-
解读 | 面向点云车辆检测的三维全卷积网络
原创 | 文 BFT机器人

01
摘要
此篇论文将原本用于图像中目标检测的二维全卷积网络技术扩展到了处理三维点云数据。这种扩展的三维全卷积网络技术被应用于处理激光雷达点云数据,通常用于自动驾驶车辆的目标检测任务。该研究通过在KITTI数据集上进行实验,验证了新方法的有效性。实验结果显示,与之前基于点云的检测方法相比,这种新方法的性能有了显著提高。
02
介绍
在研究中,作者设计了一个三维全卷积网络(FCN),用于从点云数据中检测和定位物体的三维边界框。之前的二维FCN在基于图像的物体检测任务中表现出了显著的性能,本文的方法将这一思想扩展到三维领域,并将其应用于自动驾驶系统的三维车辆检测,使用了Velodyne 64E激光雷达。同时,该方法还可以推广到其他目标检测任务,如基于Kinect捕获的点云数据、立体或单眼摄像头捕获的点云数据,以应用于不同的机器人和视觉感知应用。这项研究具有潜在的重要性,因为它扩展了点云数据的分析能力,可以为机器人系统提供更多的信息和功能。
03
相关工作
A.点云中的三维物体检测
大多数三维物体检测算法可以划分为两个主要阶段。首先是候选对象的提取,然后是对象的分类。候选对象可以通过多种方法提出,包括精细分割算法、滑动窗口、随机抽样或区域提议网络(RPN)等。在分类阶段,研究主要集中在不同的特征表示和分类方法上,包括形状模型和几何统计特征。这些方法用于确定候选对象的类别。稀疏编码和深度学习等技术也被用于提取和表示特征,以帮助分类过程。
B.卷积神经网络与三维目标检测
将三维信息嵌入到二维投影中,利用二维CNN进行识别或检测。在本文中,作者将全卷积网络(FCN)移植到三维中,以点云中三维盒子的形式检测和定位目标。FCN是最近流行的端到端目标检测框架,在包括ImageNet, KITTI, ICDAR等任务中具有顶级性能。FCN的变体包括DenseBox、YOLO和SSD。本文提出的方法受到了DenseBox基本思想的启发。
04
方法
A.FCN检测
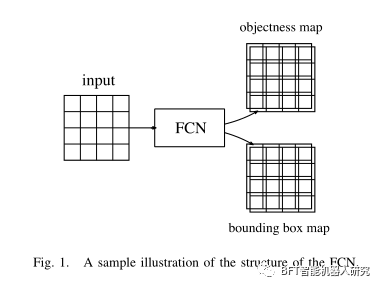
基于FCN检测框架的程序可以归纳为两项任务,即客观预测和边界框预测。如图1所示,FCN由两个对应于两个任务分别。对象映射预测一个区域是否属于一个对象和边界框映射预测对象边界框的坐标。表示区域p上的基真对象标记为' p。为简单起见,每个类对应一个标签。在某些作品中,例如SSD或DenseBox,网络可以一个类有多个对象标签,对应到多个尺度或长宽比。p处的客观损失记为
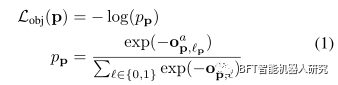
在本文中,我们假设只生成一个边界框图,尽管更复杂的网络可以为一个类预测多个边界框偏移,对应于多个比例尺或纵横比。每个边界框损失记为
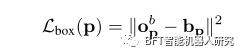
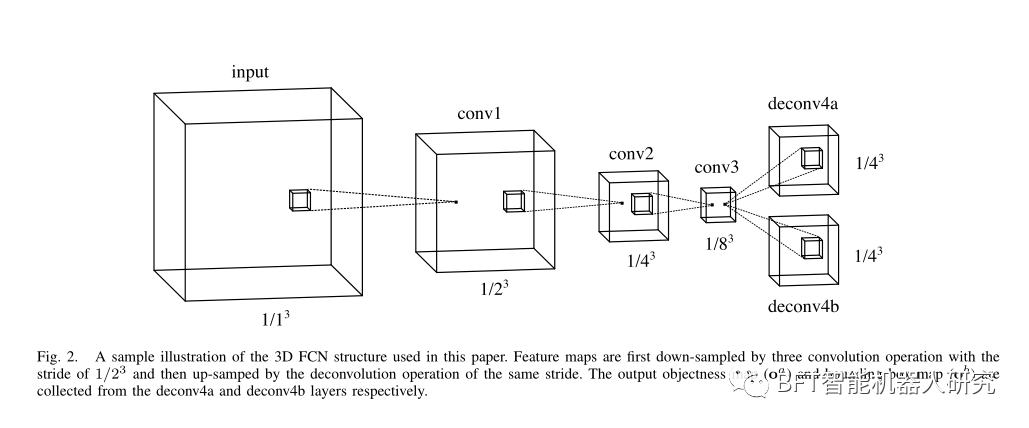
B.点云的三维FCN检测网络
将点云离散化在方形网格上。离散化后的数据可以用具有长、宽、高和通道维度的四维数组来表示。对于最简单的情况,仅使用一个值为{0,1}的通道来表示在相应的网格元素上是否有观测到的点。2D CNN的机制自然地在方形网格上扩展到3D。图2显示了本文中使用的网络结构的一个示例。该网络遵循并简化了沙漏形状。
C.与二维CNN的对比
