-
Linux:程序地址空间/虚拟地址等相关概念理解
程序地址空间
在
C和C++程序中,一直有一个观点是,程序中的各个变量等都会有一定的地址空间,因此才会有诸如取地址,通过地址访问等操作,那么在前面的学习中,基本有下面的概念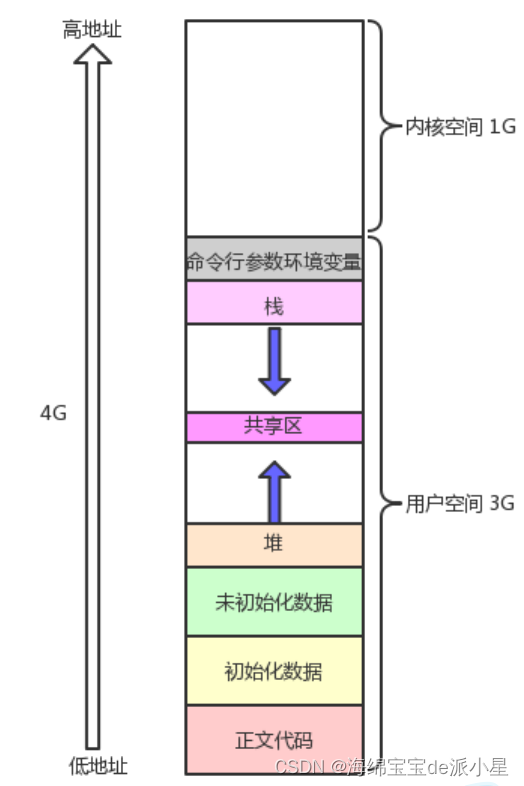
这是学
C语言的时候就已经知晓的内容,那么现在抛出下面的几个疑问:这些数据和所谓的地址是内存中的地址吗?内存中的地址存储排列形式如此整齐吗?不会造成内存浪费吗?下面做一个小实验:
#include#include int g_val = 100; int main() { pid_t id = fork(); if(id == 0) { //child int cnt = 5; while(1) { printf("child, Pid: %d, Ppid: %d, g_val: %d, &g_val=%p\n", getpid(), getppid(), g_val, &g_val); sleep(1); if(cnt == 0) { g_val=200; printf("child change g_val: 100->200\n"); } cnt--; } } else { //father while(1) { printf("father, Pid: %d, Ppid: %d, g_val: %d, &g_val=%p\n", getpid(), getppid(), g_val, &g_val); sleep(1); } } sleep(100); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
实验结果如下:
child, Pid: 6781, Ppid: 6780, g_val: 100, &g_val=0x60105c father, Pid: 6780, Ppid: 30413, g_val: 100, &g_val=0x60105c child change g_val: 100->200 child, Pid: 6781, Ppid: 6780, g_val: 200, &g_val=0x60105c father, Pid: 6780, Ppid: 30413, g_val: 100, &g_val=0x60105c- 1
- 2
- 3
- 4
- 5
这是一个很神奇的现象,父进程和子进程的
g_val选项的地址是一样的,但是读取出来的值却不一样,这是为什么呢?说明这里的地址,并不是物理地址,而是虚拟地址,也叫做线性地址
虚拟地址和物理地址
下面就来研究的是,虚拟地址和物理地址之间是如何进行转换的
地址的转换
由前面的内容知道,进程是由进程的代码和数据以及内核数据结构组成的,那么当一个进程生成的时候会创建其对应的
PCB用来管理进程中的数据,而在进程中的数据会根据具体的类型而放入不同的地址空间中,例如栈区,堆区,代码区等等…而实际上,这个区域只是一个虚拟的地址,由于一些原因(后续补充),存在一个叫做页表的映射关系,将虚拟地址和物理地址进行一一映射,具体的表现如下所示:
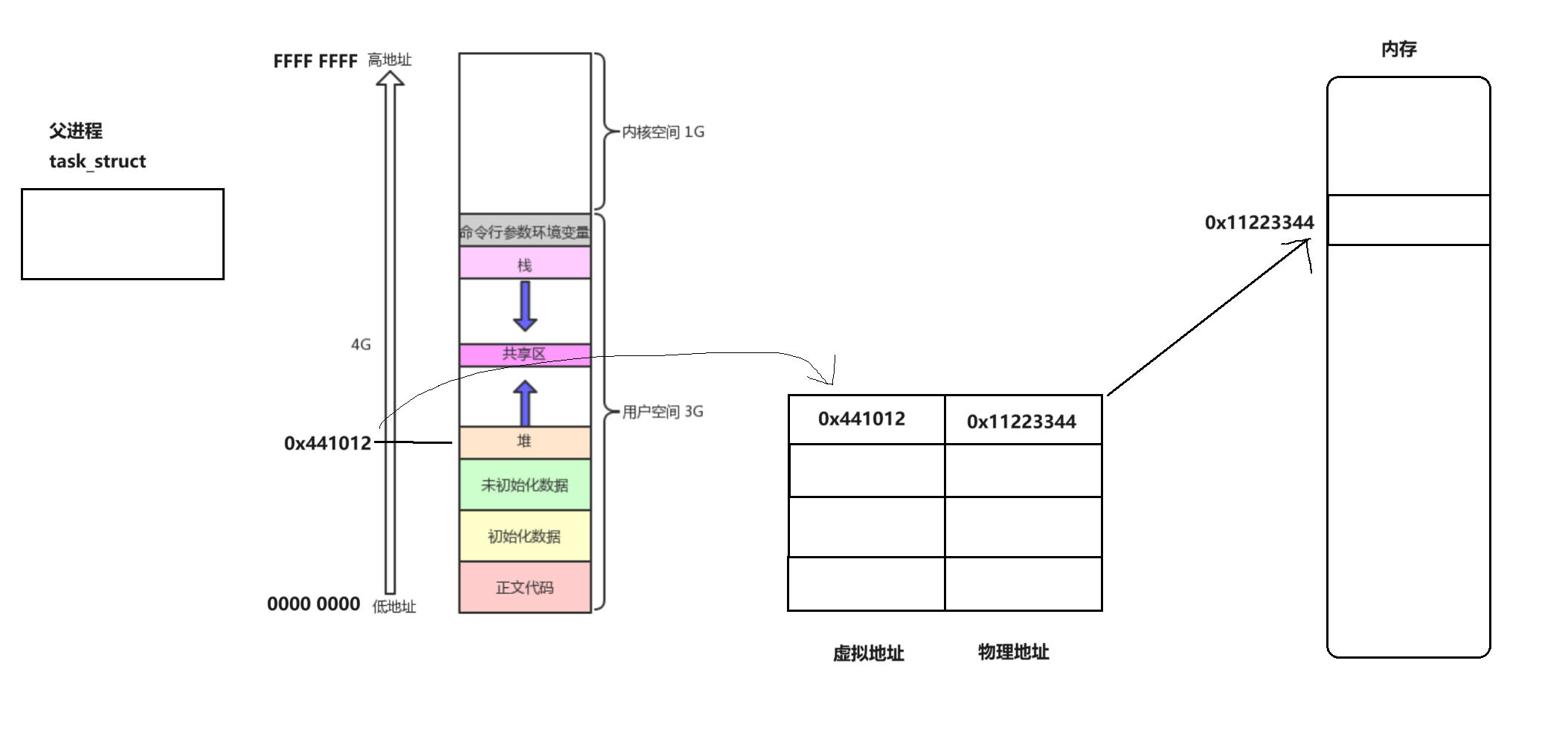
上图即展示了页表的映射关系的具体含义,对于前面图片中的内容只是一个虚拟地址,打印出来的信息也并非实际的物理地址,而真正的物理地址则是通过页表进行一个一一映射的关系,通过这个一一映射就能够找到物理地址,这个物理地址才是真正存储信息的地方那对于子进程来说是如何解释的?
