-
使用 ClickHouse 深入了解 Apache Parquet (二)
【squids.cn】 全网zui低价RDS,免费的迁移工具DBMotion、数据库备份工具DBTwin、SQL开发工具等
这篇文章是我们的 Parquet 和 ClickHouse 博客系列的第二部分。在这篇文章中,我们将更详细地探讨 Parquet 格式,重点介绍使用 ClickHouse 读写文件时要考虑的关键细节。对于更有经验的 Parquet 用户,我们还讨论了用户在编写 Parquet 文件时可以进行的优化,以最大限度地提高压缩率,以及使用并行化优化读取性能的一些最新进展。
对于我们的示例,我们继续使用英国房价数据集。其中包含 1995 年至撰写本文时英格兰和威尔士房地产支付价格的数据。我们以 Parquet 格式将其分发到公共 s3 存储桶中s3://datasets-documentation/uk-house-prices/parquet/。我们使用 ClickHouse Local 读取和写入本地和 S3 托管的 Parquet 文件。ClickHouse Local 是 ClickHouse 的易于使用的版本,非常适合需要使用 SQL 对本地和远程文件执行快速处理而无需安装完整数据库服务器的开发人员。最重要的是,ClickHouse Local 和 ClickHouse Server 共享相同的 Parquet 读写代码,因此任何细节都适用于两者。有关更多详细信息,请参阅本系列的上一篇文章。
Parquet 格式概述
结构
了解Parquet文件格式可以让用户在写入文件时做出重要的决定,这将直接影响压缩级别和后续的读取性能。以下描述是一种简化,但涵盖了大多数用户需要的细节。
Parquet 格式依赖于三个分层相关的主要概念:行组、列块和页面。
在较高级别上,Parquet 文件被分为多个行组。行组最多包含 N 行,在编写本文时确定。
在每个行组中,每列都有一个块 - 每个块都包含其各自列的数据,从而提供列方向。虽然理论上每个列块的行数可能不同,但为了简化,我们假设这是相同的。这些块由页面组成。原始数据存储在这些数据页中。每个数据页的最大大小是可以配置的,但目前在 ClickHouse 中尚未公开,它使用默认值 1MB。数据块在写入之前也会被压缩(见下文)。
我们将这些概念和逻辑结构可视化如下。出于说明目的,我们假设行组大小为 10,总共 19 行,每行三列。我们假设我们的数据页大小导致每页一致三个值(除了第一行组的每页上的最后一个块):
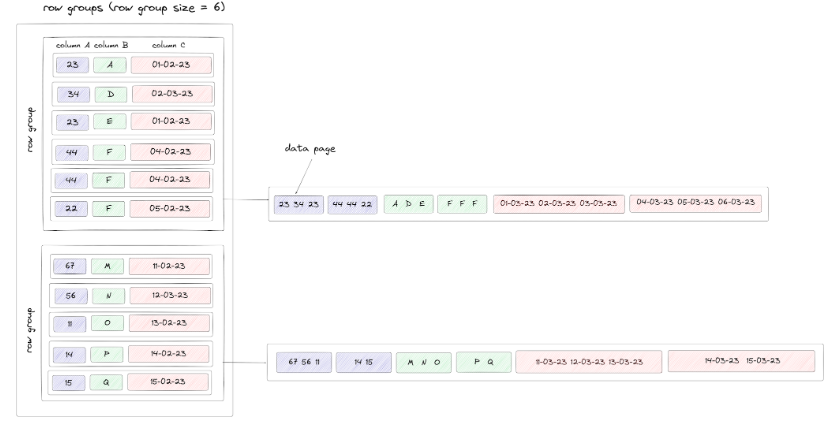
有两种类型的页面:数据页面和字典页面。当字典编码应用于数据页中的值时,就会产生字典页。对于 ClickHouse,写入 Parquet 文件时默认启用此功能。对于已字典编码的数据页,它们前面将是字典页。这实际上意味着字典和数据页交替,如下所示。可以对字典页面大小施加限制,默认为 1MB。如果超过此值,写入器将恢复写入包含值的纯数据页。
以上是 Parquet 格式的简化。对于寻求更深入理解的用户,我们建议阅读有关重复和定义级别的内容,因为这些对于充分理解数据页如何与数组和嵌套类型以及空值相关的工作方式也至关重要。
请注意,虽然 Parquet 被正式描述为基于列,但行组的引入和列块的顺序存储意味着它通常被描述为基于混合的格式。这使得该格式的读者可以轻松地实现投影和下推,如下所述。
元数据、投影和下推
除了存储数据值之外,Parquet 格式还包括元数据。这被写在文件末尾的页脚中,以方便单遍写入(更有效),并包括对行组、块和页面的引用。
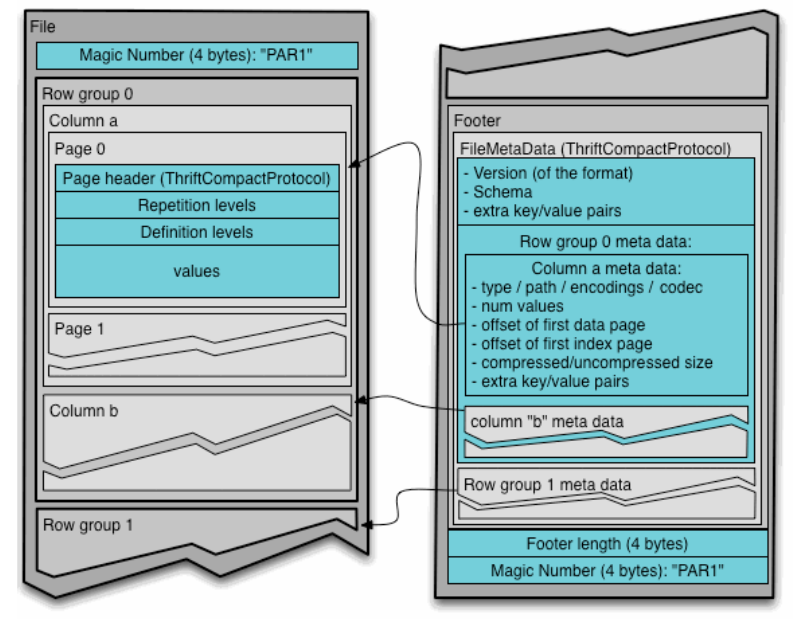
除了存储数据模式和协助解码的信息,如偏移值和所使用的编码,Parquet还包括查询引擎可以利用来跳过列块的信息。读取器首先应该读取文件元数据,以找到他们感兴趣的所有列块,然后只按顺序读取那些所需的列块。这被称为投影下推,旨在最小化I/O。
