-
SEAL:RLWE-BFV 开源算法库
参考文献:
- GitHub - microsoft/SEAL: Microsoft SEAL is an easy-to-use and powerful homomorphic encryption library.
- [NL11] Naehrig M, Lauter K, Vaikuntanathan V. Can homomorphic encryption be practical?[C]//Proceedings of the 3rd ACM workshop on Cloud computing security workshop. 2011: 113-124.
- [GC15] Geihs M, Cabarcas D. Efficient integer encoding for homomorphic encryption via ring isomorphisms[C]//Progress in Cryptology-LATINCRYPT 2014: Third International Conference on Cryptology and Information Security in Latin America Florianópolis, Brazil, September 17–19, 2014 Revised Selected Papers 3. Springer International Publishing, 2015: 48-63.
- [DGL+15] Dowlin N, Gilad-Bachrach R, Laine K, et al. Manual for using homomorphic encryption for bioinformatics[J]. 2015.
- [CLP17] Chen H, Laine K, Player R. Simple encrypted arithmetic library-SEAL v2. 1[C]//Financial Cryptography and Data Security: FC 2017 International Workshops, WAHC, BITCOIN, VOTING, WTSC, and TA, Sliema, Malta, April 7, 2017, Revised Selected Papers 21. Springer International Publishing, 2017: 3-18.
- [Alb15] Martin R. Albrecht, Rachel Player, and Sam Scott. On the concrete hardness of learning with errors. J. Mathematical Cryptology,9(3):169–203, 2015.
- [HS13] Halevi S, Shoup V. Design and implementation of a homomorphic-encryption library[J]. IBM Research (Manuscript), 2013, 6(12-15): 8-36.
SEAL 算法库
BFV 变体
微软 [DGL+15] 给出了 BFV 的简单实现 SEAL(Simple Encrypted Arithmetic Library),之后的 [CLP17] 描述了 SEAL v2.1 版本。
SEAL 认为 BFV 的重线性化太慢了,因此它的同态乘法忽略了重线性化操作,仅在必要时才手动降低密文规模。
分园多项式环 R = Z [ x ] / ( x n + 1 ) R=\mathbb Z[x]/(x^n+1) R=Z[x]/(xn+1),明文空间 R t R_t Rt,密文空间 ⋃ k ≥ 2 R t k \bigcup_{k \ge 2} R_t^k ⋃k≥2Rtk
-
加密算法:将 a ( x ) ∈ R t a(x) \in R_t a(x)∈Rt 加密为向量 c t = ( c 0 , c 1 ) ct=(c_0,c_1) ct=(c0,c1),满足
q t ⋅ a ≈ c t ( s ) = c 0 + c 1 s \dfrac{q}{t} \cdot a \approx ct(s) = c_0+c_1s tq⋅a≈ct(s)=c0+c1s -
