-
Selenium环境+元素定位大法
selenium 与 webdriver
Selenium 是一个用于 Web 测试的工具,测试运行在浏览器中,就像真正的用户在手工操作一样。支持所有主流浏览器
WebDriver 就是对浏览器提供的原生API进行封装,使其成为一套更加面向对象的Selenium WebDriver API。
使用这套API可以操控浏览器的开启、关闭,打开网页,操作界面元素,控制Cookie,还可以操作浏览器截屏、安装插件、设置代理、配置证书等环境搭建
1、为 Python 安装 selenium模块,pip install selenium
2、下载对应浏览器驱动
Chromedriver
使用 selenium 访问百度并搜索
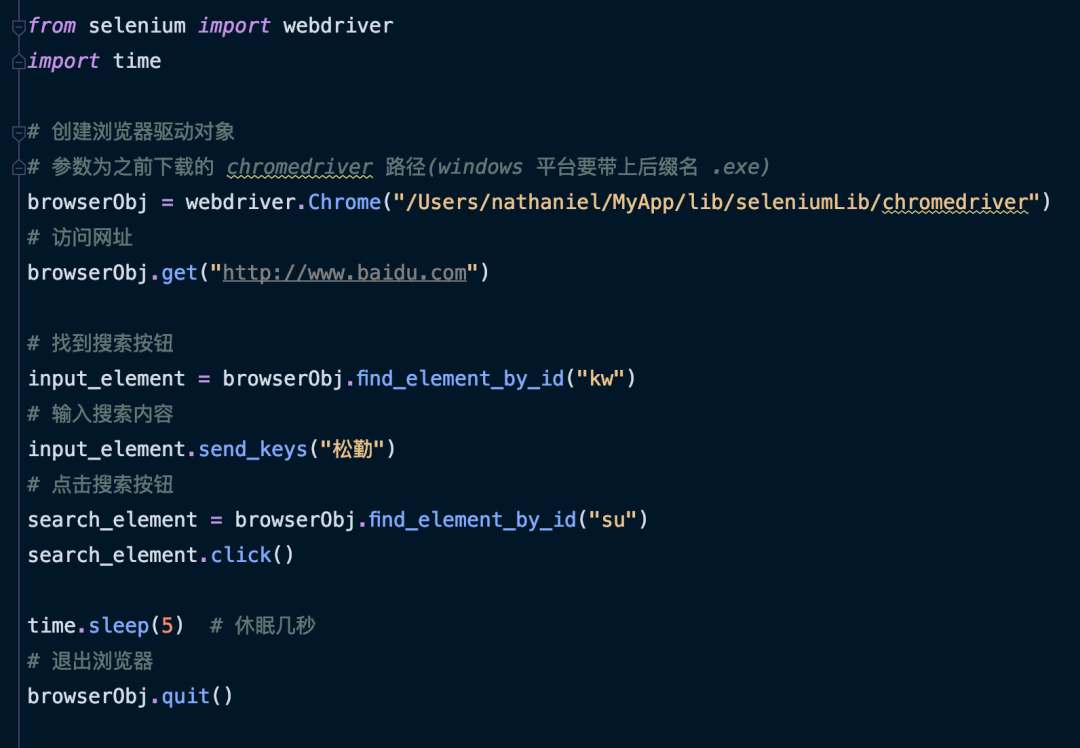
反爬虫设置

ui 自动化操作流程
选择界面元素
根据元素的特征:ID,Name,Class,Tag,等
根据元素特征和关系:css,xpath
操作界面元素
输入操作:点击、输入文字、拖拽等
输出操作:获取元素的各种属性
根据界面上获取的数据进行分析和处理
元素定位大法
find_element_by_id:通过ID进行匹配查找,只返回匹配到的一个元素
find_element_by_name:通过name进行匹配查找,只返回匹配到的一个元素
find_element_by_xpath:通过xpath进行匹配查找,只返回匹配到的一个元素
find_element_by_link_text:通过链接内容进行匹配查找,只返回匹配到的一个元素
find_element_by_partical_link_text:通过部分链接内容进行匹配查找,只返回匹配到的一个元素
find_element_by_tag_name:通过标签名称进行匹配查找,只返回匹配到的一个元素
find_element_by_class_name:通过class名称进行匹配查找,只返回匹配到的一个元素
find_element_by_css_selector:通过CSS选择器进行匹配查找,只返回匹配到的一个元素
值得注意的是,上面方法只会匹配查找只会获取第一个元素。除了上面这些查找单个元素的方法之外,Selenium还定义查找多个元素的方法:
find_elements_by_name:通过name进行匹配查找,返回所有匹配到的元素列表
find_elements_by_xpath:通过xpath进行匹配查找,返回所有匹配到的元素列表
find_elements_by_link_text:通过链接内容进行匹配查找,返回所有匹配到的元素列表
find_elements_by_partical_link_text:通过部分链接内容进行匹配查找,返回所有匹配到的元素列表
find_elements_by_tag_name:通过标签名称进行匹配查找,返回所有匹配到的元素列表
find_elements_by_class_name:通过class名称进行匹配查找,返回所有匹配到的元素列表
find_elements_by_css_selector:通过CSS选择器进行匹配查找,返回所有匹配到的元素列表



注意:
1、根据 class_name 进行定位的时候,有时候会遇到复合类,也就是 class 属性中间有空格,class 属性比较特殊,class属性中间的空格是间隔符号,表示的是一个元素有多个class的属性名称,此时元素定位的时候任取一个即可(不保证唯一定位)
2、selenium 没有提供判断元素是否存在的功能,所以当你需要判断一个元素存不存在的时候,直接定位可能会报错。我们可以去匹配一个元素列表,列表为空则元素不存在,列表不为空则元素存在
技巧,在进行元素定位的时候,有时会遇到一些特别难以定位的元素,此时你可以使用下边这种模式,分步骤定位,一步步缩小定位范围
ele = driver.find_elements_by_xpath("//div[@id='category-block']//ol/li")
b = ele.find_elements_by_xpath('.//li[@class=\'subcate-item\']//span')总结:
感谢每一个认真阅读我文章的人!!!
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。
文档获取方式:
加入我的软件测试交流群:632880530免费获取~(同行大佬一起学术交流,每晚都有大佬直播分享技术知识点)这份文档,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!
以上均可以分享,只需要你搜索vx公众号:程序员雨果,即可免费领取
-
相关阅读:
天软特色因子看板 (2023.09 第04期)
学习SpringMvc第二战之【SpringMVC之综合案例】
UE基础必学系列:UMG
【数据结构】绪论
go test传参问题
16. 如何修改 SAP ABAP OData 模型,使其支持 $expand 操作
设计模式(4)-行为型模式
【Vue2.0源码学习】生命周期篇-初始化阶段(initInjections)
MySQL库表占用空间排序
STM32 IWDG&WWDG
- 原文地址:https://blog.csdn.net/2301_79535544/article/details/133933165