-
04、MySQL-------MyCat实现分库分表
九、MyCat实现分库分表
1、分库分表介绍:
https://www.cnblogs.com/zhangyi555/p/16528576.html
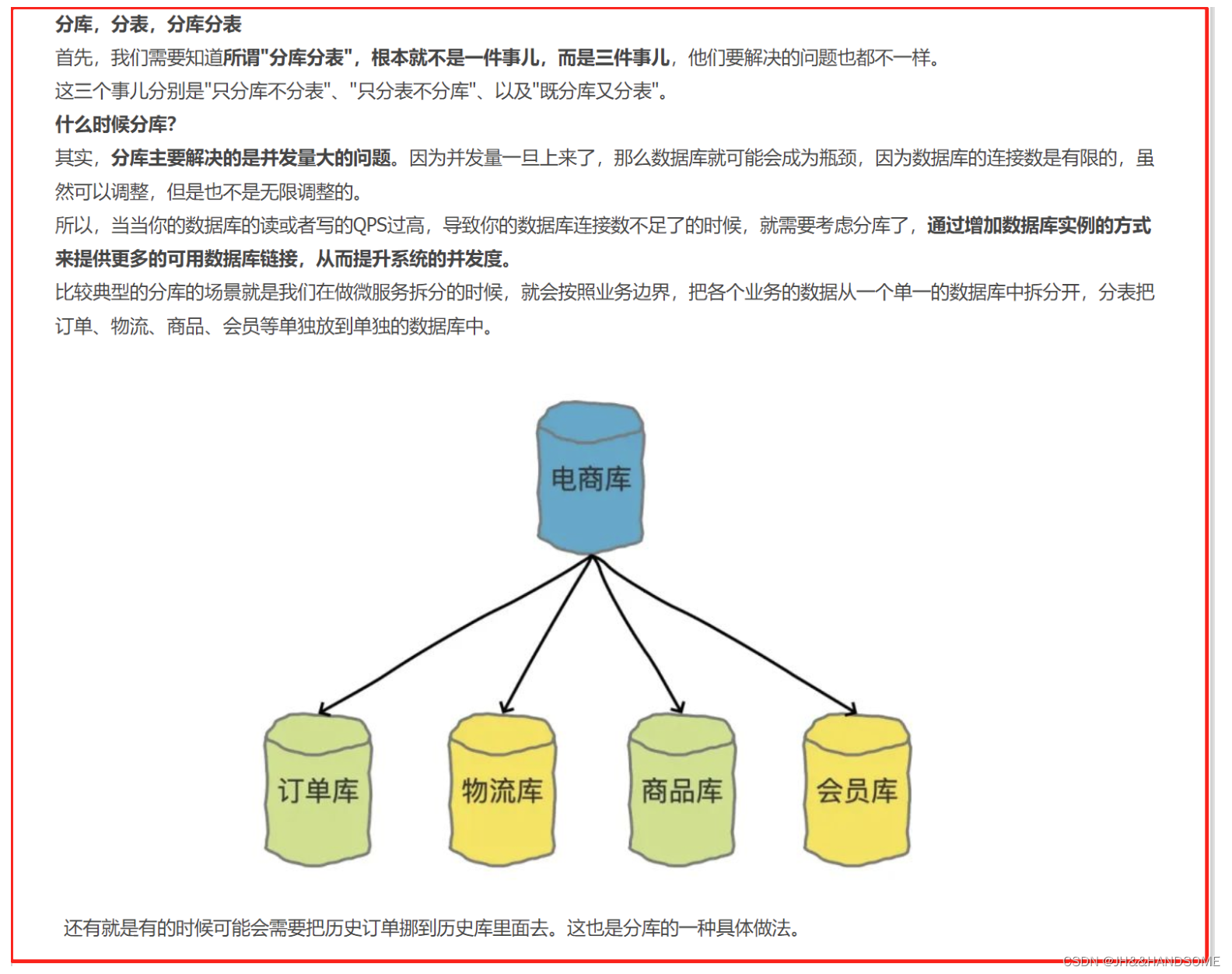
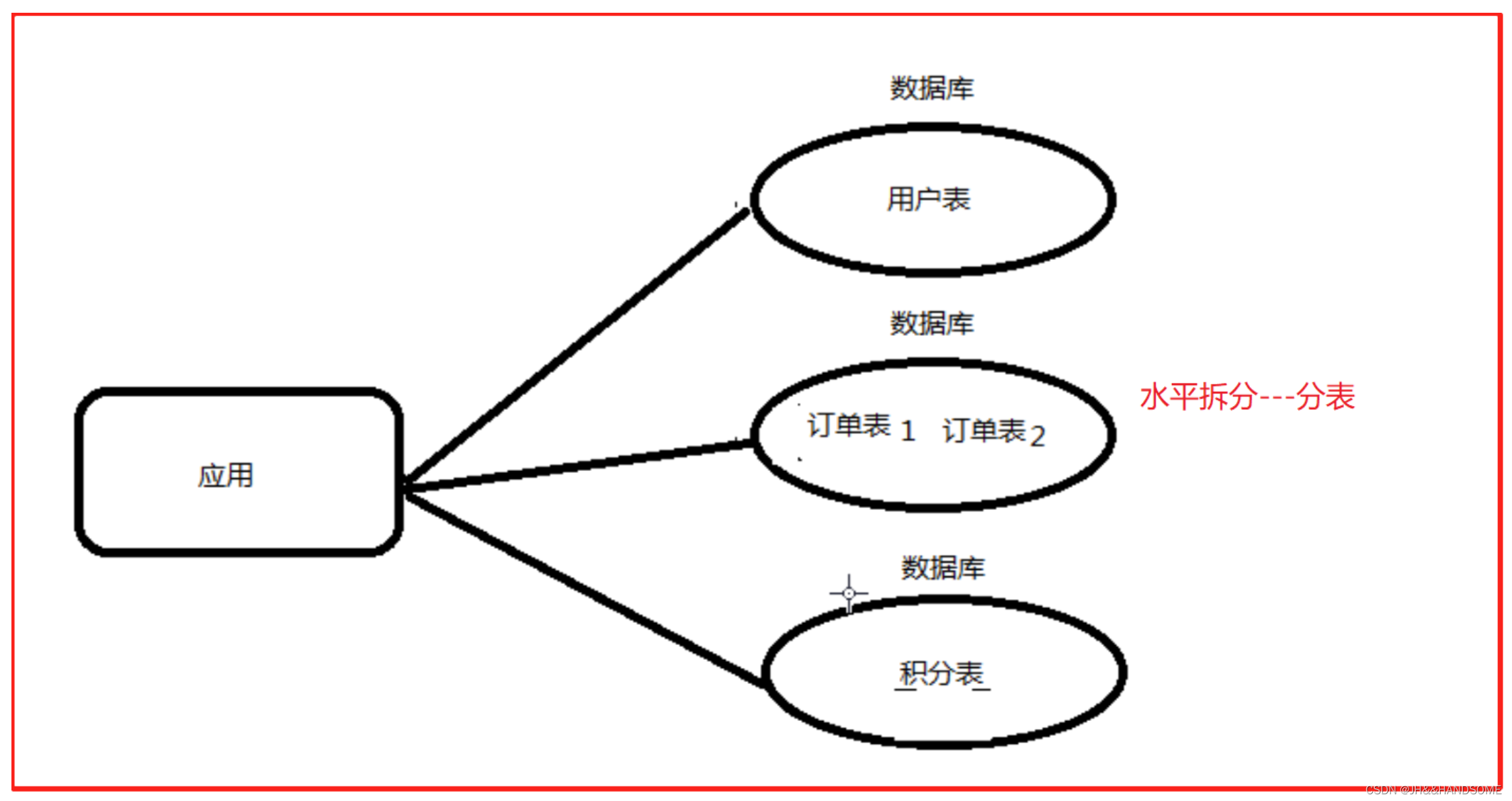
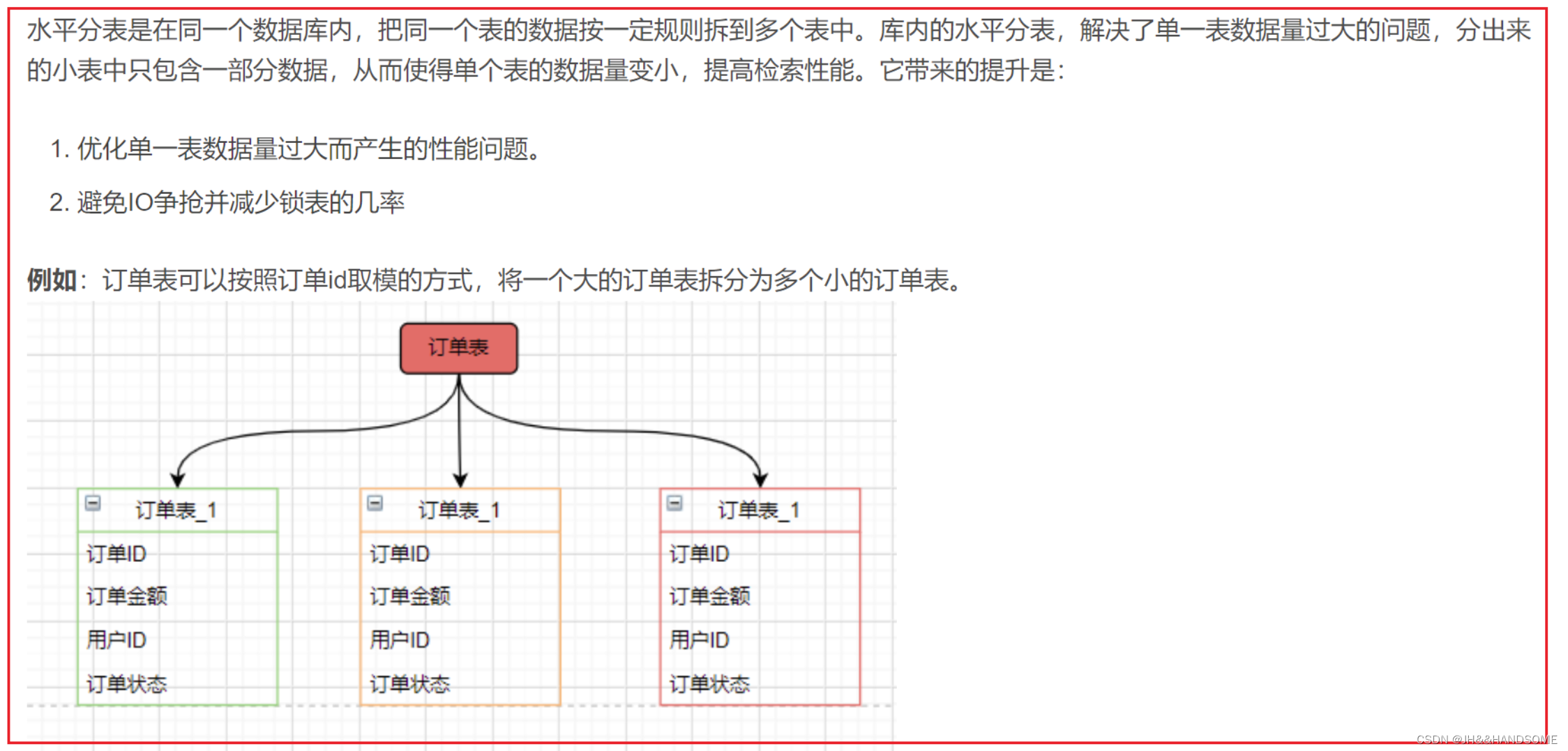
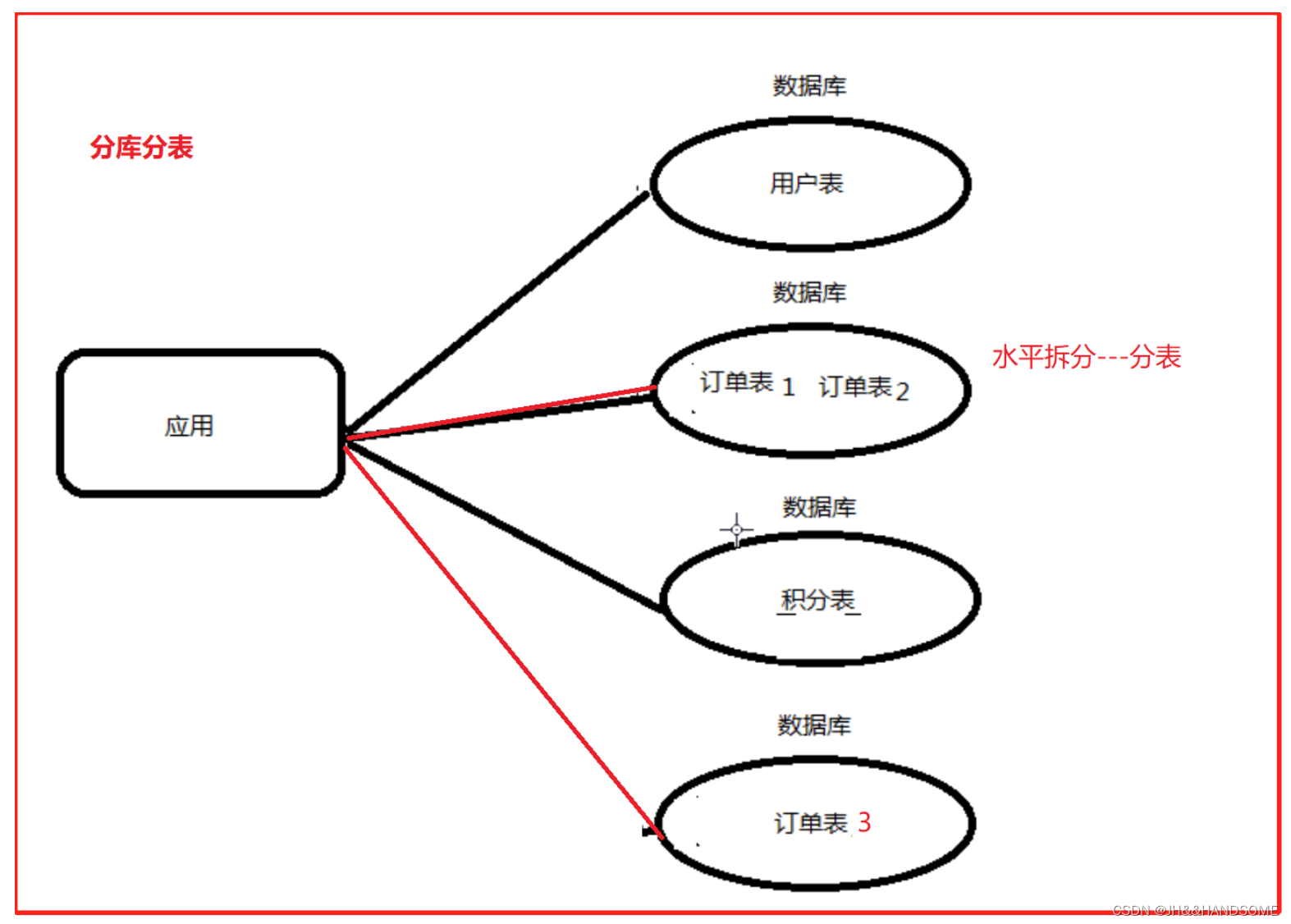
横向(水平)拆分
那如果把一张表中的不同的记录分别放到不同的表中,这种就是横向拆分。
横向拆分的结果是数据库表中的数据会分散到多张分表中,使得每一个单表中的数据的条数都有所下降。比如我们可以把不同的用户的订单分表拆分放到不同的表中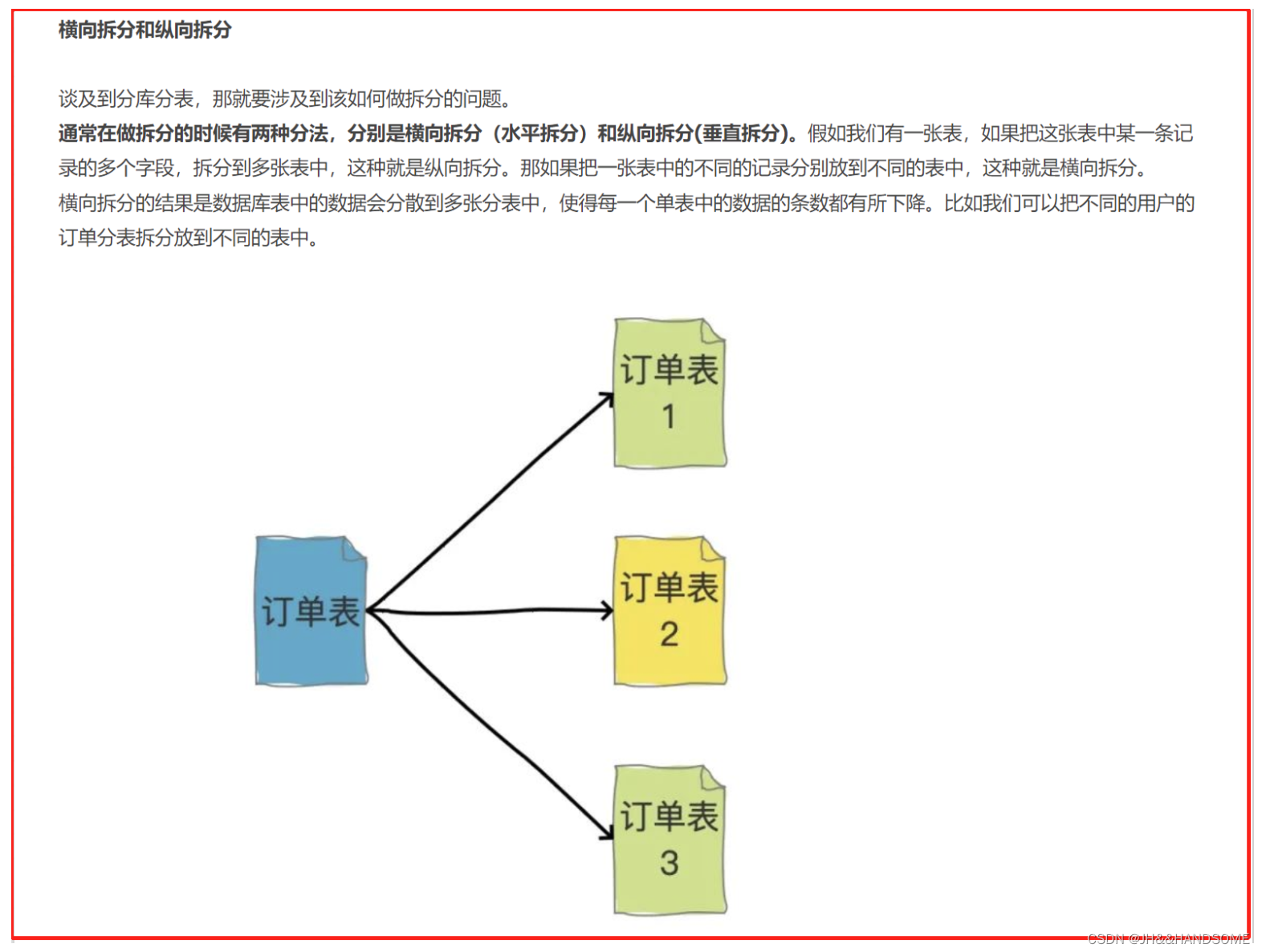
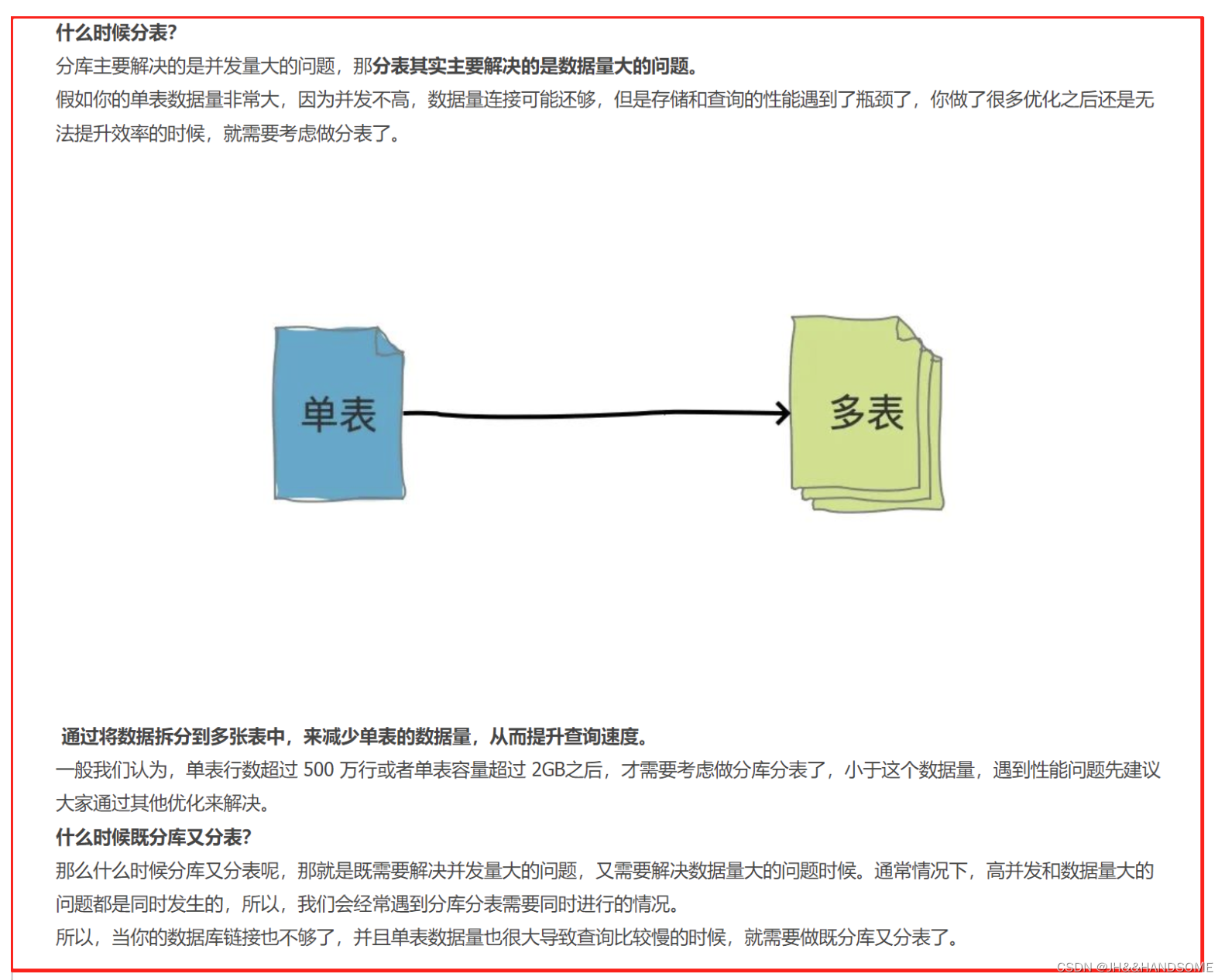
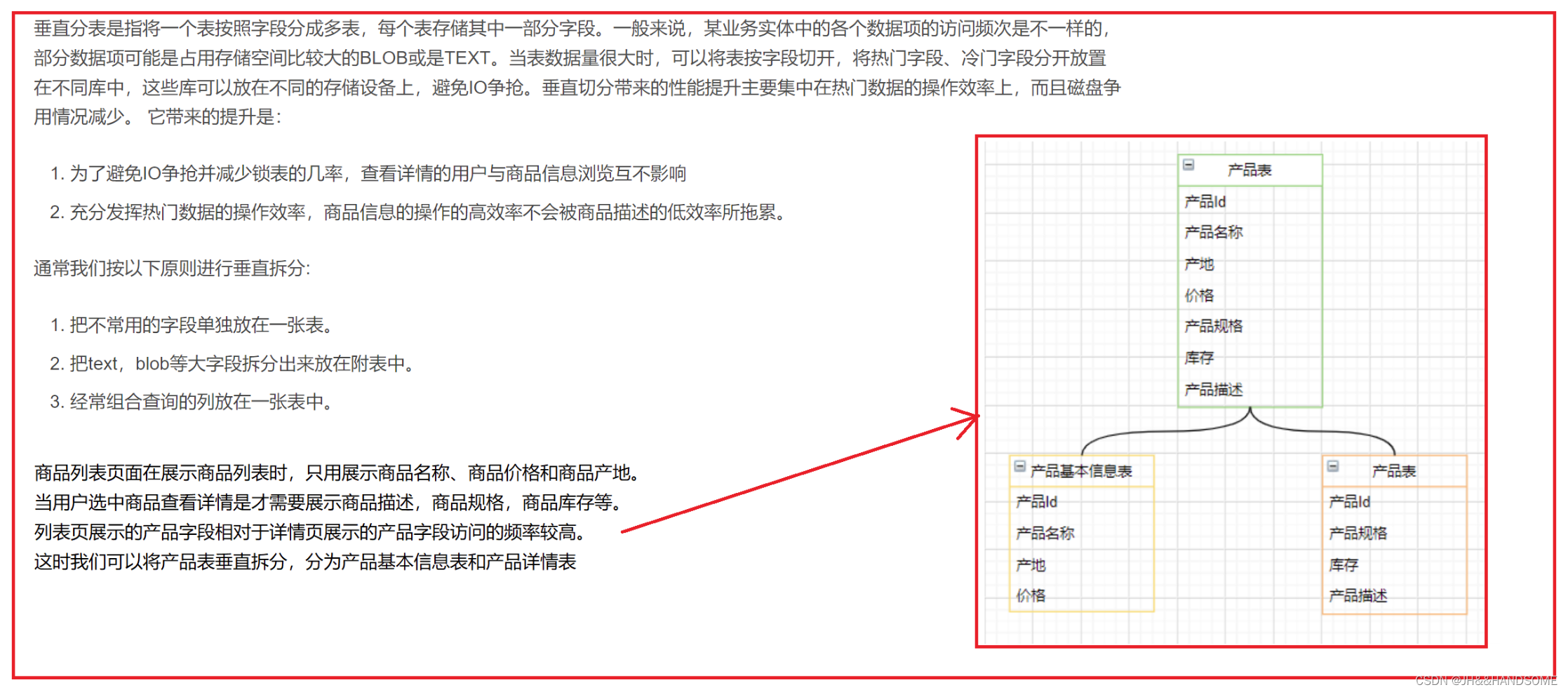
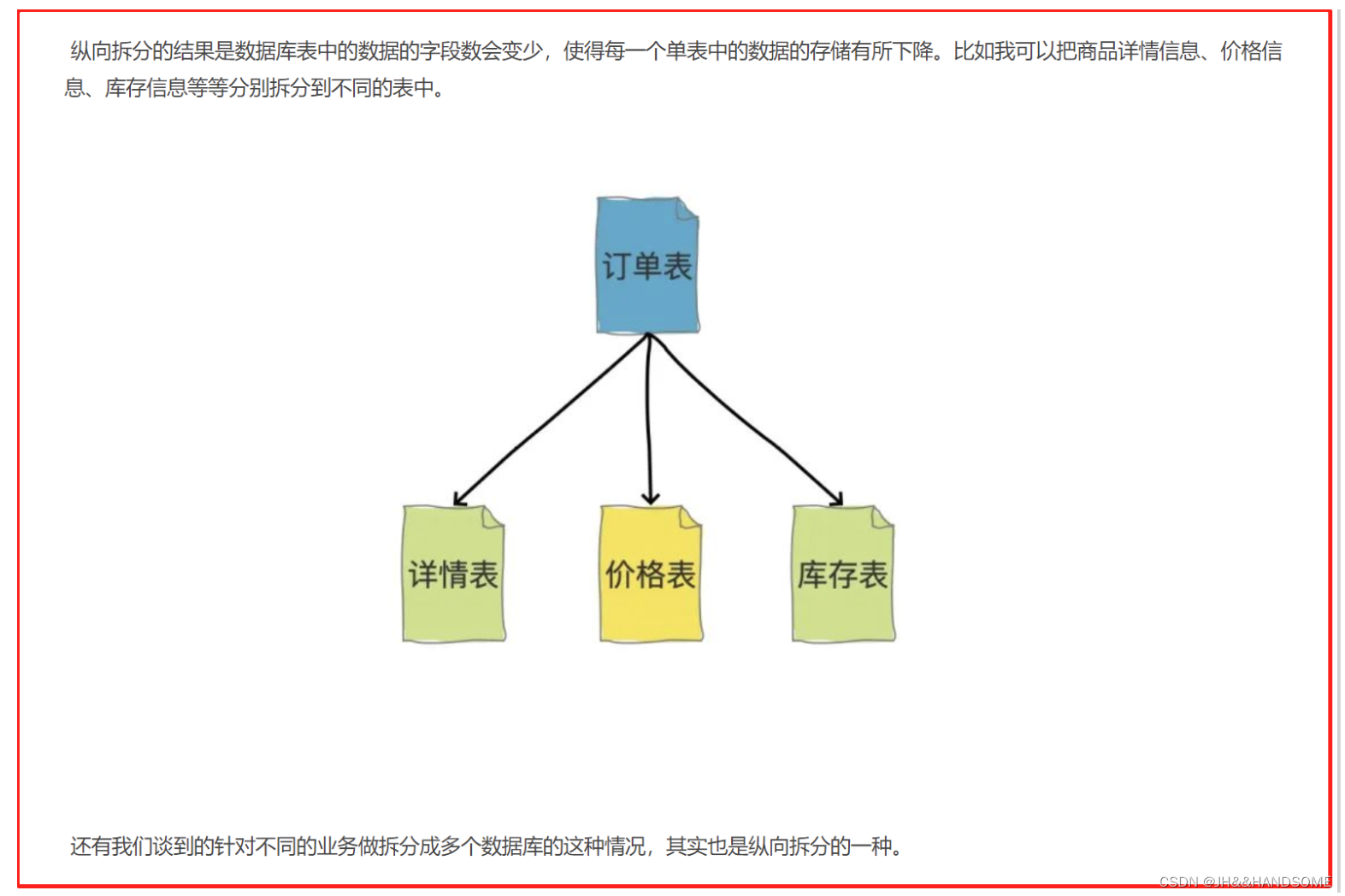
垂直分表:
垂直分表是指将一个表按照字段分成多表,每个表存储其中一部分字段
一张表有10个字段,分成A、B两张表,A表放3个字段,B表放7个字段。

水平分表:
把10万条数据的表,分成两个5万数据的表,就是水平分表,字段都是一样的

分库分表
纵向(垂直)拆分
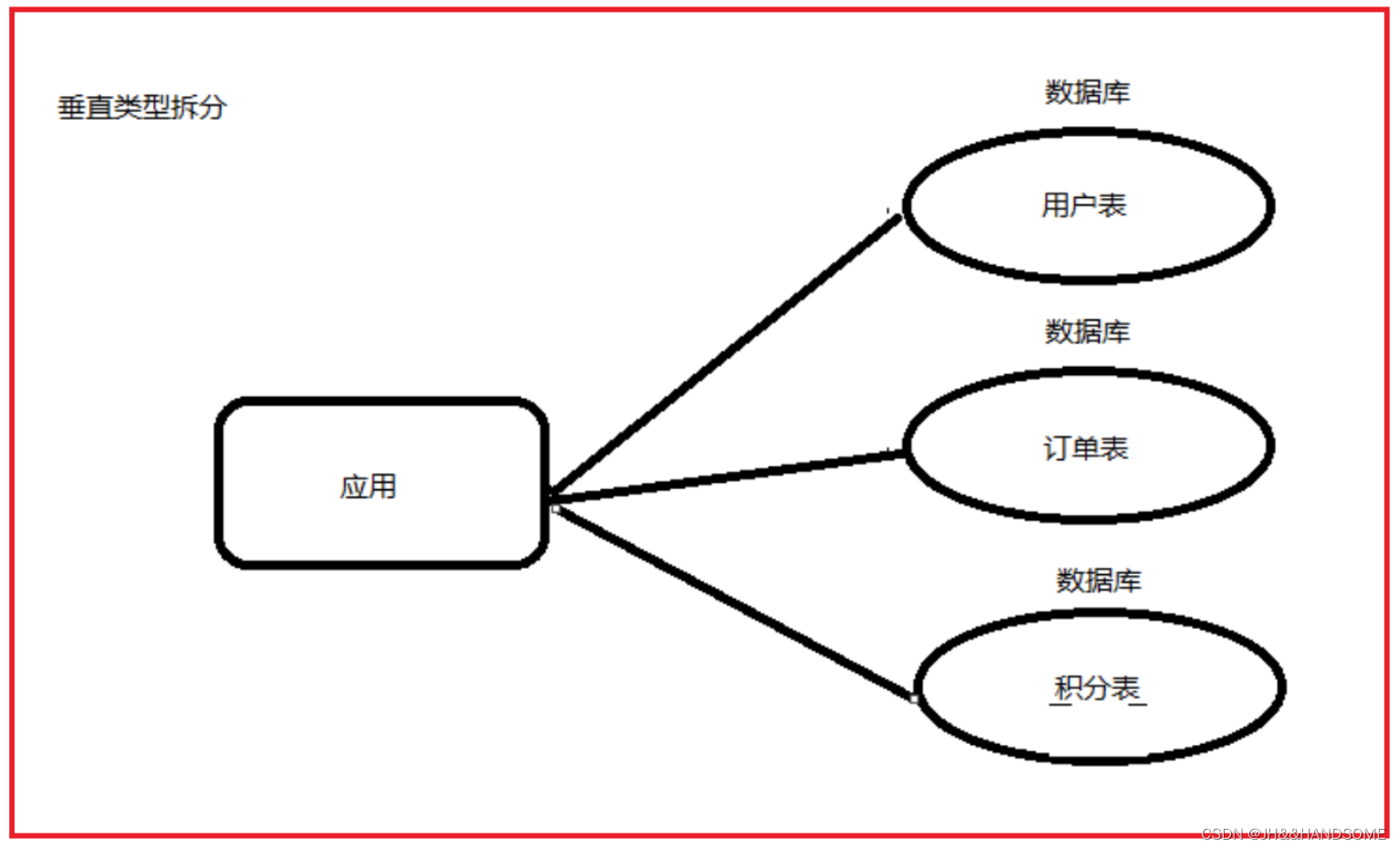
分表字段选择

2、分库分表操作:
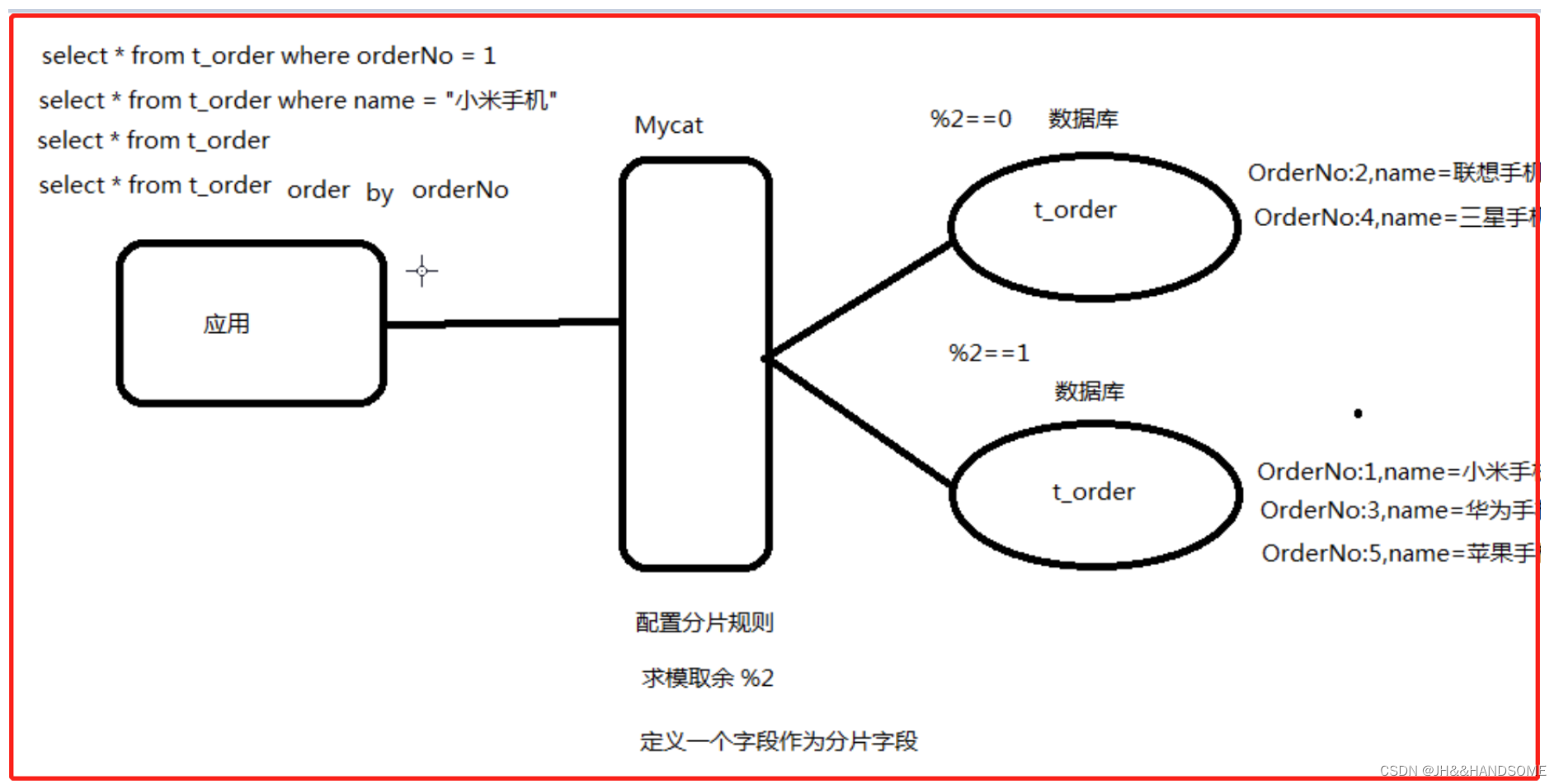
1、分析图:
2、克隆主从
在克隆出一个主数据和从数据
以前克隆后的id修改步骤参考
主数据库 :192.168.209.154
从数据库:192.168.209.155
这两个主从数据库的配置方法跟第一次配置的一样,参考下配置
步骤:
主数据库:
1、vi /etc/my.cnf 编辑
server-id=154 #基本就是用id后3为做标识
log-bin=master-bin
log-bin-index=master-bin.index
2、因为是拷贝的,所以需要修改mysql的uuid
查找mysql的位置 find / -iname “auto.cnf”
vi 拷贝查出来的位置,进入编辑,随便改uuid中的一个字母就行,保证唯一就可以
