-
CUDA学习笔记5——CUDA程序错误检测
CUDA程序错误检测
所有CUDA的API函数都有一个类型为cudaError_t的返回值,代表了一种错误信息;只有返回cudaSuccess时,才是成功调用。
- cudaGetLastError()用来检测核函数的执行是否出错
- cudaGetErrorString()输出错误信息
#include#include "cuda_runtime.h" #include "device_launch_parameters.h" #include #include #include #include #define BLOCK_SIZE 1 //图像卷积 GPU __global__ void sobel_gpu(unsigned char* in, unsigned char* out, const int Height, const int Width) { int x = blockDim.x * blockIdx.x + threadIdx.x; int y = blockDim.y + blockIdx.y + threadIdx.y; int index = y * Width + x; int Gx = 0; int Gy = 0; unsigned char x0, x1, x2, x3, x4, x5, x6, x7, x8; if (x>0 && x<(Width-1) && y>0 && y<(Height-1)) { x0 = in[(y - 1)*Width + (x - 1)]; x1 = in[(y - 1)*Width + (x)]; x2 = in[(y - 1)*Width + (x + 1)]; x3 = in[(y)*Width + (x - 1)]; x5 = in[(y)*Width + (x + 1)]; x6 = in[(y + 1)*Width + (x - 1)]; x7 = in[(y + 1)*Width + (x)]; x8 = in[(y + 1)*Width + (x + 1)]; Gx = (x0 + 2 * x3 + x6) - (x2 + 2 * x5 + x8); Gy = (x0 + 2 * x1 + x2) - (x6 + 2 * x7 + x8); out[index] = (abs(Gx) + abs(Gy)) / 2; } } int main() { cv::Mat src; src = cv::imread("complete004.jpg"); cv::Mat grayImg,gaussImg; cv::cvtColor(src, grayImg, cv::COLOR_BGR2GRAY); cv::GaussianBlur(grayImg, gaussImg, cv::Size(3,3), 0, 0, cv::BORDER_DEFAULT); int height = src.rows; int width = src.cols; //输出图像 cv::Mat dst_gpu(height, width, CV_8UC1, cv::Scalar(0)); //GPU存储空间 int memsize = height * width * sizeof(unsigned char); //输入 输出 unsigned char* in_gpu; unsigned char* out_gpu; cudaMalloc((void**)&in_gpu, memsize); cudaMalloc((void**)&out_gpu, memsize); cudaError_t error_code; dim3 threadsPreBlock(BLOCK_SIZE, BLOCK_SIZE); dim3 blocksPreGrid((width + threadsPreBlock.x - 1)/threadsPreBlock.x, (height + threadsPreBlock.y - 1)/threadsPreBlock.y); cudaMemcpy(in_gpu, gaussImg.data, memsize, cudaMemcpyHostToDevice); sobel_gpu <<<blocksPreGrid, threadsPreBlock>>> (in_gpu, out_gpu, height, width); error_code = cudaGetLastError(); printf("Error: %s\n", cudaGetErrorString(error_code)); printf("FILE: %s\n", __FILE__); printf("LINE: %d\n", __LINE__); printf("Error code: %d\n", error_code); cudaMemcpy(dst_gpu.data, out_gpu, memsize, cudaMemcpyDeviceToHost); cv::imwrite("dst_gpu_save.png", dst_gpu); //cv::namedWindow("src", cv::WINDOW_NORMAL); cv::imshow("src", src); cv::imshow("dst_gpu", dst_gpu); cv::waitKey(); cudaFree(in_gpu); cudaFree(out_gpu); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
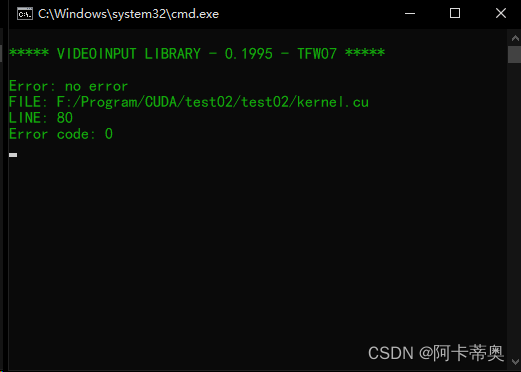

樊哲勇大牛的检测CUDA运行时错误的宏函数:
#pragma once #include#define CHECK(call) \ do \ { \ const cudaError_t error_code = call; \ if (error_code != cudaSuccess) \ { \ printf("CUDA Error:\n"); \ printf(" File: %s\n", __FILE__); \ printf(" Line: %d\n",__LINE__); \ printf(" Error code: %d\n",error_code); \ printf(" Error text: %s\n", cudaGetErrorString(error_code)); \ exit(1); \ } \ } while (0) - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
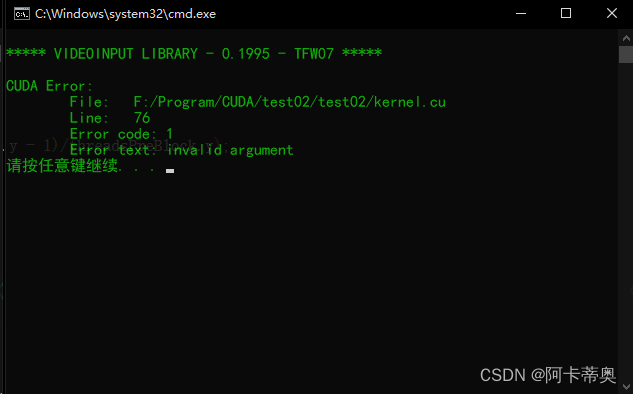
采用检测CUDA运行时错误的宏函数,图像卷积:
#include#include "cuda_runtime.h" #include "device_launch_parameters.h" #include #include #include #include #include "error.cuh" #define BLOCK_SIZE 1 //图像卷积 GPU __global__ void sobel_gpu(unsigned char* in, unsigned char* out, const int Height, const int Width) { int x = blockDim.x * blockIdx.x + threadIdx.x; int y = blockDim.y + blockIdx.y + threadIdx.y; int index = y * Width + x; int Gx = 0; int Gy = 0; unsigned char x0, x1, x2, x3, x4, x5, x6, x7, x8; if (x>0 && x<(Width-1) && y>0 && y<(Height-1)) { x0 = in[(y - 1)*Width + (x - 1)]; x1 = in[(y - 1)*Width + (x)]; x2 = in[(y - 1)*Width + (x + 1)]; x3 = in[(y)*Width + (x - 1)]; x5 = in[(y)*Width + (x + 1)]; x6 = in[(y + 1)*Width + (x - 1)]; x7 = in[(y + 1)*Width + (x)]; x8 = in[(y + 1)*Width + (x + 1)]; Gx = (x0 + 2 * x3 + x6) - (x2 + 2 * x5 + x8); Gy = (x0 + 2 * x1 + x2) - (x6 + 2 * x7 + x8); out[index] = (abs(Gx) + abs(Gy)) / 2; } } int main() { cv::Mat src; src = cv::imread("complete004.jpg"); cv::Mat