同态加法:输入 c t 1 = ( c 0 , ⋯ , c j ) ct_1=(c_0,\cdots,c_j) ct1=(c0,⋯,cj) 和 c t 2 = ( d 0 , ⋯ , d k ) ct_2=(d_0,\cdots,d_k) ct2=(d0,⋯,dk),假设 j ≤ k j \le k j≤k,
c t a d d = ( [ c 0 + d 0 ] q , ⋯ , [ c j + d j ] q , d j + 1 , ⋯ , d k ) ct_{add} = ([c_0+d_0]_q,\cdots,[c_j+d_j]_q,d_{j+1},\cdots,d_k) ctadd=([c0+d0]q,⋯,[cj+dj]q,dj+1,⋯,dk) -
同态乘法:输入 c t 1 = ( c 0 , ⋯ , c j ) ct_1=(c_0,\cdots,c_j) ct1=(c0,⋯,cj) 和 c t 2 = ( d 0 , ⋯ , d k ) ct_2=(d_0,\cdots,d_k) ct2=(d0,⋯,dk), c t m u l t = ( C 0 , ⋯ , C j + k ) ct_{mult} = (C_0,\cdots,C_{j+k}) ctmult=(C0,⋯,Cj+k),
C i = [ ⌊ t q ∑ r + s = i c r d s ⌉ ] q C_i = \left[\left\lfloor \dfrac{t}{q}\sum_{r+s=i} c_rd_s \right\rceil\right]_q Ci=[⌊qtr+s=i∑crds⌉]q -
解密算法:输入 c t = ( c 0 , ⋯ , c k ) ct=(c_0,\cdots,c_k) ct=(c0,⋯,ck),先计算
c t ( s ) = ∑ i c i s i ∈ R q ct(s) = \sum_i c_is^i \in R_q ct(s)=i∑cisi∈Rq
再解码出 a = [ ⌊ t / q ⋅ c t ( s ) ⌉ ] t ∈ R t a = [\lfloor t/q \cdot ct(s) \rceil]_t \in R_t a=[⌊t/q⋅ct(s)⌉]t∈Rt
另外,SEAL 扩展了 evaluation key 和 relinearization。假设把 q q q 做 w w w 进制展开为 l + 1 l+1 l+1 比特,以控制噪声增长。采样 a j i ← R q , e j i ← χ a_{ji} \gets R_q,e_{ji} \gets \chi aji←Rq,eji←χ,分别加密 s j , ∀ j ≥ 2 s^j,\forall j \ge 2 sj,∀j≥2,
e v k j = [ ( w 0 s j − ( a j , 0 s + e j , 0 ) , a j , 0 ) , ⋯ , ( w l s j − ( a j , l s + e j , l ) , a j , l ) ] evk_j = [(w^0s^j-(a_{j,0}s+e_{j,0}),a_{j,0}),\cdots,(w^ls^j-(a_{j,l}s+e_{j,l}),a_{j,l})] evkj=[(w0sj−(aj,0s+ej,0),aj,0),⋯,(wlsj−(aj,ls+ej,l),aj,l)]给定 e v k 2 , ⋯ , e v k k evk_2,\cdots,evk_k evk2,⋯,evkk,输入 c t = ( c 0 , ⋯ , c k ) ct=(c_0,\cdots,c_k) ct=(c0,⋯,ck),令 c k ( i ) c_k^{(i)} ck(i) 是它的 w w w 进制分解,可以计算同态数乘
c 0 ′ = c 0 + ∑ i = 0 l e v k k [ i ] [ 0 ] ⋅ c k ( i ) c 1 ′ = c 1 + ∑ i = 0 l e v k k [ i ] [ 1 ] ⋅ c k ( i ) c j ′ = c j , ∀ 2 ≤ j ≤ k − 1 c_0' = c_0 + \sum_{i=0}^l evk_k[i][0] \cdot c_k^{(i)}\\ c_1' = c_1 + \sum_{i=0}^l evk_k[i][1] \cdot c_k^{(i)}\\ c_j' = c_j, \forall 2 \le j \le k-1 c0′=c0+i=0∑levkk[i][0]⋅ck(i)c1′=c1+i=0∑levkk[i][1]⋅ck(i)cj′=cj,∀2≤j≤k−1得到 c t ′ = ( c 0 ′ , ⋯ , c k − 1 ′ ) ct' = (c_0',\cdots,c'_{k-1}) ct′=(c0′,⋯,ck−1′),迭代多次回到 c t ′ ′ = ( c 0 ′ ′ , c 1 ′ ′ ) ct''=(c_0'',c_1'') ct′′=(c0′′,c1′′)