3、启动mysql mysql -uroot -p123456
如果启动不起来,错误:-bash: mysql: command not found,输入:alias mysql=/usr/local/mysql/bin/mysql
4、查看主节点的状态 show master status从数据库:
1、vi /etc/my.cnf 编辑
server-id=155 #基本就是用id后3为做标识
log-bin=master-bin
log-bin-index=master-bin.index
2、因为是拷贝的,所以需要修改mysql的uuid
查找mysql的位置 find / -iname “auto.cnf”
vi 拷贝查出来的位置,进入编辑,随便改uuid中的一个字母就行,保证唯一就可以
3、启动mysql mysql -uroot -p123456
如果启动不起来,错误:-bash: mysql: command not found,输入:alias mysql=/usr/local/mysql/bin/mysql
4、停止节点链路 stop slave;
5、配置文件:change master to master_host=‘192.168.209.154’,master_user=‘root’,master_password=‘123456’,master_log_file=‘master-bin.000001’,master_log_pos=156;
通过主节点的 show master status,查看master-bin 和 master_log_pos(就是position)是多少,要保持一致,master_host也是要写主节点的id
6、启动从节点链路 start slave;
7、查看链路状态 show slave status \G; 要有两个yes才行
8、重启mysql的命令 service mysqld restart对应id创建主从数据库
3、配置MyCat
修改配置文件
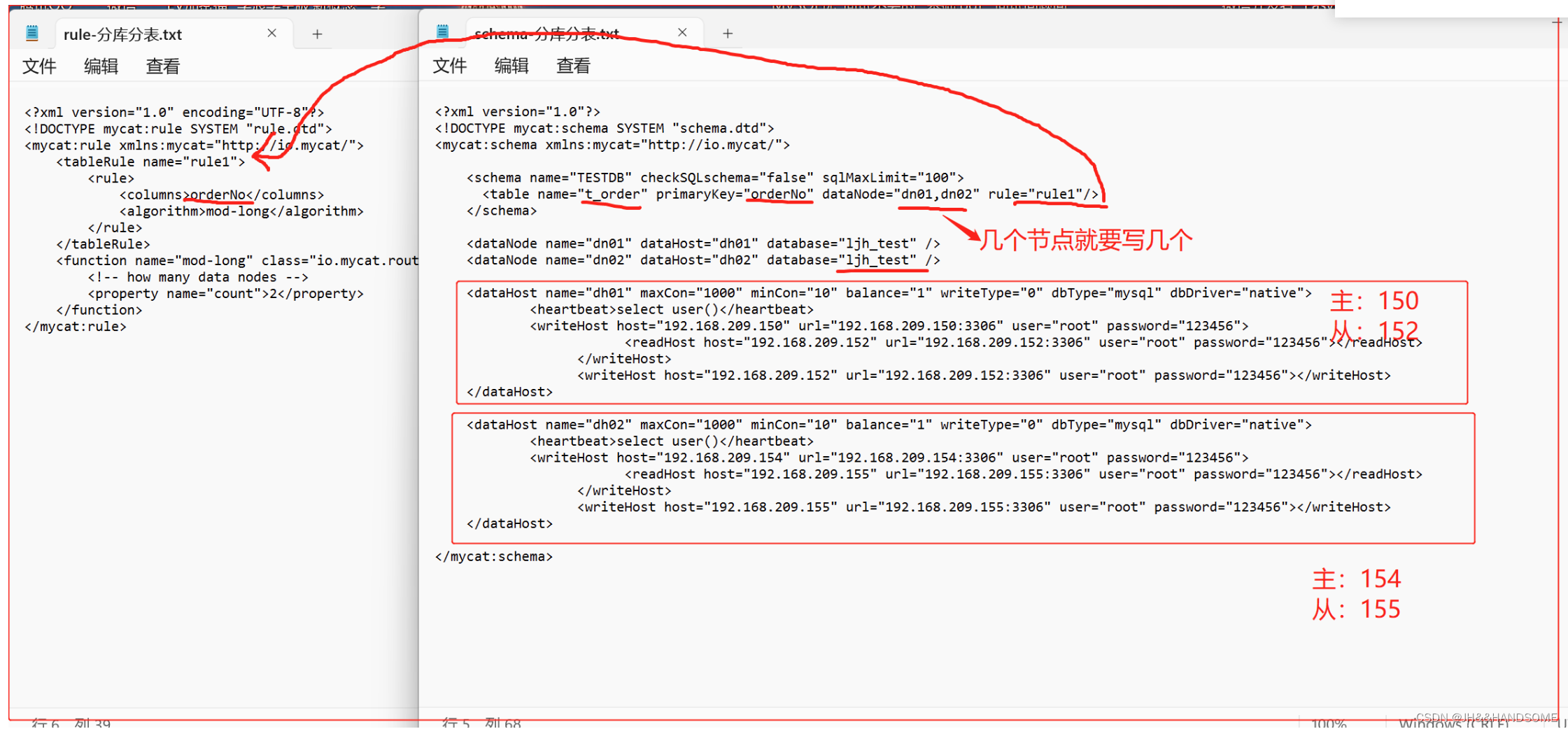
schema.xml