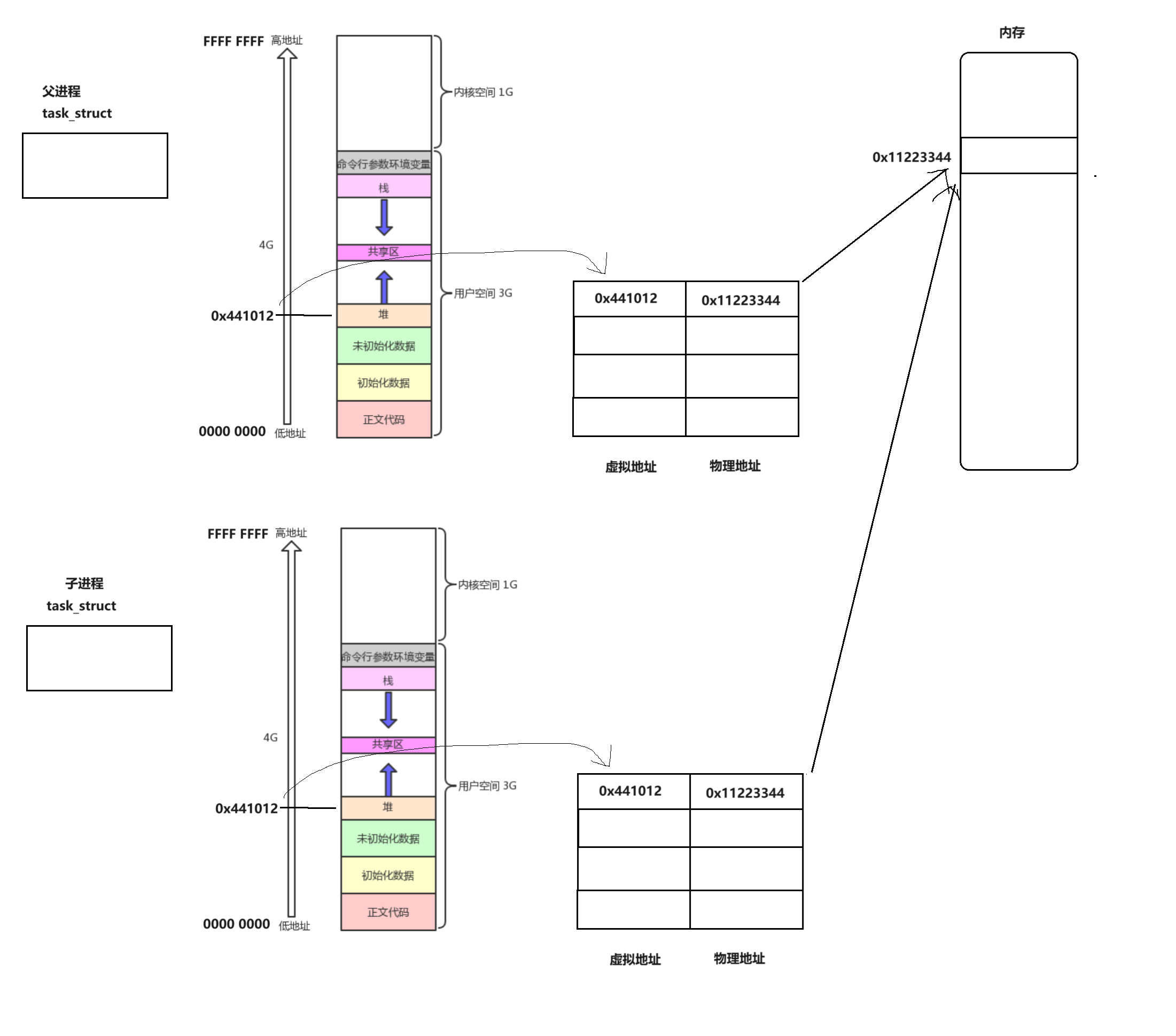
由前面的理论基础可以得出这样的一个结论,当使用fork创建子进程的时候,为子进程创建自己的
PCB,对于代码和数据,如果发生了变化就使用写时拷贝完成一份拷贝,这样可以保证进程的互不干扰独立性,因此对于上面的场景,当对于创建子进程的时候,本质上就是直接复制了一份上面图片中的内容,并将这个task_struct变成子进程:下图中所示的页表是一部分,实际上的页表还有其他的组成部分
而当子进程或者父进程要发生数据改变的时候,就会发生写时拷贝,具体的产生过程如下: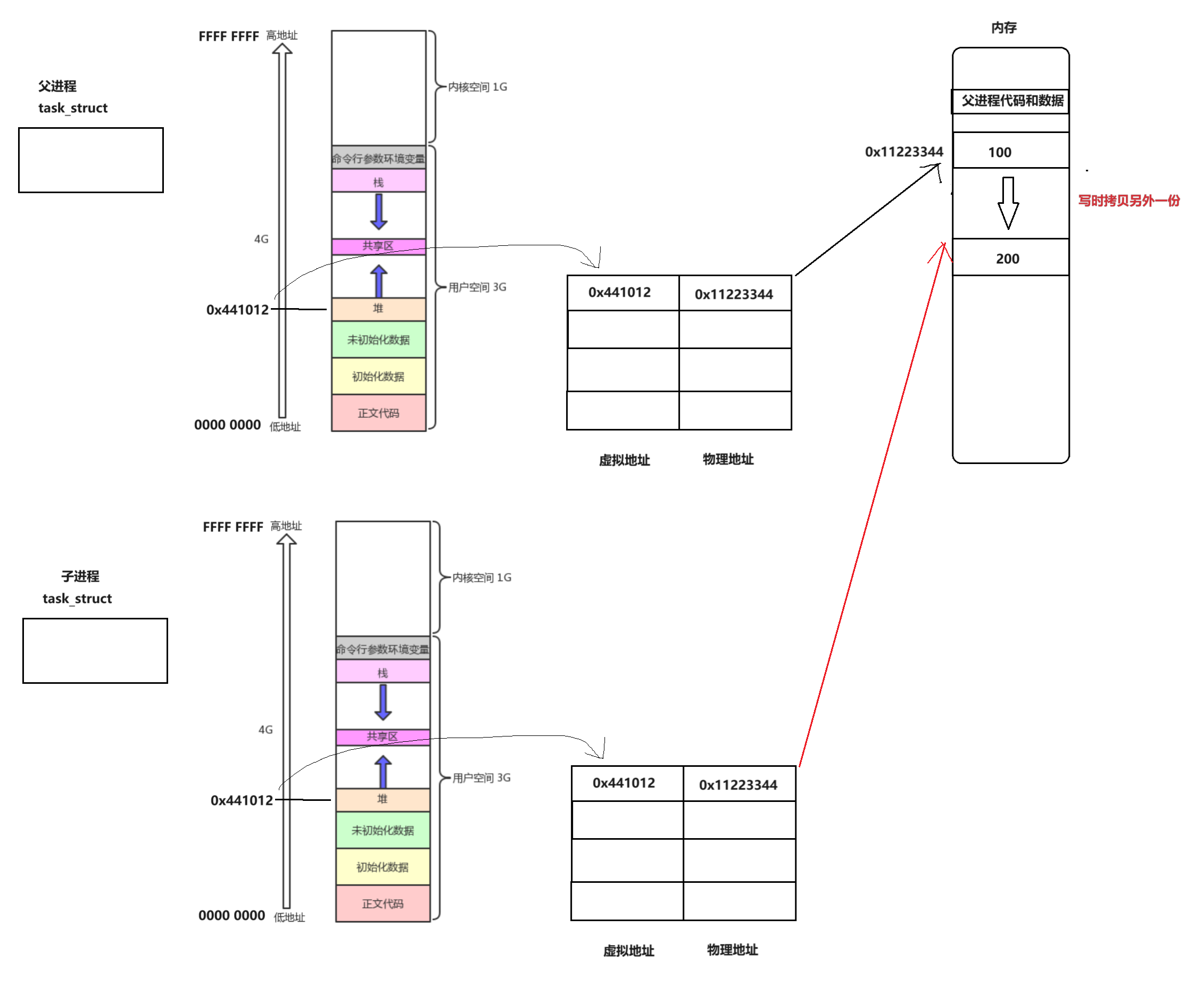
这样,就解释清楚了写时拷贝的含义,写时拷贝是发生在物理内存中的拷贝过程,整个过程是由操作系统来完成的,保证了进程之间的独立性
地址空间是什么?
