切片操作
4、GO学习之 Map 操作
5、GO学习之 结构体 操作
6、GO学习之 通道(Channel)
7、GO学习之 多线程(goroutine)
8、GO学习之 函数(Function)
9、GO学习之 接口(Interface)
10、GO学习之 网络通信(Net/Http)
11、GO学习之 微框架(Gin)
12、GO学习之 数据库(mysql)
13、GO学习之 数据库(Redis)
14、GO学习之 搜索引擎(ElasticSearch)
15、GO学习之 消息队列(Kafka)
16、GO学习之 远程过程调用(RPC)
17、GO学习之 goroutine的调度原理前言
按照公司目前的任务,go 学习是必经之路了,虽然行业卷,不过技多不压身,依旧努力!!!
并发与并行:21世纪以后,数据中心的硬件和网络环境发生了重大变化,多核处理器硬件成为数据中心的主流。而20世纪的主流编程语言(C++,java等)并非以解决多核和网络环境下日益复杂的问题而生,即便这些语言在后续的版本中努力做了有针对性的改善,但毕竟积重难返,其最初的语音设计决定了开发人员想要有效地利用多核环境的强大计算能力,要付出的心智负担依旧很好。- 并行方案:就是在处理核数充足的情况下启动多个单线程应用的实例。
- 并发方案:并发就要从小做应用结构设计,即将应用分解成多个在基本单元中执行,可能有一定关联关系的代码片段。
Go 语言的设计哲学之一是 “原生并发,轻量高效”。Go 并未使用操作系统线程作为分解后的代码片段的基本执行单元,而是实现了 goroutine 这一由Go运行时负责调度的用户层轻量级线程为并发程序设计提供原生支持。
goroutine相比传统操作系统线程而言具有如下优势:- 资源占用小,每个 goroutine 的初始栈大小仅为 2KB。
- 由 Go 运行时而不是操作系统调度,goroutine 上下文切换代价小。
- 语言原生支持:goroutine 由 Go 关键字函数或方法创建,函数或方法返回即表示 goroutine 退出,开发体验更佳。
- 内置 channel 作为 goroutine 间通信原语,并并发设计提供强大支撑。
—— 以上内容摘自《Go语音精进之路》一书。

此篇内容也是借鉴此书而写。一、goroutine 调度器
什么是 goroutine调度器呢?提到 “调度”,想到的就是有一个中央控制器,对资源的各种调度以达到某种目的,比如操作系统对进程、线程的调度。操作系统调度器会将操作系统中的多个线程按照一定的算法调度到物理CPU上运行。传统的编程语言的并发实现多试基于线程模型的,即应用程序负责创建线程,操作系统负责调度线程。然而这种传统支持并发的方式有诸多不足,比如:使用复杂、线程安全、难以扩展等。
为此,Go 采用用户层轻量级线程来解决这些问题,并称之为goroutine。
由于 goroutine 占用资源很少,一个 Go 程序中可以创建上万个并发的 goroutine。而将这些 goroutine 按照一定的算法放到 CPU 上执行的程序就称之为goroutine 调度器。
一个 Go 程序对于操作系统来说只是一个用户层程序,操作系统只有线程, goroutine 的调度全要靠 Go 自己完成。二、goroutine调度模型与演进过程
2.1 G-M 模型
Go 1.0正式版本中,Go 开发团队实现了一个简单的 goroutine 调度器。这个调度器中,每个 goroutine 对应与运行中的一个抽象结构 —— G(goroutine),而被视作 “物理CPU” 的操作系统线程则被抽象为另一个结构 —— M(machine)。这个模型比较简单且能正常工作,但存在着诸多问题。
原文如下:
前英特尔黑带级工程师、现谷歌工程师Dmitry Vyukov在“Scalable Go Scheduler Design”一文中指出了G-M模型的一个重要不足:限制了Go并发程序的伸缩性,尤其是对那些有高吞吐或并行计算需求的服务程序。
问题主要体现在如下几个方面。- 单一全局互斥锁(Sched.Lock)和集中状态存储的存在导致所有goroutine相关操作(如创建、重新调度等)都要上锁。
- goroutine传递问题:经常在M之间传递“可运行”的 goroutine 会导致调度延迟增大,带来额外的性能损耗。每个M都做内存缓存,导致内存占用过高,数据局部性较差。
因系统调用(syscall)而形成的频繁的工作线程阻塞和解除阻塞会带来额外的性能损耗。
2.2 G-P-M 模型
在发现了 G-M 模型的不足后,这位大佬(Dmitry Vyukov)改进了 goroutine 调度器,实现了 G-P-M 调度模型 和 work stealing 算法,如图所示:
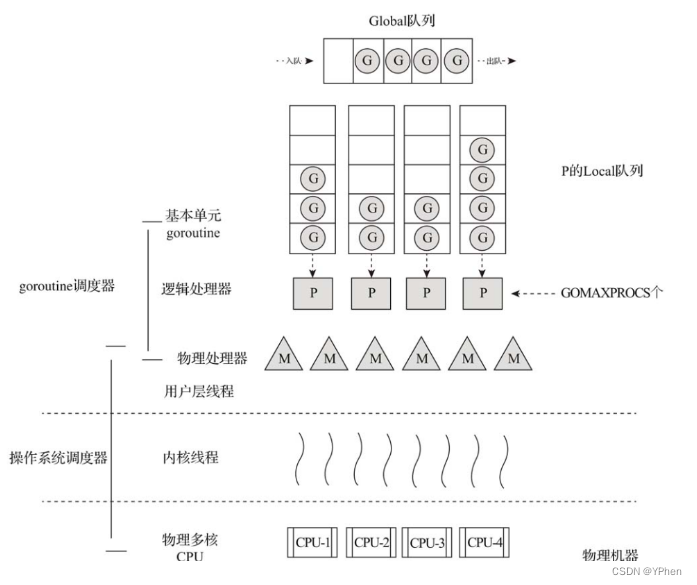
这位大佬向 G-M 模型中增加了一个 P,使得 goroutine 调度器具有很好的伸缩性。