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100"> <table name="t_order" primaryKey="orderNo" dataNode="dn01,dn02" rule="rule1"/> </schema> <dataNode name="dn01" dataHost="dh01" database="ljh_test" /> <dataNode name="dn02" dataHost="dh02" database="ljh_test" /> <dataHost name="dh01" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.209.150" url="192.168.209.150:3306" user="root" password="123456"> <readHost host="192.168.209.152" url="192.168.209.152:3306" user="root" password="123456"></readHost> </writeHost> <writeHost host="192.168.209.152" url="192.168.209.152:3306" user="root" password="123456"></writeHost> </dataHost> <dataHost name="dh02" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.209.154" url="192.168.209.154:3306" user="root" password="123456"> <readHost host="192.168.209.155" url="192.168.209.155:3306" user="root" password="123456"></readHost> </writeHost> <writeHost host="192.168.209.155" url="192.168.209.155:3306" user="root" password="123456"></writeHost> </dataHost> </mycat:schema>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
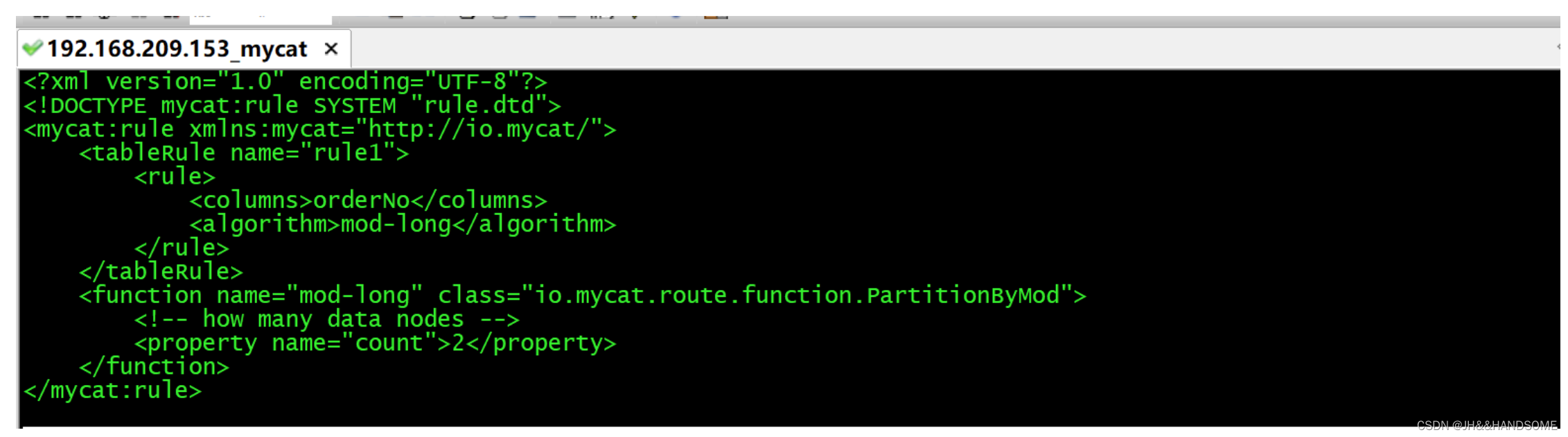