此外,可以在行组级别包括统计数据,描述每列的最小和最大值。这允许读取器考虑这些信息与任何谓词(如果在SQL中查询,为WHERE子句)相对比,进一步跳过列块。这个谓词下推目前还没有在ClickHouse中实现,但是计划添加[1][2][3]。最后,官方规范允许使用单独的元数据文件引用多个Parquet文件,例如,每列一个。ClickHouse目前不支持这个,尽管我们计划增加支持。
读取和写入行组
使用 ClickHouse 写入 Parquet 文件时,用户可能希望控制写入的行组数量,以增加读取的并行化量 - 有关更多详细信息,请参阅“并行读取”。截至撰写本文时,INSERT INTO FUNCTION 如果用户希望在编写时控制行组的数量,我们建议用户使用该语法。此语法的设置允许轻松推断行组的数量,行数等于以下最小值:
-
min_insert_block_size_bytes:设置块中的最小字节数,较小的块会被压缩为较大的块。这有效地通过字节大小限制了行数。默认为 256MB 未压缩。
-
min_insert_block_size_rows:传递给箭头客户端的块中的最小行数,较小尺寸的块被压缩为较大尺寸的块。默认为 1m。
-
output_format_parquet_row_group_size:行组大小默认为 1m。
用户可以根据行总数、平均大小和行组的目标数量调整这些值。
对于SELECT使用FORMAT子句(例如 )的查询SELECT * FROM uk_price_paid FORMAT Parquet以及 子句INTO OUTFILE,决定组大小的因素更加复杂。最重要的是,这些方法往往会导致文件中出现大量行组,从而可能对压缩和读取性能产生负面影响。更多详细信息请参见此处。出于这些原因,我们目前建议使用该INSERT INTO FUNCTION方法。
这两种导出 Parquet 文件的方法的差异可能会导致文件大小发生变化,具体取决于方法和产生的有效压缩。对于从我们之前的博客文章返回的读者,这解决了为什么不同的查询产生可变的文件大小 - 较小的行组大小也不能压缩。一般来说,我们推荐这种INSERT INTO FUNCTION 编写方法,因为它使用更合理的默认值并允许轻松控制行组大小。在未来的版本中,我们计划解决任何行为不一致的问题。
其他用于编写 Parquet 文件的工具以及官方 Apache Arrow 库(由 ClickHouse 使用)也允许配置行组的数量。了解行组大小可能如何影响读取性能。
类型与编码
Parquet是一个二进制格式,其中列值使用特定的类型存储,要么是布尔值,要么是数值(int32, int64, int96, float, double),字节数组(binary),或固定长度的二进制值。这些基本类型可以使用信息进行注解,指定它们应该如何被解释为创建“逻辑类型”,如String和Enum。例如,逻辑String类型在字节数组中进行编码,其中注解指示UTF8编码。更多详情请参见此处。
自初步设想以来,Parquet已经有了许多扩展,尤其是围绕数据如何被编码的。这包括:
-
字典编码构建了一个列的所有不同值的字典,并用字典中的相应索引替换原始值。这对于低基数列特别有效,并帮助在列类型之间提供稳定的性能。这可以应用于数字和字节数组为基础的类型。
-
字典编码的值、布尔值以及重复和定义级别都是用Run Length Encoded(RLE)进行编码的。这通过用一个发生次数和一个表示重复的数字来替换连续重复的值来压缩列。在这种情况下,当更多的相同值连续出现时,可以实现更高的压缩。列的基数因此也直接影响压缩效率。注意,这个RLE与Bit Packing结合使用,以最小化所需的存储位数。
-
Delta编码可以应用于整数值。在这种情况下,存储值之间的差值而不是实际值(除了第一个值)。当连续的值有小的或恒定的变化时,这特别有效,例如以毫秒为粒度的DateTime值,因为差值占用更少的位。
