-
代码随想录算法训练营第二十八天 | LeetCode 491. 递增子序列、46. 全排列、47. 全排列 II
代码随想录算法训练营第二十八天 | LeetCode 491. 递增子序列、46. 全排列、47. 全排列 II
目录
代码随想录算法训练营第二十八天 | LeetCode 491. 递增子序列、46. 全排列、47. 全排列 II
1. LeetCode 491. 递增子序列
1.1 思路

- 这题和90. 子集 II很像,但是又有点不同,相同的是都是求子集并且是有重复元素的,并要求不能有重复组合,不同的是这题我们不可以给数组排序,因为要求的是自增子序列,自增就是要按照题目的顺序,并且元素个数是要>=2 的
- 而我们用回溯算法去求难免会有重复的元素,因此需要去重,而去重的逻辑又不能与40. 组合总和 II和90. 子集 II相同,因为不能排序。这题属于回溯算法和深搜都对,本质是差不多的,所有回溯都是深搜
- 与之前一样,还是树层去重,树枝上数值是可以取数值相同的元素的,树层上是不可以的。树枝上允许出现 [4,7,7] 这种情况,但树层上如果第二次取相同数值的元素其实在第一次取了之后往下递归的过程在树枝上已经取过第二个相同的元素了,因此要树层去重
- 这里收集结果的地方其实也是树上的节点,只是对结果里的元素数量有要求,要>=2 个,因此收集结果的地方依然是在回溯函数的首行,只是要加个条件,里面的元素要>=2
- 综上我们要去重的部分其实主要就是两部分,第一是这个树层上重复出现的元素,第二是该元素比子序列的最后一个元素小的情况
- 定义两个全局变量,result、path
- 回溯函数的参数和返回值:返回值 void,参数 nums,startIndex 控制剩余集合的起始位置
- 终止条件:startIndex>=nums.length
- 单层搜索的逻辑:进入递归就收集结果,因为每个节点都是我们的结果,但是本题需要判断一下,与元素个数要>=2,把 path 加入到 result 中
- 要先定义个 HashSet set,就是做树层去重的,我们怎么知道同层前面取过了某个元素接下来就不能取了呢?就用 set 记录一下,for(int i=startIndex;i
- 然后就是取数的过程,set.add(nums[i]),path.add(nums[i])。然后是递归 backtracking(nums, i+1),然后是回溯的过程 path.remove(path.size()-1)。这里为什么不需要把 set 也回溯呢?因为这个 set 只是记录同一层里是否取过某个数,而进入递归时是新创建一个 set,再重新记录同一层是否取过某个数,set 的作用就是记录当前这层递归的元素别取重复了
1.2 代码
- //
- class Solution {
- List
- List
path = new ArrayList<>(); - public List
- backTracking(nums, 0);
- return result;
- }
- private void backTracking(int[] nums, int startIndex){
- if(path.size() >= 2)
- result.add(new ArrayList<>(path));
- HashSet
hs = new HashSet<>(); - for(int i = startIndex; i < nums.length; i++){
- if(!path.isEmpty() && path.get(path.size() -1 ) > nums[i] || hs.contains(nums[i]))
- continue;
- hs.add(nums[i]);
- path.add(nums[i]);
- backTracking(nums, i + 1);
- path.remove(path.size() - 1);
- }
- }
- }
2. LeetCode 46. 全排列
2.1 思路

- 这题没有重复元素,因此不用考虑去重。这题是排列,需要清除与组合的区别。
- 这题需要用个 used 数组,之前都是用 used 来去重的,这里不需要去重为什么也用呢?这里是用 used 数组是标记哪个元素使用过了,我们求排列相同元素不能重复使用,和之前的去重逻辑是不一样的。做组合类问题时都是用 startIndex 来避免重复取同一个元素和出现 [1,2][2,1] 这种情况。
- 这题的结果都是在叶子节点上的,树的深度就是由集合的大小长度来控制的,因为最后取的排列就是和集合一样大的
- 定义三个全局变量,result、path、used 数组标记哪个元素已经使用过
- 回溯函数的参数和返回值:返回值 void,参数 nums
- 终止条件:当 nums.length==path.size()就把 path 加入到 result 中然后 return
- 单层搜索的逻辑:for(int i=0; i
2.2 代码
- //
- class Solution {
- List
- LinkedList
path = new LinkedList<>();// 用来存放符合条件结果 - boolean[] used;
- public List
- if (nums.length == 0){
- return result;
- }