与2D CNN相比,3D CNN的维数增加不可避免地会消耗更多的计算资源,主要原因是3D数据嵌入网格的内存成本和卷积3D核的计算成本增加。另一方面,在三维空间中自然嵌入物体可以避免二维情况下的透视失真和尺度变化。这使得使用相对简单的网络结构来学习检测成为可能。
05
实验
从KITTI基准对提出的3D CNN在车辆检测任务上进行评估。该任务包含与点云和物体信息对齐的图像,并由3D和2D边界框标记。为了简单起见,实验主要集中在Car类别的检测上。Car的3D中心球体内的区域被标记为正样本,即在V中,an和Truck被标记为忽略。行人、自行车和其他环境被标记为负背景,即P−V。
KITTI训练数据集包含7500+帧的数据,其中6000帧是随机选择用于实验训练的。其余1500帧用于离线验证,通过检测框在图像平面和地平面上与groundtruth的重叠来评估检测框。检测结果也在KITTI在线评估上进行比较,其中仅评估图像空间重叠。KITTI基准将对象样本分为三个难度等级。虽然这最初是为基于图像的检测而设计的,但我们发现这些难度等级也可以近似地用于3D检测和评估的难度划分。易等级的最小高度为40px,近似对应28m以内的目标;中、硬等级的最小高度为25px,近似对应47m以内的目标。
A.性能分析
作者基于图像平面上的边界框重叠和包围框在地平面上重叠这两个方面对朴素平均精度(AP)和平均方向相似度(AOS)进行了评估。
本文方法和[16]的性能如表1所示。与[16]相比,本文方法使用的层数和连接数更少,但检测精度更高。这主要是因为物体在三维嵌入中具有较小的尺度变化和遮挡。图4显示了更多的检测结果。检测结果如图三
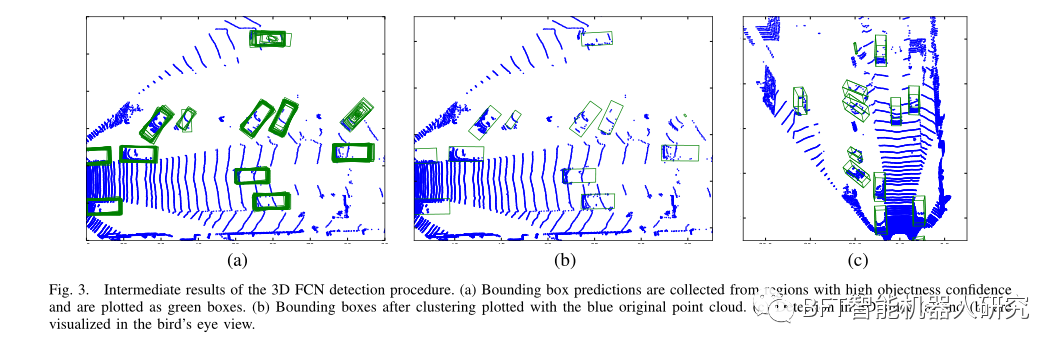
B.KITTI在线评估
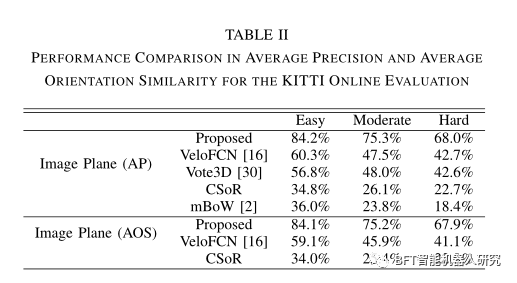
在KITTI在线系统上对该方法进行了评价。将本文提出的方法与以往基于点云的检测算法进行比较,结果如表2所示。我们的方法的性能比以前的方法有>20%的显著差距,这甚至可以与基于图像的算法相媲美。
06
总结
本文提出了首个用于端到端3D目标检测的3D FCN框架。这个框架代表了一种新的方法,可以显著提高点云数据中的目标检测性能。研究中的实验是在自动驾驶场景下使用Velodyne 64E激光雷达采集的点云数据上进行的。作者指出,这个框架不仅适用于这种传感器生成的点云,还可以应用于其他传感器或不同重构算法生成的点云数据。
END
作者 | 不加糖
排版 | 小河
审核 | 猫
若您对该文章内容有任何疑问,请与我们联系,我们将及时回应。
-
相关阅读:
dubbo学习之本地存根实践
jvm深入研究文档-探索虚拟机栈底层代码到底是如何实现的?--jvm底层探索(3)
增速波动!W「下」AR「上」!HUD前装供应商比拼硬核能力
mongodb数据库操作
【docker专栏6】详解docker容器状态转换管理命令
flutter系列之:在flutter中使用导航Navigator
2022年全球市场单线激光雷达总体规模、主要生产商、主要地区、产品和应用细分研究报告
利尔达蓝牙空调接收器方案助力打造更舒适的公路生活
(Spring笔记)AspectJ后置通知——@AfterReturning切面开发
linux centos出现No space left on device解决方案
- 原文地址:https://blog.csdn.net/Hinyeung2021/article/details/133883423