简单来说,地址空间就是它:
每一个进程都会有一个这样的地址空间,而对于地址空间是需要进行管理的,那么如何对地址空间进行管理?答案是先描述再组织,因此,如何对地址空间进行描述?地址空间最终一定是一个内核的数据结构对象,简单来说就是一个内核的结构体,正如
task_struct一样,在Linux内核中有一个名字,叫做mm_struct,而这个数据是如何进行管理的?答案很明显,也是在内核数据结构中进行的管理在
Linux内核源码中,来查看这个结构体的存在性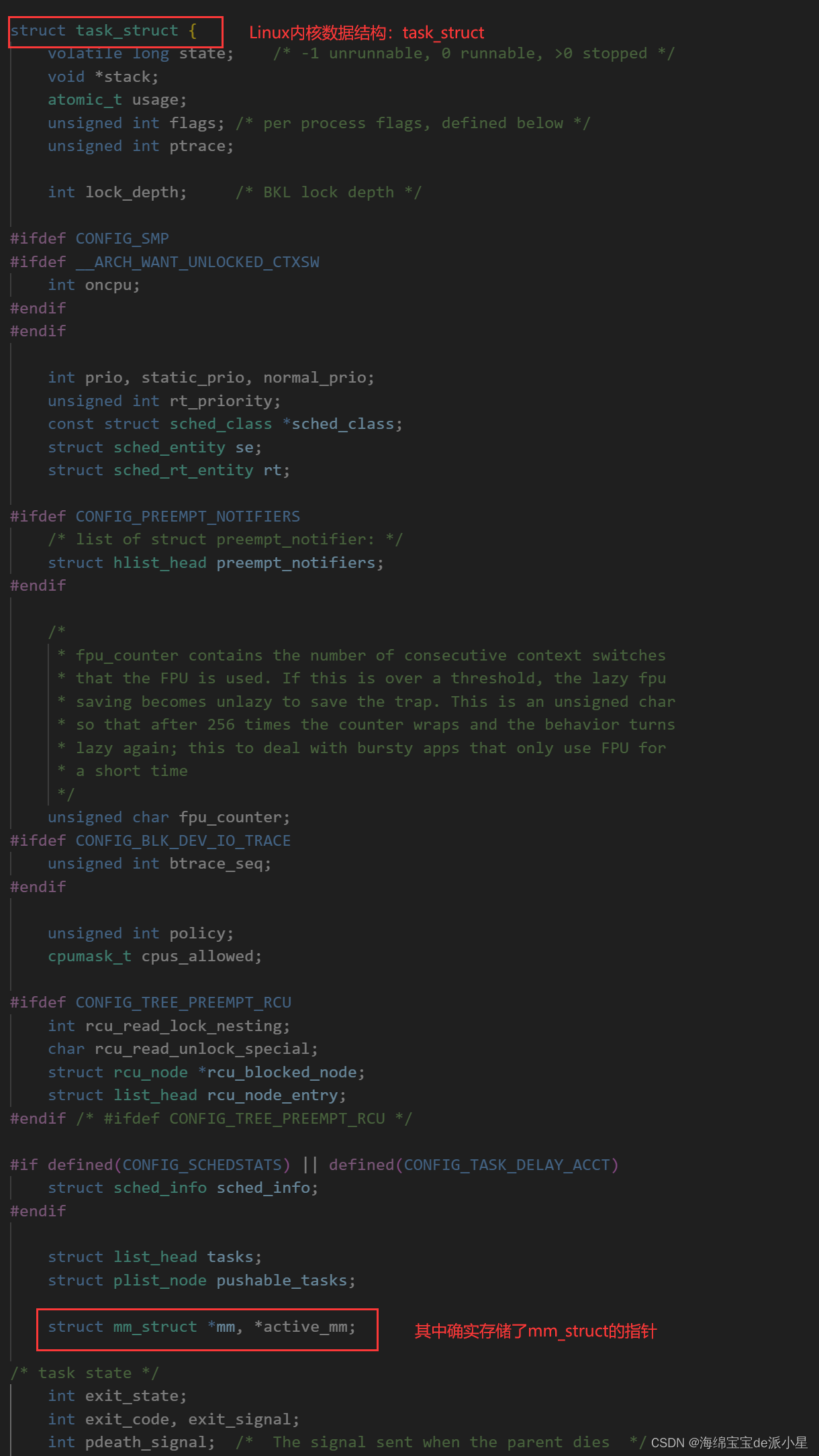
转到关于它的定义,观看它内部的定义实现方式:
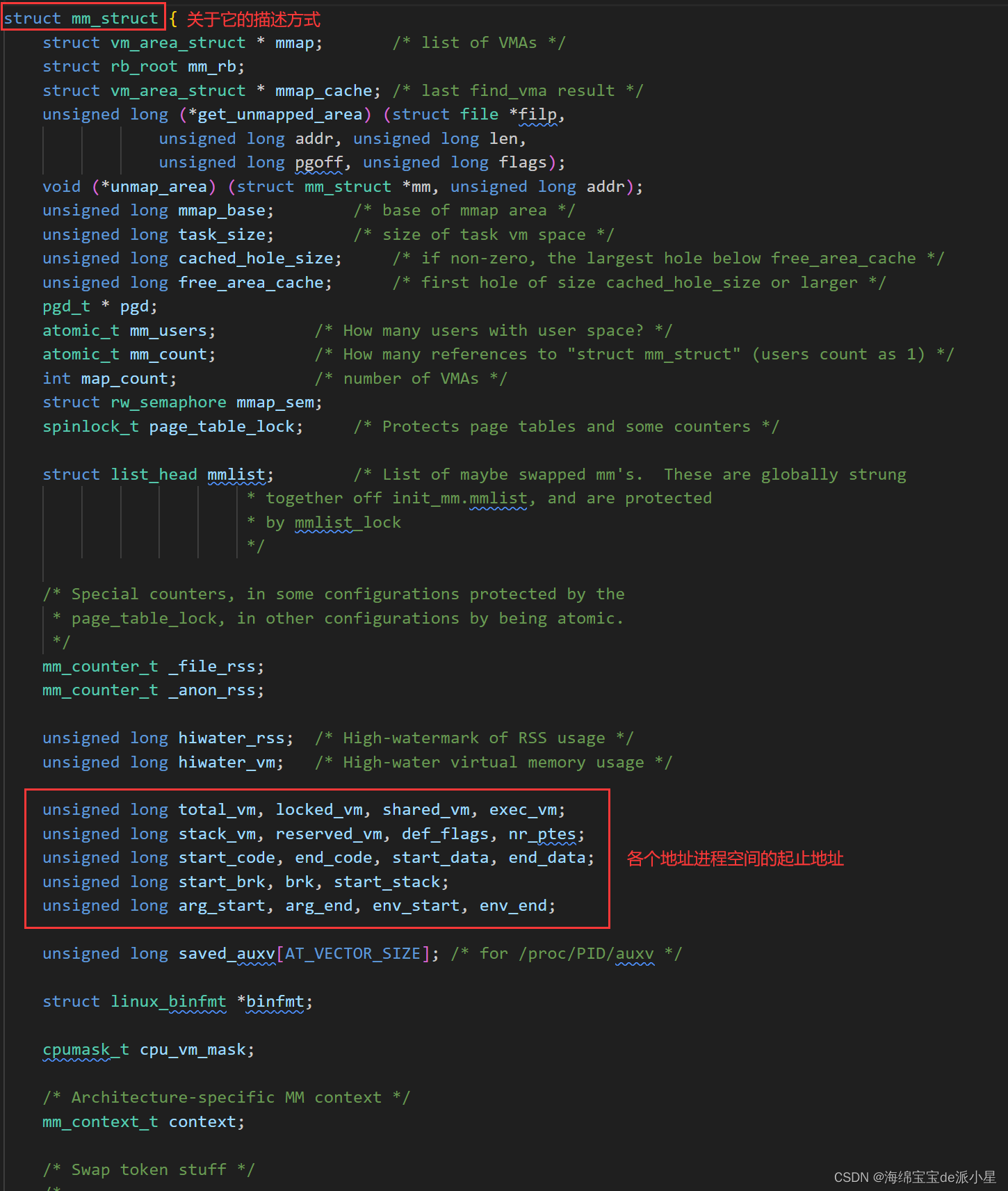
对于mm_struct来说,它通过定义了各个区域的起止位置来进行管理数据为什么要有地址空间呢?