grayImg,gaussImg; cv::cvtColor(src, grayImg, cv::COLOR_BGR2GRAY); cv::GaussianBlur(grayImg, gaussImg, cv::Size(3,3), 0, 0, cv::BORDER_DEFAULT); int height = src.rows; int width = src.cols; //输出图像 cv::Mat dst_gpu(height, width, CV_8UC1, cv::Scalar(0)); //GPU存储空间 int memsize = height * width * sizeof(unsigned char); //输入 输出 unsigned char* in_gpu; unsigned char* out_gpu; cudaMalloc((void**)&in_gpu, memsize); cudaMalloc((void**)&out_gpu, memsize); dim3 threadsPreBlock(BLOCK_SIZE, BLOCK_SIZE); dim3 blocksPreGrid((width + threadsPreBlock.x - 1)/threadsPreBlock.x, (height + threadsPreBlock.y - 1)/threadsPreBlock.y); cudaMemcpy(in_gpu, gaussImg.data, memsize, cudaMemcpyHostToDevice); sobel_gpu <<<blocksPreGrid, threadsPreBlock>>> (in_gpu, out_gpu, height, width); CHECK(cudaMemcpy(dst_gpu.data, out_gpu, memsize*10, cudaMemcpyDeviceToHost));//增大size值 引起报错 cv::imwrite("dst_gpu_save.png", dst_gpu); //cv::namedWindow("src", cv::WINDOW_NORMAL); cv::imshow("src", src); cv::imshow("dst_gpu", dst_gpu); cv::waitKey(); cudaFree(in_gpu); cudaFree(out_gpu); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
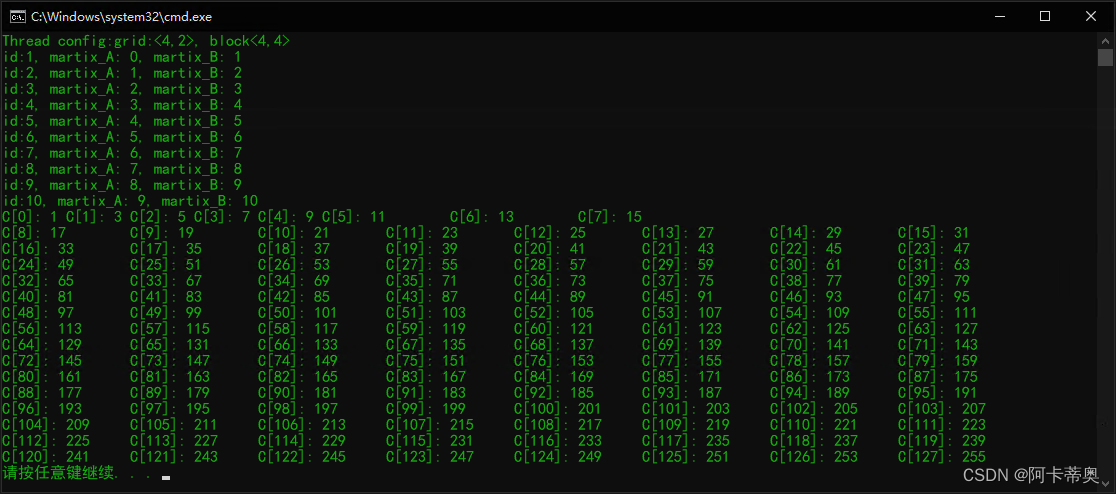
采用检测CUDA运行时错误的宏函数,矩阵相加:
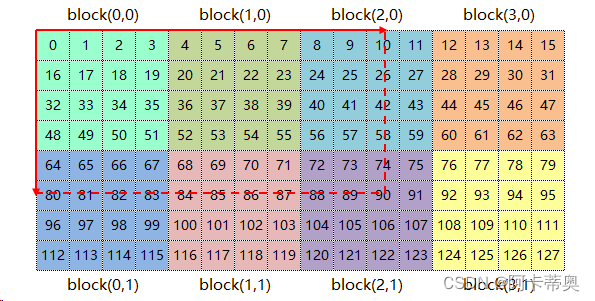
二维网络和二维线程块对二维矩阵进行索引,每个线程可负责一个矩阵元素的计算任务;
ix=threadIdx.x+blockIdx.xblockDim.x
iy=threadIdx.y+blockIdx.yblockDim.y
#include#include "cuda_runtime.h" #include "device_launch_parameters.h" #include "error.cuh" #include #include __global__ void addMatrix(int *input_1, int *input_2, int *output, const int nx, const int ny) { int ix = threadIdx.x + blockIdx.x * blockDim.x; int iy = threadIdx.y + blockIdx.y * blockDim.y; unsigned int idx = iy * nx + ix; if (ix < nx && iy < ny) { output[idx] = input_1[idx] + input_2[idx]; } } int main(void) { int nx = 16; int ny = 8; int nxy = nx * ny; size_t stBytesCount = nxy * sizeof(int); int *ipHost_A, *ipHost_B, *ipHost_C; ipHost_A = (int *)malloc(stBytesCount); ipHost_B = (int *)malloc(stBytesCount); ipHost_C = (int *)malloc(stBytesCount); if (ipHost_A != NULL && ipHost_B != NULL && ipHost_C != NULL) { for (int i = 0; i < nxy; i++) { ipHost_A[i] = i; ipHost_B[i] = i + 1; } memset(ipHost_C, 0, stBytesCount); } else { printf("Fail to allocate host memory! \n"); } // 分配内存 初始化 int *ipDevice_A, *ipDevice_B, *ipDevice_C; CHECK(cudaMalloc((int**)&ipDevice_A, stBytesCount)); CHECK(cudaMalloc((int**)&ipDevice_B, stBytesCount)); CHECK(cudaMalloc((int**)&ipDevice_C, stBytesCount)); if (ipDevice_A != NULL && ipDevice_B != NULL && ipDevice_C != NULL) { CHECK(cudaMemcpy(ipDevice_A, ipHost_A, stBytesCount, cudaMemcpyHostToDevice)); CHECK(cudaMemcpy(ipDevice_B, ipHost_B, stBytesCount, cudaMemcpyHostToDevice)); CHECK(cudaMemcpy(ipDevice_C, ipHost_C, stBytesCount, cudaMemcpyHostToDevice)); } else { printf("Fail to allocate memory \n"); free(ipHost_A); free(ipHost_B); free(ipHost_C); exit(1); } // dim3 block(4,4);//线程块大小 4*4 dim3 grid((nx + block.x-1)/block.x, (ny+block.y - 1)/block.y); printf("Thread config:grid:<%d,%d>, block<%d,%d>\n", grid.x, grid.y, block.x, block.y); // 调用核函数 addMatrix <<< grid, block>>> (ipDevice_A, ipDevice_B, ipDevice_C, nx, ny); //拷贝出结果 CHECK(cudaMemcpy(ipHost_C, ipDevice_C, stBytesCount,cudaMemcpyDeviceToHost)); for (int i = 0; i < 10; i++) { printf("id:%d, martix_A: %d, martix_B: %d \n", i+1, ipHost_A[i], ipHost_B[i], ipHost_C[i]); } if (ipHost_C != NULL) { for (int i = 0; i < nxy; i++) { printf("C[%d]: %d ", i, ipHost_C[i]); if ((i+1)%16 == 0) { printf("\n"); } } } //释放主机内存 free(ipHost_A); free(ipHost_B); free(ipHost_C); CHECK(cudaFree(ipDevice_A)); CHECK(cudaFree(ipDevice_B)); CHECK(cudaFree(ipDevice_C)); CHECK(cudaDeviceReset());//清空申请的当前关联gpu设备资源 return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
-
相关阅读:
搞定了 6 种分布式ID,分库分表哪个适合做主键?
树莓派4b装系统到运行 Blazor Linux 本地程序全记录
tornado模板注入
LeetCode刷题复盘笔记—一文搞懂完全背包之279. 完全平方数问题(动态规划系列第十五篇)
JDBC学习笔记
组态软件和人机界面与plc之间Profinet无线通讯
MySQL数据库优化的几种方式(笔面试必问)
react事件系统(新版本)
从零学算法(剑指 Offer 61)
翻译工具-翻译工具下载批量自动一键翻译免费
- 原文地址:https://blog.csdn.net/akadiao/article/details/133907441