参数选取
[HS13] 给出了 BGV 的代码实现 HElib,但是并没有给出最佳参数选取,需要经过实机测试。[CLP17] 给出了一些参数选取的思路:
- 密文模数 q q q 形如 2 A − B 2^A-B 2A−B(伪梅森素数),其中 B B B 是绝对值很小的整数。此时,存在快速的模约简算法。
- 满足 2 n ∣ q − 1 2n|q-1 2n∣q−1,从而可以使用 NTT 计算密文多项式的乘法。
- 满足 t ∣ q − 1 t|q-1 t∣q−1,此时 q = Δ t + r t ( q ) q = \Delta t+r_t(q) q=Δt+rt(q) 中的余数 r t ( q ) = 1 r_t(q)=1 rt(q)=1 很小,从而使得同态运算的噪声项 p o l y ( e 1 , e 2 , r t ( q ) ) poly(e_1,e_2,r_t(q)) poly(e1,e2,rt(q)) 更小一些。
高斯噪声的标准差 σ = 3.19 \sigma = 3.19 σ=3.19,此时的高斯宽度 α q = σ 2 π ≈ 8 \alpha q=\sigma \sqrt{2\pi} \approx 8 αq=σ2π≈8
[Alb15] 提出了针对 “short secret” LWE 的一种新型 BKW-style dual-lattice attack,将 HElib 和 SEAL 的安全强度降低了大约 20 20 20 比特。在 [APS15] 中实现的 LWE estimator 集成了这种攻击。
SEAL v2.1 的参数选取 ( n , q , α ) (n,q,\alpha) (n,q,α) 以及安全强度:
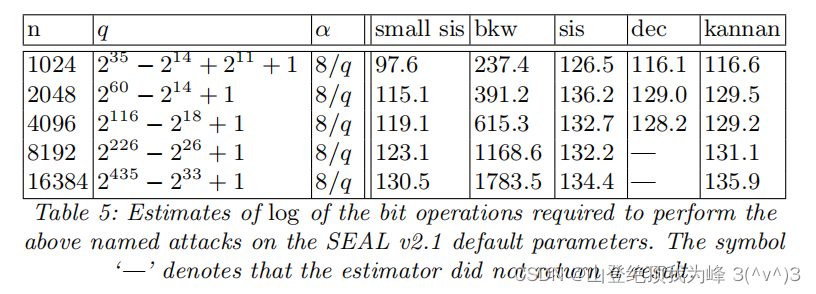
SEAL 的编码算法
由于 BFV 计算的是多项式的加法/乘法,我们希望把数值(int, float, bool)编码为多项式,并且保持同态性质。于是,我们需要同态的编码方案:只要不越界 t t t 和 x n + 1 x^n+1 xn+1,那么就可以正确解码。
Scalar Encoder
给定整数 a ∈ Z a \in \mathbb Z a∈Z,编码为常数多项式 a ( x ) = a ∈ R t a(x) = a \in R_t a(x)=a∈Rt,只要同态运算过程中不越界 t t t 那么解码正确
对于布尔值 b ∈ { 0 , 1 } b \in \{0,1\} b∈{0,1},我们设置 t = 2 t=2 t=2,于是 b ( x ) = b ∈ R 2 b(x)=b \in R_2 b(x)=b∈R2,运算过程中自动模掉 2 2 2
为了高效计算 XOR、AND,也可以选取 2 n ∣ t − 1 2n|t-1 2n∣t−1,从而 R t ≅ G F ( t ) n R_t \cong GF(t)^n Rt≅GF(t)n,以 CRT/SIMD 形式并行。
Integer Encoder
但是 Scalar Encoder 实在太浪费了,SEAL 提出可以把整数分解后编码到多项式上。并且分解后的系数较小,也不太容易越过 t t t 导致溢出。
对于 w = 2 w=2 w=2 分解, n + 1 n+1 n+1 比特的带符号整数 a = ( − 1 ) a n ⋅ ∑ i = 0 n − 1 a i 2 i a=(-1)^{a_n} \cdot\sum_{i=0}^{n-1} a_i2^i a=(−1)an⋅∑i=0n−1ai2i,编码函数为:
a ( x ) = ( − 1 ) a n ⋅ ∑ i = 0 n − 1 a i x i ( m o d x n + 1 , t ) a(x) = (-1)^{a_n} \cdot \sum_{i=0}^{n-1} a_i x^i \pmod{x^n+1,t} a(x)=(−1)an⋅i=0∑n−1aixi(modxn+1,t)易知,解码函数就是 a = a ( 2 ) a = a(2) a=a(2) 是多项式求值。于是有:
- 整数加法 a + b ⟺ a ( x ) + b ( x ) ( m o d x n + 1 , t ) a+b \iff a(x)+b(x) \pmod{x^n+1,t} a+b⟺a(x)+b(x)(modxn+1,t),它的系数是在 Z \mathbb Z Z 上的,但是用 Z t \mathbb Z_t Zt 来模拟。