先说结论:
- 让进程以统一的视角看待内存,任意一个进程,都可以通过地址空间和页表,将杂乱无序的内存数据变成有序的空间,也就是说这是一个变无序为有序的过程
- 存在虚拟地址空间,可以有效的进行进程访问内存的安全检查
- 将进程管理和内存管理进行耦合
- 通过页表,可以让进程映射到不同的物理内存中,从而实现进程的独立性
下面对于上面的结论进行一一的解释:
1. 变无序为有序的过程
这个过程是很好理解的,由于页表的存在,因此具体的实际内存中的数据不必排放到一块,而是可以进行不同位置的存储,但是在管理的角度来看,通过虚拟地址来进行管理是相当方便的,每一个地方都被分门别类的具体一一列举了出来,这样不仅便于管理,同时也可以最大化的利用内存中的空间
2. 访问内存的安全检查
讲到这点,就必须对页表进行进一步的补充说明了,实际上页表中存储的不仅仅有虚拟地址和物理地址,还有其他很多的信息,例如这里的访问权限字段
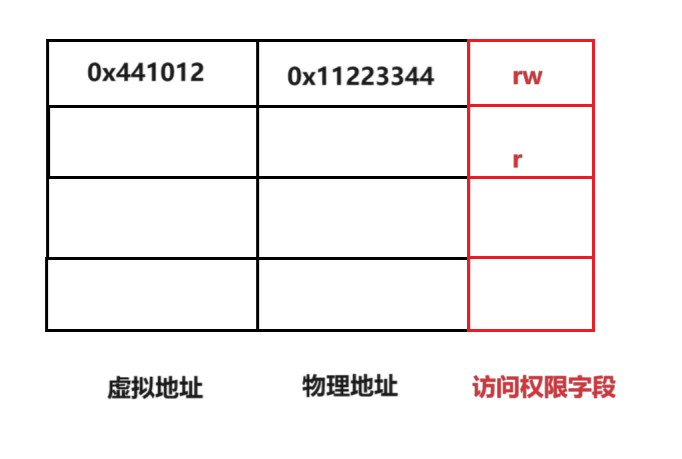
那么首先是解释访问权限字段存在的意义:可以有效避免进行修改,保护进程的数据等功能,例如下面的这个具体事例#include//#include int main() { char* str = "hello linux"; *str = 'H'; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在
gcc的编译器下,这是可以通过编译的,原因是这里的一个常量字符串的起始地址交给了一个字符指针str,而对于str来说将它的指向内容改成H,这个本身是可以的,但是问题出现在,str指向的内容实际上是一个字符常量区,而这个区域内的数据是不可以被修改的,因此如果要进行修改的话是不被允许的,那么页表是如何进行保护的呢?在执行程序的时候会引发段错误,这就是页表的功劳,当使用虚拟地址进行映射到物理地址的过程中,在进行页表的权限访问字段的时候会发现这个字段的访问权限是只读权限,但是现在要进行写入,很明显这是不被允许的行为,因此就会终止这种行为,因此页表中的权限访问字段就有这样的功能,可以进行访问内存的安全检查
3. 将进程管理和内存管理进行耦合
在解释这个结论前,还需要补充一下页表的内容,页表中还存在一列,它的意义是查看是否被分配和是否有内容
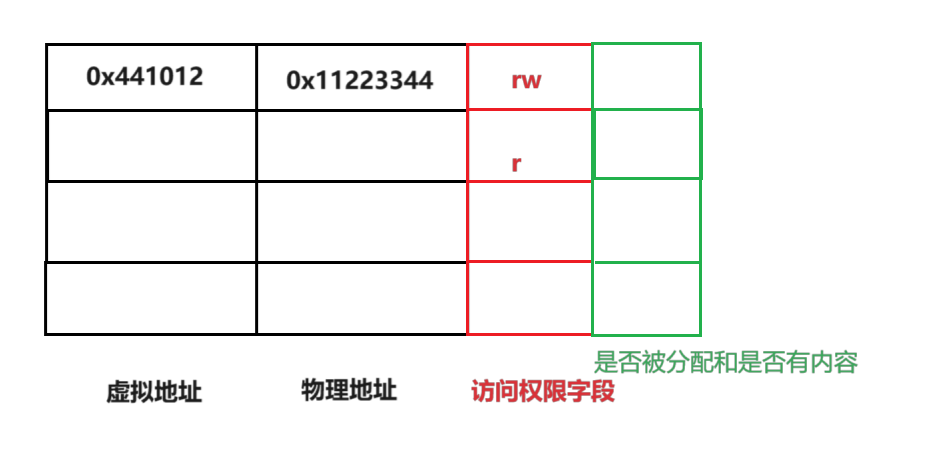