-
现在也有其他编码技术可用,包括Byte Stream Split。
目前,ClickHouse在写入Parquet文件时使用默认的编码,这默认启用字典编码。不能用设置来控制用于列的编码,阻止了对整数使用delta编码,尽管这正在作为未来改进的一部分被考虑(见下文)。
Parquet类型在读取时必须转换为ClickHouse类型,写入时反之亦然。可以在此处找到支持的Parquet逻辑类型及其等价的ClickHouse类型的完整列表,有一些尚在实施中。
字符串
由ClickHouse写入的文件也会为字符串使用原始BYTE_ARRAY类型。如果您打算稍后使用ClickHouse读取这些文件,这是足够的,因为这与我们自己的字符串的内部表示方式相一致,其中字节按原样存储(有单独的函数变体,它们在假设字符串包含一组表示UTF-8编码文本的字节的情况下工作,例如lengthUTF8)。然而,某些应用程序可能需要字符串用逻辑类型String来表示。在这种情况下,您可以在写入文件之前设置output_format_parquet_string_as_string=。
枚举
ClickHouse Enums将在ClickHouse的未来版本中被序列化为Int8/Int16,当写入Parquet文件时,这要归功于最近的改进(支持待定,允许它们作为字符串写入)。相反,读取文件时,这些整数类型可以转换为ClickHouse Enums。Parquet文件中的字符串也将在可能的情况下转换为ClickHouse Enums。Parquet Enums可以读作字符串或兼容的ClickHouse Enum。
检查Parquet结构
为了检查Parquet文件的结构,用户历史上需要使用第三方工具,如parquet-tools。随着ClickHouse的22.4版本的即将发布,用户可以使用简单的查询来获取这些元数据,这要归功于ParquetMetadata输入格式的添加。我们在下面使用它查询我们的房价Parquet文件的元数据,它将元数据输出为单行。为了帮助可读性,我们还指定了输出格式PrettyJSONEachRow(也是22.4的新增功能)并仅显示部分元数据。注意输出包括行组数、使用的编码以及列统计信息,如大小和压缩率。
- ./clickhouse local --query "SELECT * FROM file('house_prices.parquet', ParquetMetadata) FORMAT PrettyJSONEachRow"
- {
- "num_columns": "14",
- "num_rows": "28113076",
- "num_row_groups": "53",
- "format_version": "2.6",
- "metadata_size": "65503",
- "total_uncompressed_size": "365131681",
- "total_compressed_size": "255323648",
- "columns": [
- {
- "name": "price",
- "path": "price",
- "max_definition_level": "0",
- "max_repetition_level": "0",
- "physical_type": "INT32",
- "logical_type": "Int(bitWidth=32, isSigned=false)",
- "compression": "LZ4",
- "total_uncompressed_size": "53870143",
- "total_compressed_size": "54070424",
- "space_saved": "-0.3718%",
- "encodings": [
- "RLE_DICTIONARY",
- "PLAIN",
- "RLE"
- ]
- },
- ...