rule.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mycat:rule SYSTEM "rule.dtd"> <mycat:rule xmlns:mycat="http://io.mycat/"> <tableRule name="rule1"> <rule> <columns>orderNo</columns> <algorithm>mod-long</algorithm> </rule> </tableRule> <function name="mod-long" class="io.mycat.route.function.PartitionByMod"> <!-- how many data nodes --> <property name="count">2</property> </function> </mycat:rule>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
schema.xml
编写文件:vi /usr/local/mycat/conf/schema.xml

拷贝进去,格式乱不用理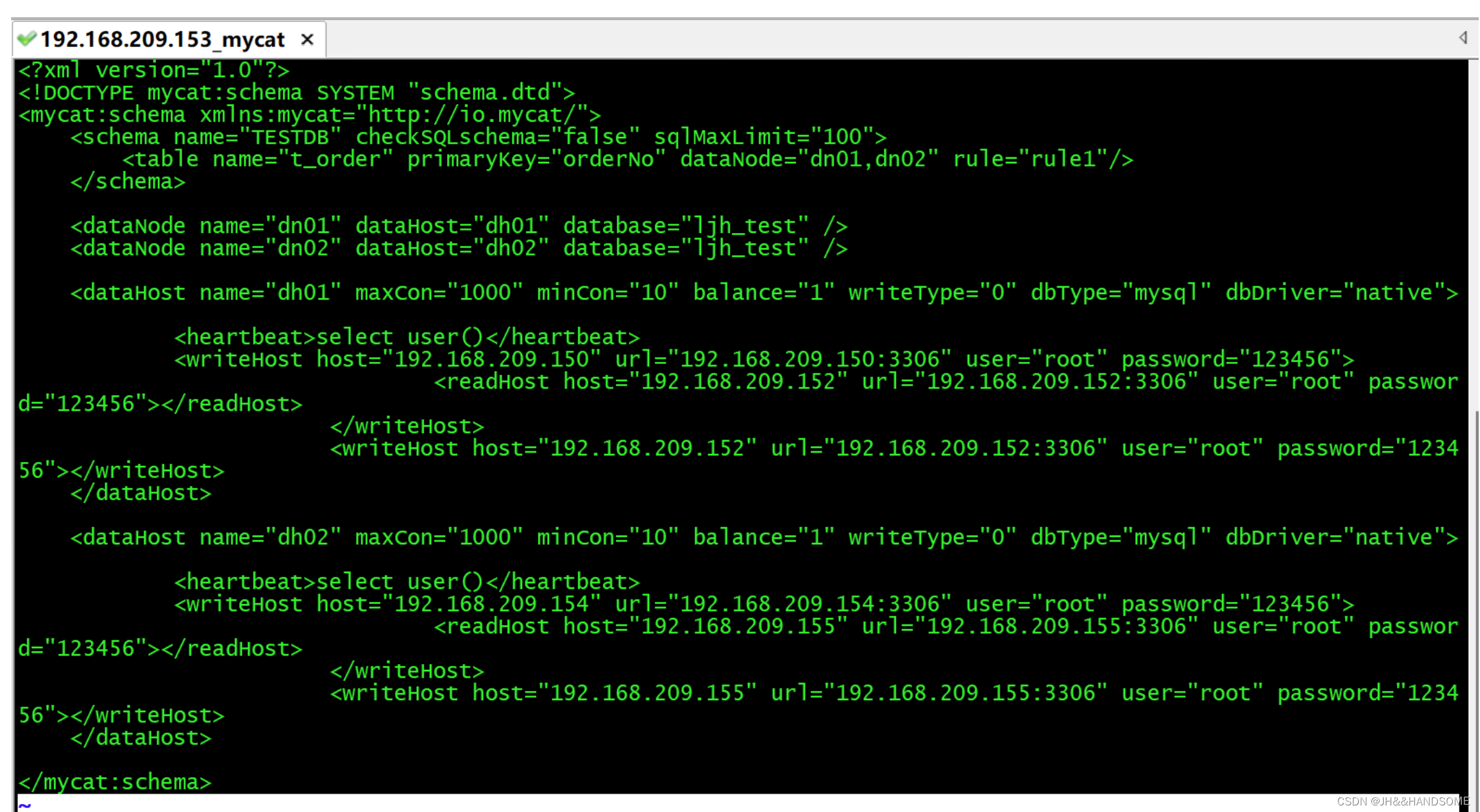
rule.xml
vi /usr/local/mycat/conf/rule.xml

重启mycat
启动mycat: /usr/local/mycat/bin/mycat start
重启mycat:/usr/local/mycat/bin/mycat restart
查看mycat日志: tail -f -n 50 /usr/local/mycat/logs/wrapper.log
有successfully就是重启成功

4、测试:
**测试1:**把之前的数据都清空,插入五条数据,看是否会根据求模取余,把5条数据分别插在两个主数据库中(150和154)

分库分表后插入成功,成功把数据分两个数据库插入。
**测试2:**获取所有的数据,看能不能从两张数据库中把数据完整的查出来
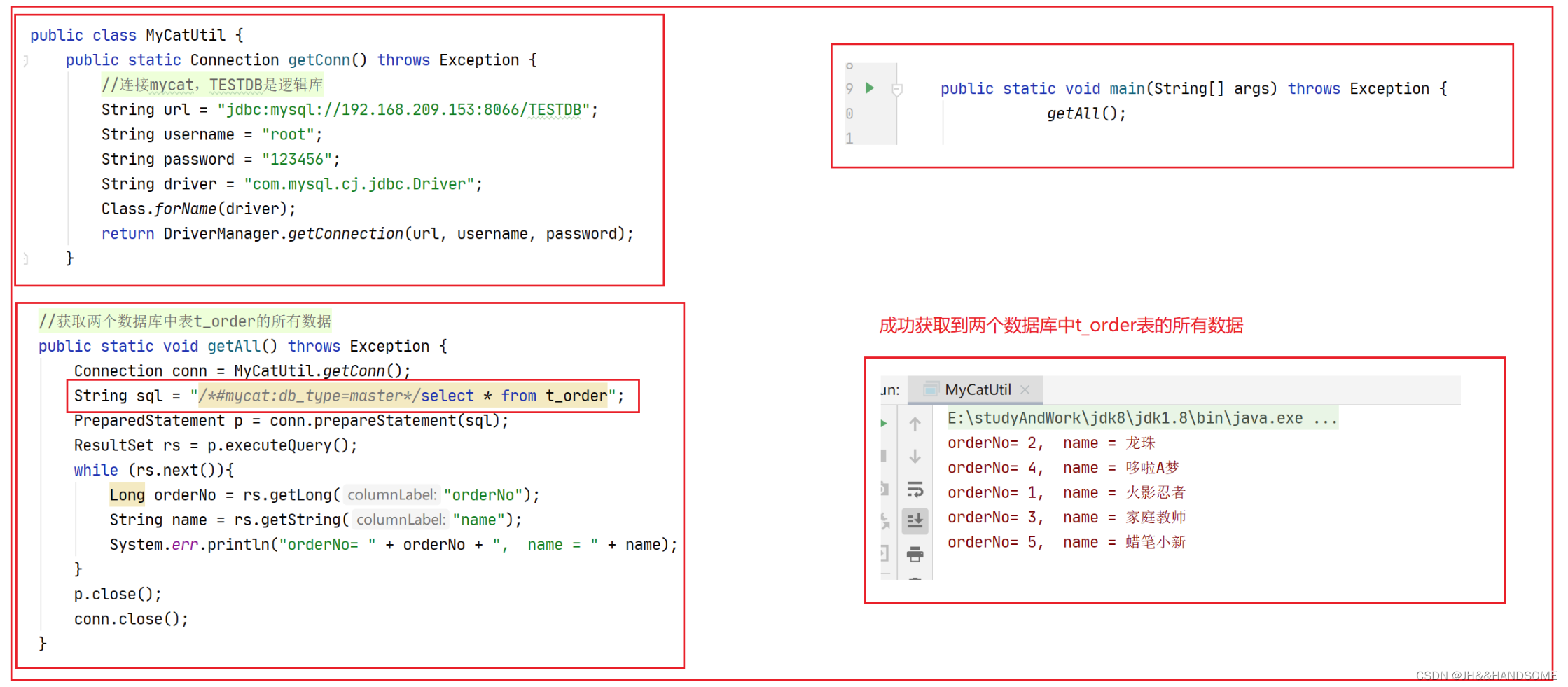
目前是还没有排序的,需要修改下sql
**测试3:**两个数据库,两张表,看查出来的数据能否正确排序
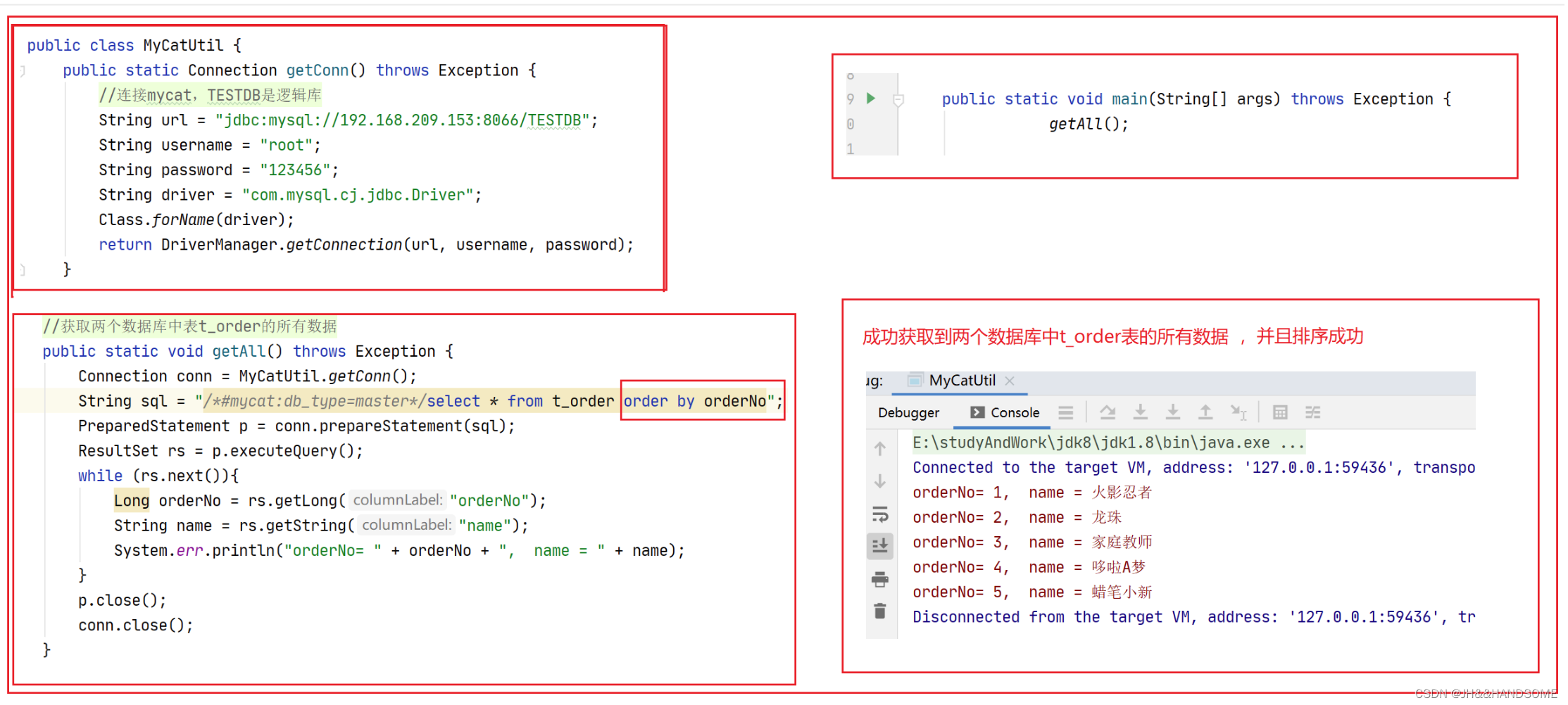
测试成功。
mysql系统架构各模块工作配合
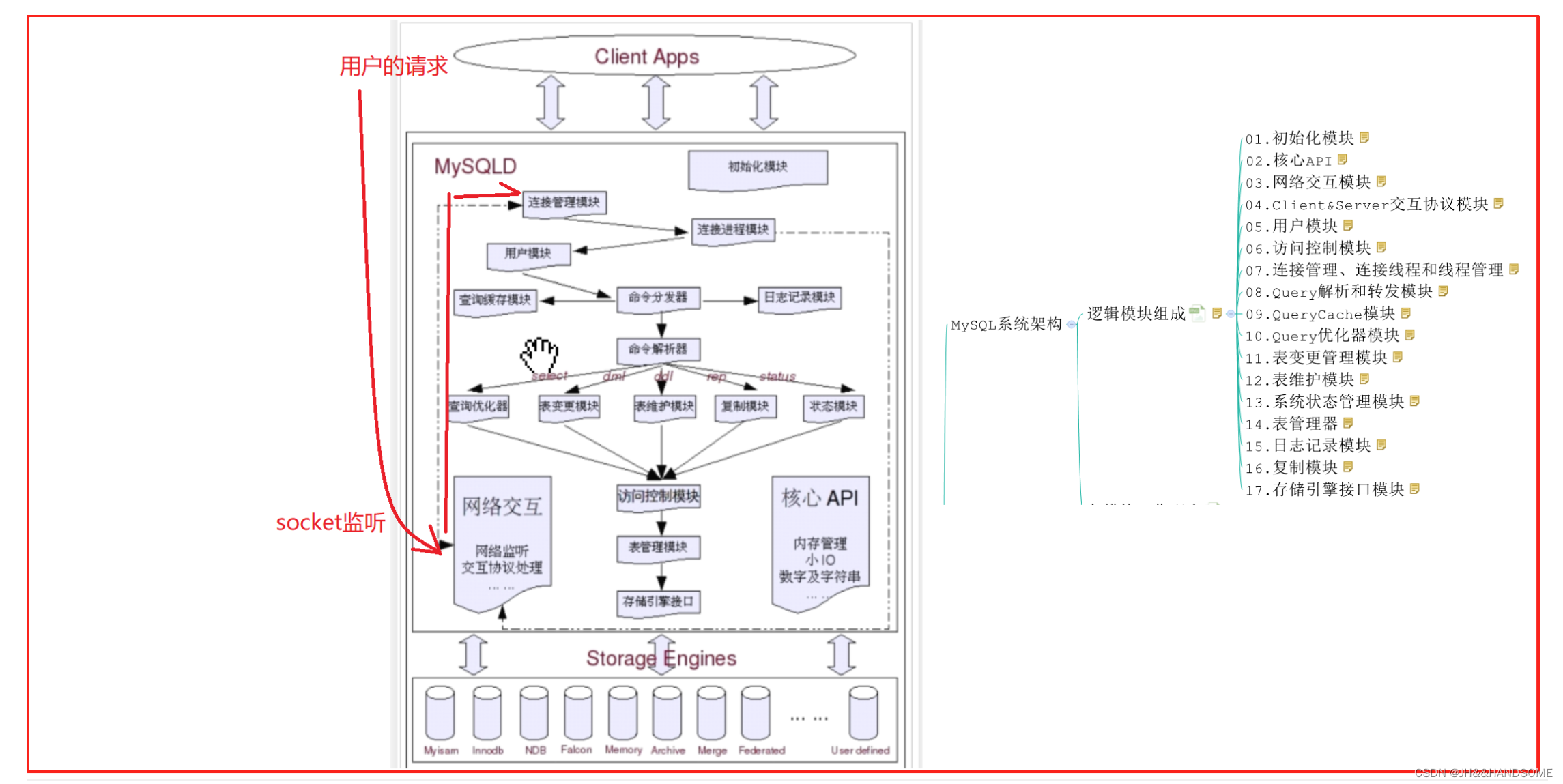
当我们执行启动 MySQL 命令之后,MySQL 的初始化模块就从系统配置文件中读取系统参数和命令行参数,并按照参数来初始化整个系统,如申请并分配 buffer,初始化全局变量以及各种结构等。同时各个存储引擎也被启动,并进行各自的初始化工作。当整个系统初始化结束后,由连接管理模块接手。连接管理模块会启动处理客户端连接请求的监听程序,包 括 tcp/ip 的网络监听,还有 unix 的 socket。这时候,MySQL Server 就基本启动完成,准备好接受客户端请求了。
当连接管理模块监听到客户端的连接请求(借助网络交互模块的相关功能),双方通过Client & Server 交互协议模块所定义的协议“寒暄”几句之后,连接管理模块就会将连接请求转发给线程管理模块,去请求一个连接线程。线程管理模块马上又会将控制交给连接线程模块,告诉连接线程模块:现在我这边有连接请求过来了,需要建立连接,你赶快处理一下。连接线程模块在接到连接请求后,首先会检查当前连接线程池中是否有被 cache 的空闲连接线程,如果有,就取出一个和客户端请求连接上,如果没有空闲的连接线程,则建立一个新的连接线程与客户端请求连接。当然,连接线程模块并不是在收到连接请求后马上就会取出一个连接线程连和客户端连接,而是首先通过调用用户模块进行授权检查,只有客户端请求通过了授权检查后,他才会将客户端请求和负责请求的连接线程连上。在 MySQL 中,将客户端请求分为了两种类型:一种是 query,需要调用 Parser 也就是Query 解析和转发模块的解析才能够执行的请求;一种是 command,不需要调用 Parser 就可以直接执行的请求。如果我们的初始化配置中打开了 Full Query Logging 的功能,那么Query 解析与转发模块会调用日志记录模块将请求计入日志,不管是一个 Query 类型的请求还是一个 command 类型的请求,都会被记录进入日志,所以出于性能考虑,一般很少打开FullQuery Logging 的功能。
当客户端请求和连接线程“互换暗号(互通协议)”接上头之后,连接线程就开始处理客户端请求发送过来的各种命令(或者 query),接受相关请求。它将收到的 query 语句转给 Query 解析和转发模块,Query 解析器先对 Query 进行基本的语义和语法解析,然后根据命令类型的不同,有些会直接处理,有些会分发给其他模块来处理。
