-
Leetcode刷题解析——串联所有单词的子串
1. 题目链接:30. 串联所有单词的子串
2. 题目描述:
给定一个字符串
s和一个字符串数组words。words中所有字符串 长度相同。s中的 串联子串 是指一个包含words中所有字符串以任意顺序排列连接起来的子串。- 例如,如果
words = ["ab","cd","ef"], 那么"abcdef","abefcd","cdabef","cdefab","efabcd", 和"efcdab"都是串联子串。"acdbef"不是串联子串,因为他不是任何words排列的连接。
返回所有串联子串在
s中的开始索引。你可以以 任意顺序 返回答案。示例 1:
输入:s = "barfoothefoobarman", words = ["foo","bar"] 输出:[0,9] 解释:因为 words.length == 2 同时 words[i].length == 3,连接的子字符串的长度必须为 6。 子串 "barfoo" 开始位置是 0。它是 words 中以 ["bar","foo"] 顺序排列的连接。 子串 "foobar" 开始位置是 9。它是 words 中以 ["foo","bar"] 顺序排列的连接。 输出顺序无关紧要。返回 [9,0] 也是可以的。- 1
- 2
- 3
- 4
- 5
- 6
示例 2:
输入:s = "wordgoodgoodgoodbestword", words = ["word","good","best","word"] 输出:[] 解释:因为 words.length == 4 并且 words[i].length == 4,所以串联子串的长度必须为 16。 s 中没有子串长度为 16 并且等于 words 的任何顺序排列的连接。 所以我们返回一个空数组。- 1
- 2
- 3
- 4
- 5
示例 3:
输入:s = "barfoofoobarthefoobarman", words = ["bar","foo","the"] 输出:[6,9,12] 解释:因为 words.length == 3 并且 words[i].length == 3,所以串联子串的长度必须为 9。 子串 "foobarthe" 开始位置是 6。它是 words 中以 ["foo","bar","the"] 顺序排列的连接。 子串 "barthefoo" 开始位置是 9。它是 words 中以 ["bar","the","foo"] 顺序排列的连接。 子串 "thefoobar" 开始位置是 12。它是 words 中以 ["the","foo","bar"] 顺序排列的连接。- 1
- 2
- 3
- 4
- 5
- 6
提示:
1 <= s.length <= 1041 <= words.length <= 50001 <= words[i].length <= 30words[i]和s由小写英文字母组成
3. 算法思路:
-
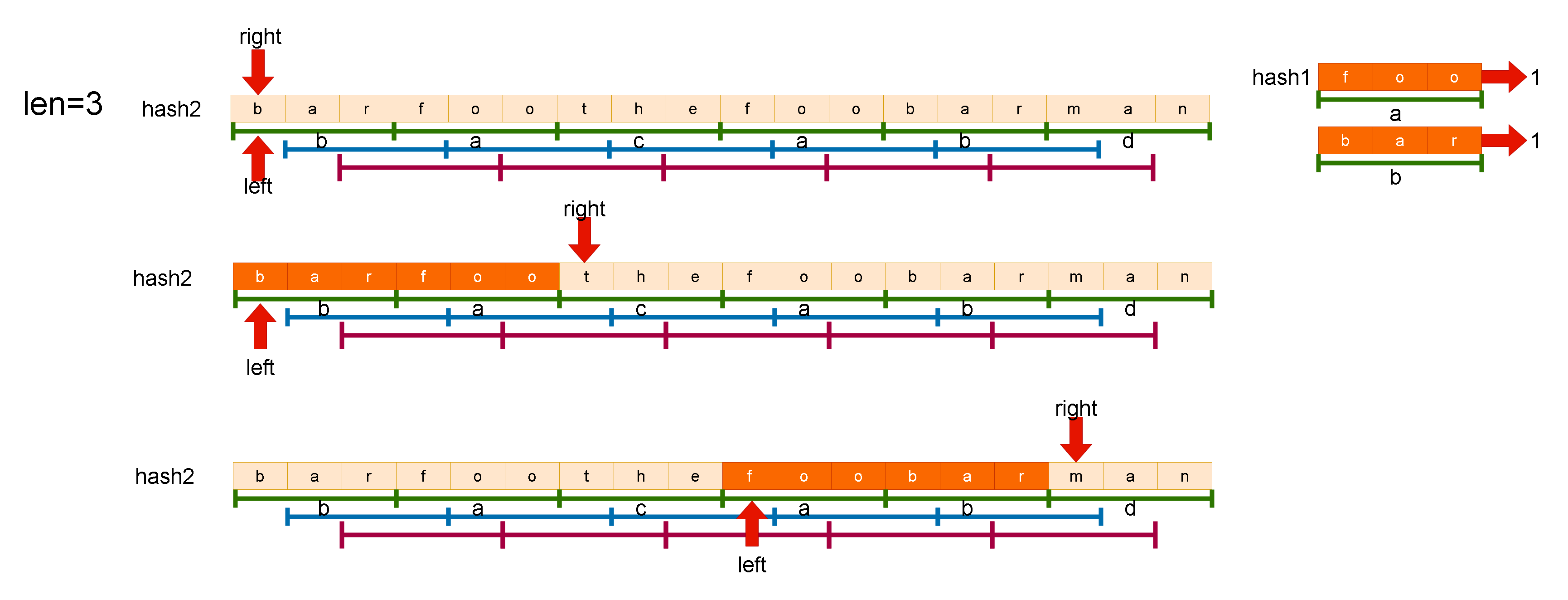
这段代码使用滑动窗口的思想来解决字符串匹配的问题。给定一个主串s和一个模式串
words,如果s中存在一个子串,该子串包含words中所有单词且顺序一致,那么这个子串就是words的一个"串联子串"。代码的目标是在s中寻找所有的串联子串的起始位置。 -
首先,用一个哈希表
hash1来保存模式串words中所有单词的频次。然后遍历字符串s的所有可能起始位置,记为x。 -
接下来,构建一个新的哈希表
hash2,用于维护滑动窗口内的单词频次。滑动窗口的起始位置为x,终止位置为y,窗口的长度是len(words中单词长度的总和)。每次移动窗口时,将窗口右边的单词加入到hash2中,并更新对应单词的频次和计数count。如果窗口内的单词频次在hash1中存在且小于等于hash1中的频次,则count加1。 -
如果窗口的长度超过
len*m(m是words中单词的个数),说明窗口左边的单词已经不在窗口范围内,需要移出窗口并更新hash2和count。具体操作是:将窗口左边的单词移出窗口,并更新对应单词的频次和count。 -
最后,当
count等于m时,将窗口左边的起始位置加入到结果集ret中。 -
最后返回
ret,即为所有串联子串的起始位置。
4. C++算法代码:
class Solution { public: vectorfindSubstring(string s, vector & words) { vector ret; unordered_map - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 例如,如果
-
相关阅读:
华为机试 - 完美走位
EN 14342木地板产品—CE认证
使用达梦数据库的总结
LeetCode每日一题——1704. 判断字符串的两半是否相似
mysql 死锁详细分析(三)
JAVA开发管理(敏捷如何解决实际痛点问题)
yolo配置(windows)
RabbitMQ高级篇,进阶内容
Reactive UI -- 反应式编程UI框架入门学习(一)
定时任务框架-xxljob
- 原文地址:https://blog.csdn.net/weixin_51799303/article/details/133968457