- ],
- "row_groups": [
- {
- "num_columns": "14",
- "num_rows": "1000000",
- "total_uncompressed_size": "10911703",
- "total_compressed_size": "8395071",
- "columns": [
- {
- "name": "price",
- "path": "price",
- "total_compressed_size": "1823285",
- "total_uncompressed_size": "1816162",
- "have_statistics": 1,
- "statistics": {
- "num_values": "1000000",
- "null_count": "0",
- "distinct_count": null,
- "min": "50",
- "max": "6250000"
- }
- },
- ...
- ]
- },
- ...
- ]
- }
压缩
与其他交换格式相比,Parquet提供了出色的压缩。如下所示,我们比较了使用它们的默认设置的CSV、行分隔的JSON和使用各种压缩技术的Parquet的房价数据集的大小。在这个例子中,我们没有使用ORDER BY子句导出,而是依赖于ClickHouse的自然排序(随机的,不是确定性的),使用ClickHouse Local和file函数。
INSERT INTO FUNCTION file('house_prices.. ) SELECT * FROM uk_price_paid' 注意:不要给parquet格式添加压缩扩展名,例如,house_prices.parquet.gzip。这将导致Parquet文件在写入后再次被压缩 - 这是一个不必要的开销,其好处将是最小的。
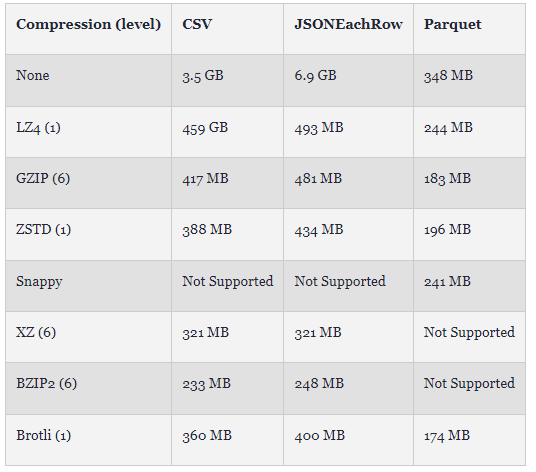
如图所示,即使没有压缩,Parquet 也仅比使用 BZIP2 的基于文本的 CSV 最佳替代方案大 40%。通过 Brotli 压缩,Parquet 比此压缩的 CSV 小 30%。虽然 BZIP2 实现了文本格式的最佳压缩率,但这种压缩方法也相当慢。如下图所示,我们显示了上述时间(3 次运行中最快的一次)。虽然这取决于 ClickHouse 实现和硬件 (Mac Pro 2021),但 Parquet 的写入速度可与所有压缩文本格式相媲美,并且压缩时的开销最小。与采用 BZIP2 的 CSV 相比,Parquet 的最佳压缩 (Brotli) 速度几乎快 10 倍。对于 Parquet,这种压缩技术的速度也是其他格式的两倍,ZSTD 和 GZIP 提供与 BZIP2 的 CSV 类似的压缩,速度超过 25 倍。尽管 Parquet 编码目前是单线程的(与文本格式不同),但该格式在写入性能方面具有优势。我们预计未来对并行 Parquet 编码的改进将对这些写入时序产生重大影响。
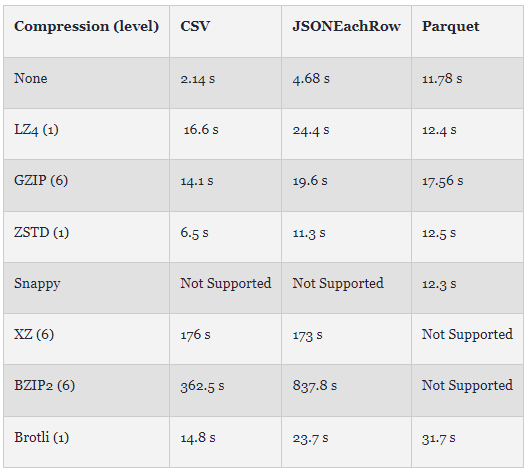
注意:默认情况下 (23.3),ClickHouse在压缩 Parquet 文件时使用 LZ4(尽管由于与 Spark 等工具的兼容性,这可能会发生变化)。这与 Snappy 的 Apache Arrow 默认值不同,尽管可以通过设置output_format_parquet_compression_method进行更改。
上述测试不包括 ClickHouse 原生格式。如果在不需要独立于存储的格式的 ClickHouse 实例之间(例如,在气隙环境中)移动数据,我们建议使用 ZST 压缩的这种格式。这将提供与 Parquet 相当的文件大小,同时提供导入 ClickHouse 的最快格式。
- INSERT INTO FUNCTION file('house_prices.native.zst') SELECT *
- FROM uk_price_paid
- -rw-r--r-- 1 dalemcdiarmid wheel 189M 26 Apr 14:44 house_prices.native.zst
数据排序
敏锐的读者可能已经注意到RLE编码依赖于连续的值。从逻辑上讲,当使用ORDER BY查询子句写入数据时,只需简单地对数据进行排序,就可以改进此压缩技术。如果从表中写入大量行,这种方法有其局限性,因为任意的排序顺序可能会受到内存的限制:用于排序的内存量与数据的体积成正比。在这种情况下,用户有几个选项:
-
利用设置max_bytes_before_external_sort。如果它被设置为0(默认值),则禁用外部排序。如果启用它,当需要排序的数据量达到指定的字节数时,收集的数据将被排序并转储到临时文件中。这将比内存中的排序慢得多。这个值应该谨慎设置,且小于max_memory_usage设置。
-
如果ORDER BY表达式具有与表排序键相一致的前缀,您可以使用optimize_read_in_order设置。默认情况下,此设置是启用的,这意味着利用了数据的排序,避免了内存问题。注意,禁用此设置有性能优势,特别是对于具有大LIMIT的查询,以及在WHERE条件匹配之前需要读取许多行的情况。