- used = new boolean[nums.length];
- permuteHelper(nums);
- return result;
- }
- private void permuteHelper(int[] nums){
- if (path.size() == nums.length){
- result.add(new ArrayList<>(path));
- return;
- }
- for (int i = 0; i < nums.length; i++){
- if (used[i]){
- continue;
- }
- used[i] = true;
- path.add(nums[i]);
- permuteHelper(nums);
- path.removeLast();
- used[i] = false;
- }
- }
- }
3. LeetCode 47. 全排列 II
3.1 思路
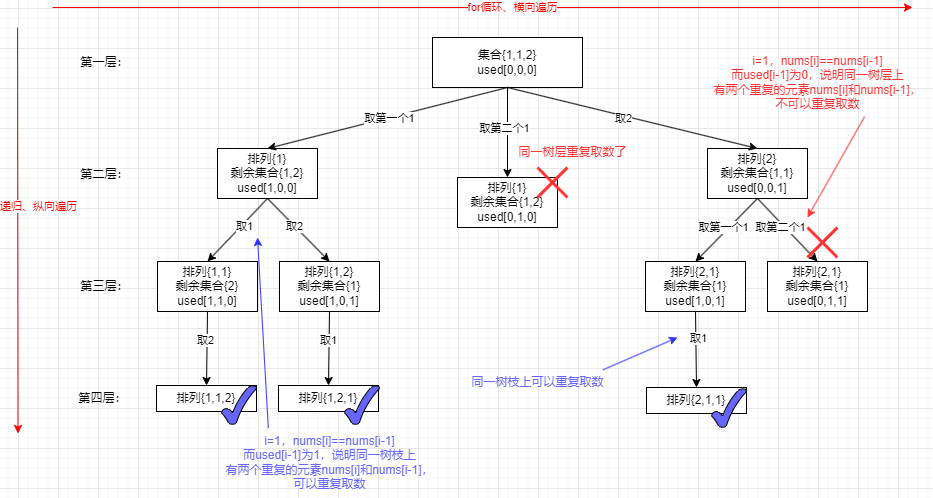
- 这题和46. 全排列的区别就是这题有重复元素,这样就会导致出现相同的排列不如两个{1,1,2},因此要去重(注意这里去重需要先对题目的数组排序,因为要让相同的元素挨在一起)。同时这里也需要 used 数组标记哪些元素是否使用过,避免出现了使用两次同一个元素
- 依然是从树层去重和树枝去重的角度看。同一树层上,前面取过 1 后面就不能取 1 了,因为剩余集合是相同的,再取一次就会得到相同的排列,就重复了。而在同一树枝上上面取过 1 了,下面还可以取 1,这里没有重复取 1,上面取的是第一个 1 下面取的是第二个 1,这里是两个元素,排列里可以出现比如{1,1,2}这样子可以出现两个数值相同的元素。而结果是在叶子节点上,我们要砍去的分支都是在树层上如果和前面的树枝相同就要砍掉
- 定义三个全局变量,result、path、used 数组标记哪个元素已经使用过
- 回溯参数的参数和返回值:返回值 void,参数 nums
- 终止条件:当 path.size()==nums.length 就把 path 加入到 result 中然后 return
- 单层搜索的逻辑:for(int i=0; i
- 然后是挨个取数的逻辑,取数时 if(used[i]==true)就 continue,这个情况就是排列里不能取同一个数的逻辑。然后就继续取数,used[i]=true,path.add(nums[i]),然后递归函数,然后回溯 used[i]=false,path.removeLast()
3.2 代码
- //
- class Solution {
- //存放结果
- List
- //暂存结果
- List
path = new ArrayList<>(); - public List
- boolean[] used = new boolean[nums.length];
- Arrays.fill(used, false);
- Arrays.sort(nums);
- backTrack(nums, used);
- return result;
- }
- private void backTrack(int[] nums, boolean[] used) {
- if (path.size() == nums.length) {
- result.add(new ArrayList<>(path));
- return;
- }
- for (int i = 0; i < nums.length; i++) {
- // used[i - 1] == true,说明同⼀树⽀nums[i - 1]使⽤过
- // used[i - 1] == false,说明同⼀树层nums[i - 1]使⽤过
- // 如果同⼀树层nums[i - 1]使⽤过则直接跳过
- if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {
- continue;
- }
- //如果同⼀树⽀nums[i]没使⽤过开始处理
- if (used[i] == false) {
- used[i] = true;//标记同⼀树⽀nums[i]使⽤过,防止同一树枝重复使用
- path.add(nums[i]);
- backTrack(nums, used);
- path.remove(path.size() - 1);//回溯,说明同⼀树层nums[i]使⽤过,防止下一树层重复
- used[i] = false;//回溯
- }
- }
- }
- }
-
相关阅读:
var、let、const的区别
synchronized对象锁?如何用synchronized锁字符串对象,这里面的坑要注意
Vulntarget-a靶场实战记录
【数据结构与算法】二叉树的基本概念
Pytorch 分布式训练中DP和DDP的原理和用法
DataX(MySQL同步数据到Doris)
Jackson ImmunoResearch通过 SDS-PAGE 进行蛋白质分离
IP地址在各行业中的应用场景
js时间转化为几天前,几小时前,几分钟前
C++ Tutorials: C++ Language: Classes: Polymorphism
- 原文地址:https://blog.csdn.net/Hsusan/article/details/133952641
