-
嵌入式面试常见问题(二)
1.malloc如何分配内存?
进行虚拟地址空间的分布:程序地址空间-》程序虚拟地址空间-》进程虚拟地址空间
内存布局:
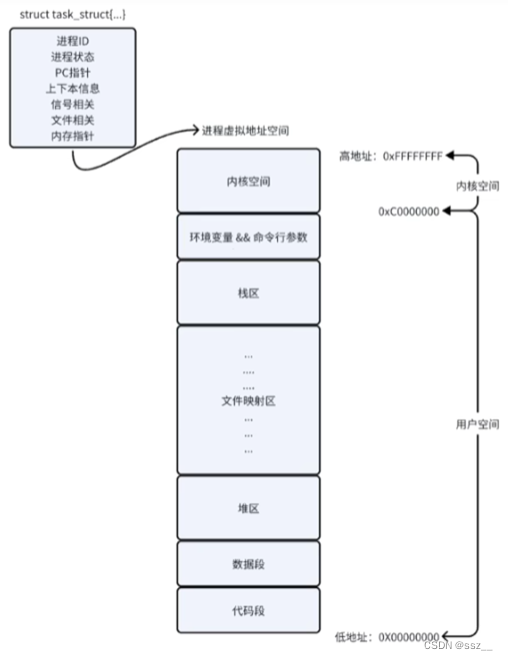
进程虚拟地址空间和PCB(Process Control Block,进程控制块)进行串联 :

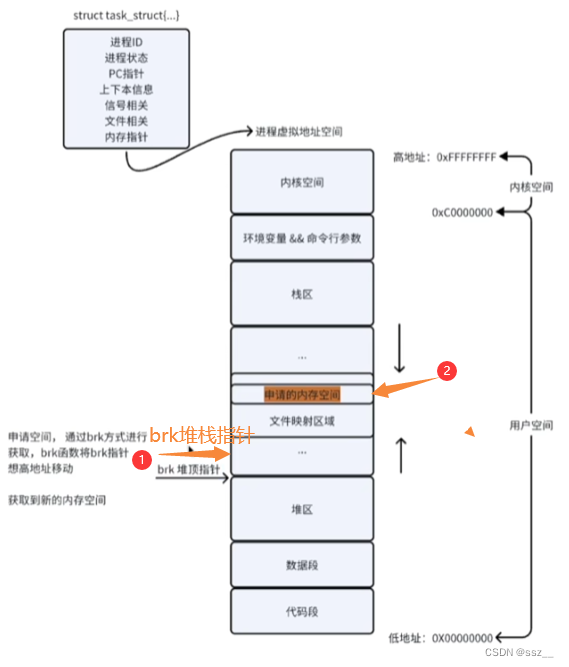
分配内存方式:
第一种:通过brk()系统调用从堆分配内存
第二种:通过mmap()系统调用在文件映射区分配内存
两种方式如何区分?
1.如果用户分配的内存小于128KB,则通过brk()申请内存;
2.如果用户分配的内存大于128KB,则通过mmap()申请内存;
3.不同的glibc当中定义的阈值是不一样的,但基本就是上面两种。
- #include
- void *malloc(size_t size);
使用该函数需要包含头文件
。
函数参数和返回值含义如下:
size:需要分配的内存大小,以字节为单位。返回值:返回值为void *类型,如果申请分配内存成功,将返回一个指向该段内存的指针,void *并不是说没有返回值或者返回空指针,而是返回的指针类型未知,所以在调用malloc()时通常需要进行强制类型转换,将void *指针类型转换成我们希望的类型;如果分配内存失败(譬如系统堆内存不足)将返回NULL,如果参数size为0,返回值也是NULL。
malloc()在堆区分配一块指定大小的内存空间,用来存放数据。这块内存空间在函数执行完成后不会被初始化,它们的值是未知的,所以通常需要程序员对malloc()分配的堆内存进行初始化操作。- #include
- void free(void *ptr);
使用该函数同样需要包含头文件
。
函数参数和返回值含义如下:
ptr:指向需要被释放的堆内存对应的指针。
返回值:无返回值。示例代码:
- #include
- #include
- #include
- #define MALLOC_MEM_SIZE (1 * 1024 * 1024)
- int main(int argc, char *argv[])
- {
- char *base = NULL;
- //申请堆内存
- base = (char *)malloc(MALLOC_MEM_SIZE);
- if(NULL == base)
- {
- printf("malloc error\n");
- exit(-1);
- }
- //初始化申请到的堆内存
- memset(base, 0x0, MALLOC_MEM_SIZE);
- //使用内存
- /*---------*/
- //释放内存
- free(base);
- return 0;
- }
2.readelf和objdump区别
readelf和objdump都是用于分析可执行文件、共享库和目标文件的工具,但它们在显示的信息和使用方式上有一些区别。-
readelf:readelf是一个用于查看和分析可执行文件、共享库和目标文件的工具。- 它主要用于显示文件的结构信息,如节表、符号表、重定位表、动态链接信息等。
readelf提供了丰富的选项来显示不同类型的信息,如-s用于显示符号表,-S用于显示节表,-r用于显示重定位表等。- 它以一种较为详细的格式显示文件的信息,适合用于查看文件的结构和元数据。
-
objdump:objdump是一个用于反汇编可执行文件、共享库和目标文件的工具。- 它可以显示文件的汇编代码,包括指令、符号、调试信息等。
objdump可以用于查看文件的汇编指令,以及对应的源代码(如果调试信息可用)。- 它提供了多种选项来控制显示的内容和格式,如
-d用于显示反汇编代码,-t用于显示符号表,-S用于显示源代码等。 objdump更适合用于分析代码的执行流程、查看函数的汇编实现等。
总结:
readelf主要用于显示文件的结构信息,如节表、符号表、重定位表等,适合用于查看文件的结构和元数据。objdump主要用于反汇编文件,显示汇编代码、符号、调试信息等,适合用于分析代码的执行流程和查看函数的汇编实现。
3.如何验证一个函数是否inline?
通过对可执行文件进行反汇编,查看汇编代码函数是否被展开。示例:
一般来讲,判断对一个内联函数是否做展开,从程序员的角度出发,主要考虑如下因素。
● 函数体积小。
● 函数体内无指针赋值、递归、循环等语句。
● 调用频繁。
当我们认为一个函数体积小,而且被大量频繁调用,应该做内联展开时,就可以使用static inline关键字修饰它。但编译器不一定会做内联展开,如果你想明确告诉编译器一定要展开,或者不展开,就可以使用noinline或always_inline对函数做一个属性声明。- #include
- static inline __attribute__((always_inline)) int func(int a)
- {
- return a + 1;
- }
- static inline void print_num(int a)
- {
- printf("%d\n",a);
- }
- int main(void)
- {
- int i;
- i = func(3);
- print_num(10);
- return 0;
- }
在这个程序中,我们分别定义两个内联函数:func()和print_num(),然后使用always_inline对func()函数进行属性声明。编译这个源文件,并对生成的可执行文件a.out做反汇编处理,其汇编代码如下。