在大多数情况下,ClickHouse表的排序(通过表创建时的ORDER BY子句)已经为查询性能和压缩进行了优化。虽然选项2通常是有意义的并且会立即带来改进,但结果会有所不同。用户还可以查看先前显示的Parquet元数据,以识别压缩不足的列和可能的ORDER BY子句候选列。当列的顺序将较低的基数键放在ORDER BY子句的第一位时,可能会实现最佳的压缩(类似于ClickHouse),从而确保值的最大连续序列。
使用UK房价表的ORDER BY键(postcode1, postcode2, addr1, addr2),我们重复使用GZIP导出Parquet。这使得我们的parquet文件减少了大约20%,减至148MB,但牺牲了写入性能。同样,我们可以使用新的ParquetMetadata来识别每个列的压缩 —— 下面,我们突出显示了postcode1列排序前后的差异。注意这一列的未压缩大小怎样显著地减少了。
- INSERT INTO FUNCTION file('house_prices-ordered.parquet') SELECT *
- FROM uk_price_paid
- ORDER BY
- postcode1 ASC,
- postcode2 ASC,
- addr1 ASC,
- addr2 ASC
- 0 rows in set. Elapsed: 38.812 sec. Processed 28.11 million rows, 2.68 GB (724.34 thousand rows/s., 69.07 MB/s.)
- -rw-r--r-- 1 dalemcdiarmid wheel 148M 26 Apr 13:42 house_prices-ordered.parquet
- -rw-r--r-- 1 dalemcdiarmid wheel 183M 26 Apr 13:44 house_prices.parquet
- ./clickhouse local --query "SELECT * FROM file('house_prices.parquet', ParquetMetadata) FORMAT PrettyJSONEachRow"
- {
- "num_columns": "14",
- "num_rows": "28113076",
- "num_row_groups": "53",
- "format_version": "2.6",
- "metadata_size": "65030",
- "total_uncompressed_size": "365131618",
- "total_compressed_size": "191777958",
- "columns": [{
- "name": "postcode1",
- "path": "postcode1",
- "max_definition_level": "0",
- "max_repetition_level": "0",
- "physical_type": "BYTE_ARRAY",
- "logical_type": "None",
- "compression": "GZIP",
- "total_uncompressed_size": "191694",
- "total_compressed_size": "105224",
- "space_saved": "45.11%",
- "encodings": [
- "RLE_DICTIONARY",
- "PLAIN",
- "RLE"
- ]
- },
- INSERT INTO FUNCTION file('house_prices-ordered.parquet') SELECT *
- FROM uk_price_paid
- ORDER BY
- postcode1 ASC,
- postcode2 ASC,
- addr1 ASC,
- addr2 ASC
- ./clickhouse local --query "SELECT * FROM file('house_prices-ordered.parquet', ParquetMetadata) FORMAT PrettyJSONEachRow"
- {
- "num_columns": "14",
- "num_rows": "28113076",
- "num_row_groups": "51",
- "format_version": "2.6",
- "metadata_size": "62305",
- "total_uncompressed_size": "241299186",
- "total_compressed_size": "155551987",
- "columns": [
- {
- "name": "postcode1",
- "path": "postcode1",
- "max_definition_level": "0",
- "max_repetition_level": "0",
- "physical_type": "BYTE_ARRAY",
- "logical_type": "None",
- "compression": "GZIP",
- "total_uncompressed_size": "29917",