那 P 是什么?P 是一个 “逻辑处理器”,每个 G 想要真正运行起来,首先需要分配一个 P,即进入P 的 本地运行队列(local runq)中。对于 G 来说,P 就是运行它的 “CPU”,可以说在 G的眼里只有 P。但从 goroutine 调度器的视角来看,真正的 “CPU” 是 M。只有将 P 和 M 绑定才能让 P 的本地运行队列中的 G 真正运行。这样一来 P 与 M 的对应关系是 多对多(N:M)。2.3 抢占式调度
在实现了 G-P-M 调度模型这一大进步之后,调度器仍然有一个头疼的问题,那就是不支持抢占式调度,这导致一旦某个 G 中出现死循环的代码逻辑,那么 G 将永久占用分配给它的 P 和 M,而位于同一个 P 中的其他 G 将得不到调度,出现 “饿死” 情况。
于是大佬又提出了 “抢占式调度” 设计, 并在 Go 1.2 版本中实现了抢占式调度。这个抢占式调度的原理是在每个函数或方法的入口加上一段额外的代码,让运行时有机会检查是否需要执行抢占调度。这种协作式抢占调度的解决方案只是局部解决了“饿死”问题,对于没有函数调用而是纯算法循环计算的G,goroutine调度器依然无法抢占
2.4 NUMA调度模型
在 Go 1.2 以后,Go 重点放在了 GC 低延迟的优化上,大佬虽然提出了 NUMA 调度模型,但没有真正落地实现,还有待考察。
三、goroutine 调度器原理
- G P M 介绍
G:代表goroutine,存储了goroutine的执行栈信息、goroutine状态及goroutine的任务函数等。另外G对象是可以重用的。
P:代表逻辑processor,P的数量决定了系统内最大可并行的G的数量(前提:系统的物理CPU核数>=P的数量)。P中最有用的是其拥有的各种G对象队列、链表、一些缓存和状态。
M:M代表着真正的执行计算资源。在绑定有效的P后,进入一个调度循环;而调度循环的机制大致是从各种队列、P的本地运行队列中获取G,切换到G的执行栈上并执行G的函数,调用goexit做清理工作并回到M。如此反复。M并不保留G状态,这是G可以跨M调度的基础。-
G 被抢占调度
与操作系统按时间片调度线程不同,Go 中并没有时间片概念。如果某个 G 没有进行系统调用(syscll)、没有进行 I/O 操作,也没有阻塞在一个 channel 操作上,那么 M 是如何让 G 停下来并调度下一个可运行的G 呢?
答案是:G 是被抢占调度的。 -
channel阻塞 或者 网络I/O 情况下的调度
如果 G 被阻塞在某个 channel操作 或者 网络I/O 操作上,那么 G 会被放置在某个等待队列中,而 M 会尝试运行 P 的下一个运行的 G。
如果此时 P 没有可运行的 G 提供 M 运行,那么 M 将解绑 P,并进入挂起状态。
当 I/O 操作 或者 channel操作完成,在等待队列中的 G 会被唤醒,标记为 runnable 状态,并进图某个 P 的队列中,绑定一个 M 后继续执行。 -
系统调用阻塞情况下的调度
如果 G 被阻塞在某个系统调用上,那么不仅 G 会阻塞,执行该 G 的 M 也会解绑 P,与 G 一起进入阻塞状态;如果此时有空闲的 M,则 P 会与其绑定并继续执行其他 G;如果没有空闲的 M,但任然有其他 G 要执行,那么就会创建一个新 M;
当系统调用返回后,阻塞在该系统调用上的 G 会尝试获取一个可用的 P,如果有可用 P,之前运行该 G 的 M 将绑定 P 继续运行 G。如果没有可用的 P,那么 G 与 M 之间的关系将解绑,同时 G 会被标记为 runnable,放入全局的运行队列中,带的调度器的再次调度。
四、调度器状态查看
Go提供了调度器当前状态的查看方法:使用Go运行时环境变量GODEBUG。
关于Go调度器调试信息输出的详细信息,可以参考Dmitry Vyukov的文章 Debugging Performance Issues in Go Programs,这也应该是每个Gopher必读的经典文章。
更详尽的信息可参考$GOROOT/src/runtime/proc.go中schedtrace函数的实现。五、小结
goroutine是Go语言并发的基础,也是最基本的执行单元。Go基于goroutine建立了G-P-M的调度模型,了解这个调度模型对于Go代码设计以及Go代码问题的诊断都有很大帮助。
现阶段还是对 Go 语言的学习阶段,想必有一些地方考虑的不全面,本文示例全部是亲自手敲代码并且执行通过。
如有问题,还请指教。
评论去告诉我哦!!!一起学习一起进步!!! -
相关阅读:
【计算机网络】什么是http?
CentOS7.5离线安装jdk1.8
深入Java了解面向对象编程(OOP)
C++挑选书籍
LongAdder(高性能原子累加器)源码分析
Java基础回顾-数组的内存结构/常用方法
SpringCloudStream+Rocket事务消息配置
将激光点云数据投影到二维图像及对三维点云上色
轮足机器人硬件总结
【Redis实现秒杀业务③】超卖问题之乐观锁具体实现
- 原文地址:https://blog.csdn.net/qq_19283249/article/details/133959367