如果是一个 Query 类型的请求,会将控制权交给 Query 解析器。Query 解析器首先分析看是不是一个 select 类型的 query,如果是,则调用查询缓存模块,让它检查该 query 在query cache 中是否已经存在。如果有,则直接将 cache 中的数据返回给连接线程模块,然后通过与客户端的连接的线程将数据传输给客户端。如果不是一个可以被 cache 的 query类型,或者 cache 中没有该 query 的数据,那么 query 将被继续传回 query 解析器,让 query解析器进行相应处理,再通过 query 分发器分发给相关处理模块。
如果解析器解析结果是一条未被 cache 的 select 语句,则将控制权交给 Optimizer,也就是 Query 优化器模块,如果是 DML 或者是 DDL 语句,则会交给表变更管理模块,如果是一些更新统计信息、检测、修复和整理类的 query 则会交给表维护模块去处理,复制相关的query 则转交给复制模块去进行相应的处理,请求状态的 query 则转交给了状态收集报告模块。实际上表变更管理模块根据所对应的处理请求的不同,是分别由 insert 处理器、delete处理器、update 处理器、create 处理器,以及 alter 处理器这些小模块来负责不同的 DML和 DDL 的。
在各个模块收到 Query 解析与分发模块分发过来的请求后,首先会通过访问控制模块检查连接用户是否有访问目标表以及目标字段的权限,如果有,就会调用表管理模块请求相应的表,并获取对应的锁。表管理模块首先会查看该表是否已经存在于 table cache 中,如果已经打开则直接进行锁相关的处理,如果没有在 cache 中,则需要再打开表文件获取锁,然后将打开的表交给表变更管理模块。
当表变更管理模块“获取”打开的表之后,就会根据该表的相关 meta 信息,判断表的存储引擎类型和其他相关信息。根据表的存储引擎类型,提交请求给存储引擎接口模块,调用对应的存储引擎实现模块,进行相应处理。
不过,对于表变更管理模块来说,可见的仅是存储引擎接口模块所提供的一系列“标准”接口,底层存储引擎实现模块的具体实现,对于表变更管理模块来说是透明的。他只需要调用对应的接口,并指明表类型,接口模块会根据表类型调用正确的存储引擎来进行相应的处理。
当一条 query 或者一个 command 处理完成(成功或者失败)之后,控制权都会交还给连接线程模块。如果处理成功,则将处理结果(可能是一个 Result set,也可能是成功或者失败的标识)通过连接线程反馈给客户端。如果处理过程中发生错误,也会将相应的错误信息发送给客户端,然后连接线程模块会进行相应的清理工作,并继续等待后面的请求,重复上面提到的过程,或者完成客户端断开连接的请求。