- "total_compressed_size": "19563",
- "space_saved": "34.61%",
- "encodings": [
- "RLE_DICTIONARY",
- "PLAIN",
- "RLE"
- ]
- },
并行读取
从历史上看,ClickHouse中的Parquet文件的读取是一个顺序操作。这限制了性能,这意味着希望并行读取的用户需要拆分他们的Parquet文件 —— 当在路径中提供一个全局模式时,ClickHouse会在一组文件之间并行读取。通过使用ClickHouse Local在一个文件和29个文件(按年分区)上计算每年的平均价格,可以显示下面的区别。这里的所有文件都使用了先前显示的ORDER BY键和GZIP进行编写,我们使用三次运行中最快的一次。
- SELECT
- toYear(toDate(date)) AS year,
- round(avg(price)) AS price,
- bar(price, 0, 1000000, 80)
- FROM file('house_prices.parquet')
- GROUP BY year
- ORDER BY year ASC
- ┌─year─┬──price─┬─bar(round(avg(price)), 0, 1000000, 80)─┐
- │ 1995 │ 67937 │ █████▍ │
- │ 1996 │ 71513 │ █████▋ │
- │ 1997 │ 78538 │ ██████▎ │
- │ 1998 │ 85443 │ ██████▊ │
- │ 1999 │ 96040 │ ███████▋ │
- │ 2000 │ 107490 │ ████████▌ │
- │ 2001 │ 118892 │ █████████▌ │
- │ 2002 │ 137957 │ ███████████ │
- │ 2003 │ 155895 │ ████████████▍ │
- │ 2004 │ 178891 │ ██████████████▎ │
- │ 2005 │ 189361 │ ███████████████▏ │
- │ 2006 │ 203533 │ ████████████████▎ │
- │ 2007 │ 219376 │ █████████████████▌ │
- │ 2008 │ 217043 │ █████████████████▎ │
- │ 2009 │ 213423 │ █████████████████ │
- │ 2010 │ 236115 │ ██████████████████▉ │
- │ 2011 │ 232807 │ ██████████████████▌ │
- │ 2012 │ 238385 │ ███████████████████ │
- │ 2013 │ 256926 │ ████████████████████▌ │
- │ 2014 │ 280024 │ ██████████████████████▍ │
- │ 2015 │ 297285 │ ███████████████████████▊ │
- │ 2016 │ 313548 │ █████████████████████████ │
- │ 2017 │ 346521 │ ███████████████████████████▋ │
- │ 2018 │ 351037 │ ████████████████████████████ │
- │ 2019 │ 352769 │ ████████████████████████████▏ │
- │ 2020 │ 377149 │ ██████████████████████████████▏ │
- │ 2021 │ 383034 │ ██████████████████████████████▋ │
- │ 2022 │ 391590 │ ███████████████████████████████▎ │
- │ 2023 │ 365523 │ █████████████████████████████▏ │
- └──────┴────────┴────────────────────────────────────────┘
- 29 rows in set. Elapsed: 0.182 sec. Processed 14.75 million rows, 118.03 MB (81.18 million rows/s., 649.41 MB/s.)
- SELECT
- toYear(toDate(date)) AS year,
- round(avg(price)) AS price,
- bar(price, 0, 1000000, 80)
- FROM file('house_prices_*.parquet')
- GROUP BY year
- ORDER BY year ASC
- …
- 29 rows in set. Elapsed: 0.116 sec. Processed 26.83 million rows, 214.63 MB (232.17 million rows/s., 1.86 GB/s.)