- 整数乘法 a ⋅ b ⟺ a ( x ) ⋅ b ( x ) ( m o d x n + 1 , t ) a \cdot b \iff a(x) \cdot b(x) \pmod{x^n+1,t} a⋅b⟺a(x)⋅b(x)(modxn+1,t),它的多项式是在 Z [ x ] \mathbb Z[x] Z[x] 上的,但是用 Z t [ x ] / ( x n + 1 ) \mathbb Z_t[x]/(x^n+1) Zt[x]/(xn+1) 模拟。
- 整数 XOR 也是容易的,但是整数 AND 无法计算。
对于 w ≥ 3 w \ge 3 w≥3,采取 balanced base- w w w representation,多项式每个系数的范围是 { − ⌊ w / 2 ⌋ , ⋯ , 0 , ⋯ ⌊ w / 2 ⌋ } \{-\lfloor w/2\rfloor,\cdots,0,\cdots\lfloor w/2\rfloor\} {−⌊w/2⌋,⋯,0,⋯⌊w/2⌋},这使得同态运算时的系数增长的没那么快。
Fractional Encoder
对于有限精度的实数 a ∈ R a \in \mathbb R a∈R,我们可以采用 Scale + Integer Encoder 的方式,形如 ( a ( x ) , δ ) (a(x),\delta) (a(x),δ),但是同态计算时需要追踪 scale 的变化,并且不同 scale 之间做运算还需要转换。
SEAL 提出了另一种编码器。有限精度实数 a = a + . a − a=a^+.a^- a=a+.a−,
- 整数部分: a + = a n i a n i − 1 ⋯ a 0 a^+=a_{n_i}a_{n_i-1}\cdots a_0 a+=aniani−1⋯a0
- 小数部分: a − = a − 1 ⋯ a − n f a^-=a_{-1}\cdots a_{-n_f} a−=a−1⋯a−nf
- 符号位 a n i + a_{n_i}^+ ani+,整数部分的精度为 n i n_i ni,小数部分的精度为 n f n_f nf
编码函数为:
a ( x ) = ( − 1 ) a n i + ⋅ ( ∑ i = 0 n i − 1 a i + x i − ∑ i = 0 n f − 1 a i − x n − i ) ( m o d x n + 1 , t ) a(x) = (-1)^{a_{n_i}^+} \cdot \left(\sum_{i=0}^{n_i-1} a_i^+ x^i - \sum_{i=0}^{n_f-1} a_i^- x^{n-i}\right) \pmod{x^n+1,t} a(x)=(−1)ani+⋅ i=0∑ni−1ai+xi−i=0∑nf−1ai−xn−i (modxn+1,t)由于 ( m o d x n + 1 ) \pmod{x^n+1} (modxn+1),因此小数部分的 Integer Encoder 带有负号。容易验证, a + b ⟺ a ( x ) + b ( x ) a+b \iff a(x)+b(x) a+b⟺a(x)+b(x), a b ⟺ a ( x ) b ( x ) ab \iff a(x)b(x) ab⟺a(x)b(x),只要不越过边界 x n + 1 x^n+1 xn+1 和 t t t。我们需要设置 n i + n f ≤ n − 1 n_i+n_f \le n-1 ni+nf≤n−1,保证整数部分和小数部分不重叠。
如果在同态运算过程中,小数部分的 LSB 被消除(系数是 0 0 0)、整数部分的 MSB 被消除(系数是 0 0 0),那么对应的精度 n i , n f n_i,n_f ni,nf 也会相应缩小。比较 Scale + Integer Encoder,它的 Scale 不断增长,很容易越过 x n + 1 x^n+1 xn+1 导致溢出。
-
相关阅读:
【Linux升级之路】0_Linux入门 | 环境搭建 | 使用常识 | 用户管理
性能提升3-4倍!贝壳基于Flink + OceanBase的实时维表服务
linux安装gitlab-runner最新保姆级教程
shell awk命令
实验五 熟悉 Hive 的基本操作
Logback 配置文件这样优化,TPS提高 10 倍
【Spring系列】- 手写模拟Spring框架
linux文件相关命令
手机如何将PDF文件拆分?分享两种手机拆分文件方法
DDS协议介绍
- 原文地址:https://blog.csdn.net/weixin_44885334/article/details/133931316