当一条 query 或者一个 command 处理完成(成功或者失败)之后,控制权都会交还给连接线程模块。如果处理成功,则将处理结果(可能是一个 Result set,也可能是成功或者失败的标识)通过连接线程反馈给客户端。如果处理过程中发生错误,也会将相应的错误信息发送给客户端,然后连接线程模块会进行相应的清理工作,并继续等待后面的请求,重复上面提到的过程,或者完成客户端断开连接的请求。
schema.xml
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- name:逻辑库的名字 checkSQLschema:当该值设置为 true 时,如果我们执行语句**select * from TESTDB.travelrecord;** 则 MyCat 会把语句修改为**select * from travelrecord;**。 设置成false,要求应用程序端,SQL语句不要带数据库名,不然识别不了 sqlMaxLimit:当用户没有写limit语句,给这个语句默认加上 limit 100,如果用户写了则不会加。 --> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100"> <!-- name:逻辑表表名 dataNode:数据分片id,对应这下面的dataNode节点的name属性(执行的sql的数据被分成多片) --> <table name="t_order" dataNode="dn01"/> </schema> <!-- name:数据分片的名称,给table引用的 dataHost:数据库实例的id,对应下面dataHost节点的name属性 database:访问对应数据库实例里面的哪个数据库 --> <dataNode name="dn01" dataHost="dn01" database="ljh_test" /> <!-- name:数据库实例的名称,给我们dataNode标签进行引用 maxCon:最大连接数 minCon:最小连接数 dbType:后端关联的数据库类型是什么类型(因为mycat支持多种数据,这里要标明白) dbDriver:表示是原生的MySQL,不是被定制、改装过的,是原版。 