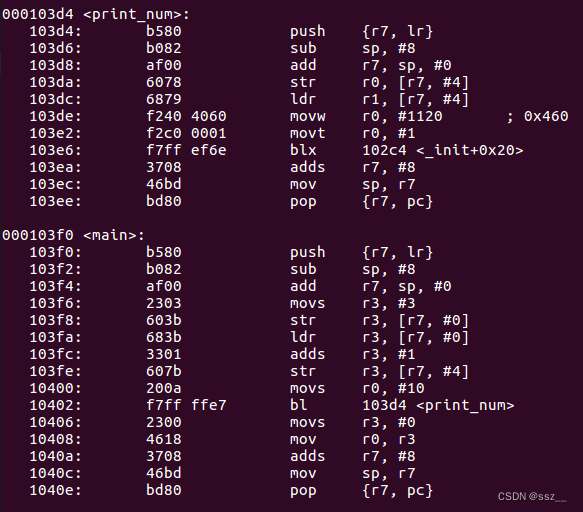
通过反汇编代码可以看到,因为我们对func()函数作了always_inline属性声明,所以在编译过程中,在调用func()函数的地方,编译器会将func()函数在调用处直接展开。

而对于print_num()函数,虽然我们对其做了内联声明,但编译器并没有对其做内联展开,而是把它当作一个普通函数对待。还有一个需要注意的细节是:当编译器对内联函数做展开处理时,会直接在调用处展开内联函数的代码,不再给func()函数本身生成单独的汇编代码。因为编译器在所有调用该函数的地方都做了内联展开,没必要再去生成单独的函数汇编指令。在这个例子中,我们发现编译器就没有给func()函数本身生成单独的汇编代码,编译器只给print_num()函数生成了独立的汇编代码。
内联函数为什么定义在头文件中?
因为它是一个内联函数,可以像宏一样使用,任何想使用这个内联函数的源文件,都不必亲自再去定义一遍,直接包含这个头文件,即可像宏一样使用。
内联函数为什么用static修饰?
因为我们使用inline定义的内联函数,编译器不一定会内联展开,那么当一个工程中多个文件都包含这个内联函数的定义时,编译时就有可能报重定义错误。而使用static关键字修饰,则可以将这个函数的作用域限制在各自的文件内,避免重定义错误的发生。
4.函数的参数传递方式
-
值传递(Pass by Value):这是最常见的参数传递方式。在这种方式中,函数接收的是实参的一个副本。因此,函数内部对参数的修改不会影响到实参。
-
引用传递(Pass by Reference):在这种方式中,函数接收的是实参的引用,也就是说,函数内部对参数的修改会直接影响到实参。这种方式在C++中常见,但C语言不支持。
-
指针传递(Pass by Pointer):这种方式类似于引用传递,但是使用的是指针。函数接收的是指向实参的指针,因此,函数内部对指针所指向的值的修改会影响到实参。这是C语言中实现"引用传递"的一种方式。
5.
C语言和C++定义结构体变量的区别在C中定义一个结构体类型要用typedef,如下:
- typedef struct Complex {
- int real;
- int image;
- }Complex;
那么,在说明Complex变量的时候可以这样写 Complex complex; 但是如果没有typedef就必须用 struct Complex complex; 来声明。这里的Complex实际上就是struct Complex的别名
但在c++里很简单,直接
- struct Complex {
- int real;
- int image;
- };
于是就定义了结构体类型Complex,声明变量时直接Complex complex
-
相关阅读:
状态估计|基于 MMSE 的分析估计器的不确定电力系统分析(Matlab代码实现)
Python之numpy数组篇(上)
TensorRT开发环境搭建
加密货币交易所偿付能力的零知识证明
唯品会常用的两个API接口:关键字搜索API、获取商品详情数据API
金融信创与云化转型|保险超融合架构转型与场景探索合集
微信小程序slot插槽的介绍,以及如何通过uniapp使用动态插槽
MySQL数据库之表的约束
说说对Fiber架构的理解?解决了什么问题?
Spring 从入门到精通 (二十) 持久层框架 MyBatis
- 原文地址:https://blog.csdn.net/ssz__/article/details/133798461