这里的示例是 file 函数,但这同样适用于其他表函数,例如 s3(尽管此处将应用一些因素 - 请参阅“关于 S3 的小注释”)。对于较大的文件,这种差异可能更明显。
幸运的是,最近在文件中并行化这项工作的进展极大地提高了性能(尽管可以做更多的事情 - 请参阅“未来的工作”)。这些改进目前仅与 s3 和 URL 函数相关,并且代表了改进并行化的初步努力。ClickHouse 的未来版本将并行读取和解码单个 Parquet 文件,包括文件函数,并由设置控制线程数(max_threads默认为 CPU 核心数)。下面,我们使用上述查询来查询单个 Parquet 文件,以突出显示更改后和未更改时的性能差异。请注意,这些文件位于 s3 上,最近的改进适用于此:
- SELECT
- toYear(toDate(date)) AS year,
- round(avg(price)) AS price,
- bar(price, 0, 1000000, 80)
- FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices_all.parquet')
- GROUP BY year
- ORDER BY year ASC
- 29 rows in set. Elapsed: 18.017 sec. Processed 28.11 million rows, 224.90 MB (1.56 million rows/s., 12.48 MB/s.)
- //with changes
- SET input_format_parquet_preserve_order = 0
- SELECT
- toYear(toDate(date)) AS year,
- round(avg(price)) AS price,
- bar(price, 0, 1000000, 80)
- FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices_all.parquet')
- GROUP BY year
- ORDER BY year ASC
- 29 rows in set. Elapsed: 8.428 sec. Processed 26.69 million rows, 213.49 MB (3.17 million rows/s., 25.33 MB/s.)
如图所示,这里的性能得到了显着提高。
行组的重要性
这里的并行化是在行组级别实现的。虽然实现可能会发生变化和进一步改进,但此改进为每个行组分配一个线程来负责读取和解码。为了避免过多的内存消耗,input_format_parquet_max_block_size控制每个线程一次解码的数量,从而确定内存中保存的未压缩数据量。控制这一点的能力对于高度压缩的数据或当您有许多线程时非常有用,这可能会导致高内存使用率。
鉴于当前在行组级别执行并行化,用户可能希望考虑其文件中的行组数量。如前所述,ClickHouse Local 可用于确定行组的数量:
- clickhouse@dclickhouse % ./clickhouse local --query "SELECT num_row_groups FROM file('house_prices.parquet', ParquetMetadata)"
- 53
请参阅前面的内容,了解在使用 ClickHouse 编写 Parquet 文件时如何使用设置来控制行组的数量。
因此,您至少需要与核心一样多的行组才能实现完全并行化。下面,我们查询该house_price.parquet文件的一个版本,该版本只有一个行组 - 请参阅此处了解其创建方式。请注意对查询性能的影响。
- SET input_format_parquet_preserve_order = 0
- SELECT
- toYear(toDate(date)) AS year,
- round(avg(price)) AS price,
- bar(price, 0, 1000000, 80)
- FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices-1-row-group.parquet')
- GROUP BY year
- ORDER BY year ASC
- 29 rows in set. Elapsed: 19.367 sec. Processed 26.64 million rows, 213.12 MB (1.05 million rows/s., 8.40 MB/s.)
反之,行组的高数量远远超过核心的数量也可能对性能产生不利影响。这可能会导致许多微小的读取,相对于实际的解码工作,增加IO延迟的量。如果只读取少数列,这种情况将最为明显,因为读取的碎片化。当选择所有列时,可以减轻这一问题,因为相邻的读取会被合并。使用s3和URL函数(参见“关于S3的简短说明”)进行读取时,这些行为最为明显。因此需要平衡并行解码和高效读取。行组的大小在100 KB到10MB的范围内可以被视为合理的大小。通过进一步的测试,我们希望我们在此处的建议可以更具具体性。