balance:负载均衡策略 balance="1",全部的readHost与stand by writeHost参与select语句的负载均衡, 简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备), 正常情况下,M2,S1,S2都参与select语句的负载均衡 writeType:writeType="0", 所有写操作发送到配置的第一个writeHost, 第一个挂了切到还生存的第二个writeHost,重新启动后已切换后的为准, 切换记录在配置文件中:dnindex.properties . --> <dataHost name="dn01" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <!-- 心跳机制 --> <heartbeat>select user()</heartbeat> <!-- 写节点的配置 host:主机名 url:连接的访问地址 user:后端数据库的用户名 password:后端数据库的用户密码 --> <writeHost host="192.168.209.150" url="192.168.209.150:3306" user="root" password="123456"> <!-- 读节点配置 --> <readHost host="192.168.209.152" url="192.168.209.152:3306" user="root" password="123456" /> </writeHost> <!-- 备用写节点 ,主的挂了之后,这个备用的就变成主了,能读能写 --> <writeHost host="192.168.209.152" url="192.168.209.152:3316" user="root" password="123456" /> </dataHost> </mycat:schema>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
-
相关阅读:
uni-app的支付与打包上传
excel 表格横向拼接(列拼接)
基于Android Studio+Android SDK的手机通讯录管理软件设计
Istio(九):istio安全之授权
typescript
NISP和CISP中的网络安全设备运维体系建设
Java 基础面试300题 (261-290)
性能测试监控指标及分析调优 | 京东云技术团队一、哪些因素会成为系统的瓶颈?
WordPress 6.1 “Misha“
操作系统概述
- 原文地址:https://blog.csdn.net/weixin_44411039/article/details/133933157