在实际中是采用一个0和1来表示是否有没有被分配和内容的,在实际进程管理控制过程中,虚拟地址首先会放到页表中,而当需要和内存地址进行交互的时候,就会通过这个分配和内容的内容表来进行判断,到底内存有没有分配具体的物理地址给这部分内容,如果没有就会进行分配等信息,也是方便于进程的管理这样做,就把进程管理和内存管理这两个模块的耦合度大大降低,两个模块控制系统互不干扰,这样就实现了进程的独立性
写时拷贝的原理
对于前面对于进程地址空间的描述中有下面的理解:当使用fork创建了子进程后,子进程和父进程依旧共享着代码和数据,但如果子进程和父进程中有一个发生了对数据的修改,那么就会触发写时拷贝,将原来的数据拷贝一份,让改变的那个进程的数据段指向新拷贝出的数据段,这样做以维护进程之间的独立性,那么具体是如何实现的这个过程?操作系统又是如何进行拷贝的这个操作呢?
原理其实就是上图所展示的原理,当进程没有遇到fork之前都按照正常的逻辑进行运行,代码段和数据段对应页表中的访问权限是默认的情况,而当遇到fork这一系统调用的时候,在进行创建子进程的这个过程中,就会将数据段和代码段对应到页表中地址空间内的访问权限字段全部改成只读的权限,当进程运行到需要进行修改数据的操作的时候,就会通过页表去物理地址空间内进行修改,但是此时页表对应的访问权限字段的访问权限是只读,不允许发生写入的操作,此时操作系统就会去辨别这是什么原因导致的出错也就是说,当页表的转换发生权限问题进行报错的时候,实际上是有两种可能的,一种是说真的出错了,比如要在字符常量区发生写入的改变,这肯定是不允许的,但还有一种情况是不是真的出错,而是触发了要让操作系统进行写时拷贝内容的一种策略,操作系统在观察到进程在运行到某个地方出现异常的时候就会去看具体的原因是什么,发现是触发了这个策略后,操作系统在这个时候就介入了这个阶段进行修改,进行拷贝等等的一系列操作
-
相关阅读:
大学宿舍IP一键视频对讲
彻头彻尾理解JVM系列之七:对象在分代模型中的流转过程是怎样的?
C++ 11/14/17/20 核心特性列表
7天酒店蝉联“年度杰出投资价值酒店品牌” 加速下沉市场拓展
Nginx架构基础
基于vue3和element-plus的省市区级联组件
国内较好的iPaaS供应商有哪些?
通过公式和源码解析 DETR 中的损失函数 & 匈牙利算法(二分图匹配)
OkHttp网络请求读写超时
详解Web应用安全系列(2)注入漏洞之XSS攻击
- 原文地址:https://blog.csdn.net/qq_73899585/article/details/133946959