ClickHouse将每个正在读取的行组的压缩数据保留在内存中(以及线程数 * input_format_parquet_max_block_size用于未压缩数据)。因此,大的行组在使用大量线程进行读取时会非常占用内存。总之,默认值通常是合理的,但对于具有大量核心的机器或在低内存的环境中,用户可能考虑确保行组计数更高,并且其大小与可用内存和线程数量相匹配。如果正在读取文件,请考虑如果内存低或正在增加max_threads时的内存开销。
最后,我们之前设置了设置input_format_parquet_preserve_order = 0。默认值1是为了向后兼容性,并确保数据按原始顺序返回,即一次一个行组。这限制了可以并行的工作量。这是可能会变化的,但现在,为了最大的收益,需要这种行为的变化。
关于S3的简短说明
尽管Parquet文件的并行读取承诺为查询带来重大的改进,但其他因素也可能影响用户所经历的绝对查询时间。如果查询存储在S3上的数据,多个文件仍然带来了显著的好处。例如,s3Cluster函数需要多个文件以在群集中的所有节点上分布读取,发起节点在动态地发送匹配的每个文件之前创建到群集中的所有节点的连接。这增加了并行化和性能。您的服务器实例的区域位置和网络吞吐量也可能会显著影响查询性能。
我们之前注意到小行组(因此小列块)对读取性能的影响。这也可能影响S3的费用。从S3请求数据时,每个列块都会发出一个GET请求。较大的行组大小因此应该减少列块和导致的GET请求的数量,从而可能减少费用。同样,当请求连续的列时,这将被减轻,因为请求将被合并,并且应与并行解码的可能性相平衡。用户将需要实验以优化成本/性能。
多个文件和数据湖格式
尽管Parquet已经确定自己是数据湖的首选数据文件格式,但表通常会表示为位于存储桶或文件夹中的一组文件。虽然ClickHouse可以用于读取目录中的多个Parquet文件,但它通常只适用于ad-hoc查询。管理大型数据集变得繁琐,意味着像ClickHouse这样的工具的表抽象最好是宽松建立的,不支持模式演变或写入一致性。对于ClickHouse来说,最重要的是,这种方法将依赖于文件列表操作 - 在像s3这样的对象存储上可能很昂贵。过滤数据要求所有数据都被打开和读取,除了通过使用命名模式上的glob模式来限制文件的有限能力。
现代数据格式,如Apache Iceberg,旨在以开放和可访问的方式解决这些挑战,为数据湖中的文件带来SQL表样的功能,包括以下功能:
-
跟踪表随时间变化的模式演变。
-
创建定义特定版本的数据的快照的能力。这些版本可以被查询,允许用户在代之间"时间旅行"。
-
支持快速回滚到数据的先前版本。
-
自动分区文件以帮助过滤 - 历史上,用户需要手工完成这个容易出错的任务,并在更新中维护它。
-
查询引擎可以使用的元数据提供高级计划和过滤。
这些表功能通常由manifest文件提供。这些manifest维护了与底层数据文件的历史记录,其中包含了它们的模式、分区和文件信息的完整描述。这种抽象允许支持不可变的快照,在跟踪表随时间变化的所有更改中有效地组织在一个分层结构中。
我们将这些文件格式的探索以及它们如何与ClickHouse一起使用推迟到后面的博客文章。敬请期待。
结论和未来工作
这篇博客文章详细探讨了Parquet格式,以及读取和写入文件时的重要ClickHouse设置和考虑因素。我们还突出了关于并行化的最新发展。我们继续发展并改进我们对Parquet的支持,计划的可能的改进包括但不限于:
-
利用任何WHERE子句中的条件的元数据可能会显著提高包含范围条件的查询的性能,例如日期过滤。这些元数据还可以用于改进特定的聚合函数,如计数。
-
在写Parquet文件时,我们目前不允许用户控制用于列的编码,而是使用合理的默认值。未来的改进将允许我们利用其他压缩技术,如Delta用于日期时间和数值的编码,或为特定列关闭字典编码。
-
Arrow API在写文件时提供了几个设置,包括限制字典大小的能力。我们欢迎用户提供哪些值得公开的想法。
-
并行化读取是一个持续的努力,有多种低级改进可能[1][2]。我们预期并行化编码对写性能有很大的影响。
-
我们对Parquet的支持正在不断改进。除了在这篇博客中突出的一些行为上的不一致性外,我们还计划其他的改进,如改进逻辑类型的支持[1]和确保Null列被正确识别[2]。
总体而言,理解和优化Parquet格式与ClickHouse的交互是确保最佳性能和效率的关键。随着技术的不断发展和改进,用户和开发人员应保持警觉,不断适应和探索新的方法来提高他们的数据处理和查询能力。
作者:Dale McDiarmid
更多内容请关注公号【云原生数据库】
squids.cn,云数据库RDS,迁移工具DBMotion,云备份DBTwin等数据库生态工具。
-
-
相关阅读:
css 设置border边框颜色渐变效果
关注我,我们一起彻底学会java
大数据之LibrA数据库系统服务部署原则及运行环境要求
2021年全球IB考试99人得满分,55考生来自新加坡
求二叉树的高度——函数递归的思想
Vue 之 vue-seamless-scroll 实现简单自动无缝滚动,且添加对应点击事件的简单整理
VM ware中Linux连网
Python-自动化绘制股票价格通道线
Vue 快速入门案例
模拟实现C语言--strcmp函数
- 原文地址:https://blog.csdn.net/weixin_48804451/article/details/133939206
