-
kubernetes Pod
kubernetes Pod
Why we need Kubernetes pod
Understanding why one container shouldn’t contain multiple processes
Imagine an application that consists of several processes that communicate with each other via IPC (Inter-Process Communication) or shared files, which requires them to run on the same computer. Each container is like an isolated computer or virtual machine. A computer typically runs several processes; containers can also do this. You can run all the processes that make up an application in just one container, but that makes the container very difficult to manage.
Containers are designed to run only a single process, not counting any child processes that it spawns. Both container tooling and Kubernetes were developed around this fact. For example, a process running in a container is expected to write its logs to standard output. Docker and Kubernetes commands that you use to display the logs only show what has been captured from this output. If a single process is running in the container, it’s the only writer, but if you run multiple processes in the container, they all write to the same output. Their logs are therefore intertwined, and it is difficult to tell which process each logged line belongs to.
Another indication that containers should only run a single process is the fact that the container runtime only restarts the container when the container’s root process dies. It doesn’t care about any child processes created by this root process. If it spawns child processes, it alone is responsible for keeping all these processes running.
To take full advantage of the features provided by the container runtime, you should consider running only one process in each container.
Pod can combine multiple containers
Since you shouldn’t run multiple processes in a single container, it’s evident you need another higher-level construct that allows you to run related processes together even when divided into multiple containers. These processes must be able to communicate with each other like processes in a normal computer. And that is why pods were introduced.
With a pod, you can run closely related processes together, giving them (almost) the same environment as if they were all running in a single container. These processes are somewhat isolated, but not completely - they share some resources. This gives you the best of both worlds. You can use all the features that containers offer, but also allow processes to work together. A pod makes these interconnected containers manageable as one unit.
What is Kubernetes Pod
Pods are the smallest deployable units of computing that you can create and manage in Kubernetes. All containers of a pod run on the same node. A pod never spans multiple nodes.
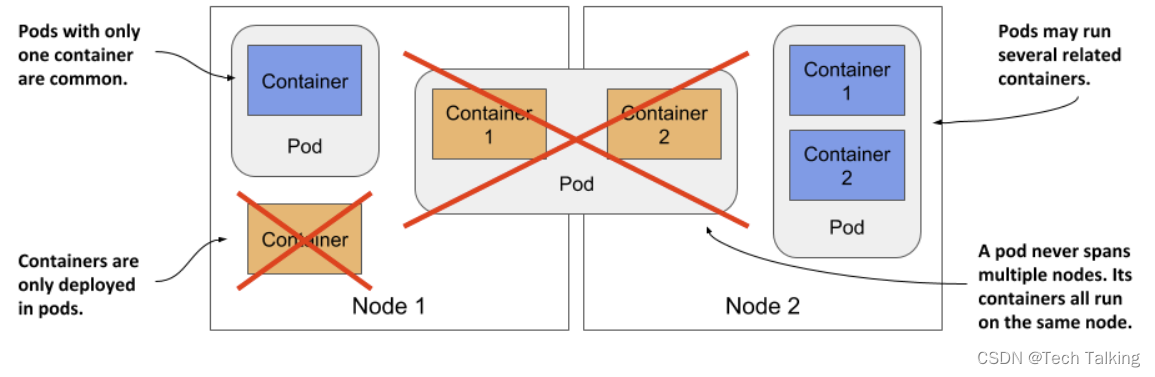
A Pod (as in a pod of whales or pea pod) is a group of one or more containers, with shared storage and network resources, and a specification for how to run the containers. A Pod’s contents are always co-located and co-scheduled, and run in a shared context. A Pod models an application-specific “logical host”: it contains one or more application containers which are relatively tightly coupled. In non-cloud contexts, applications executed on the same physical or virtual machine are analogous to cloud applications executed on the same logical host.
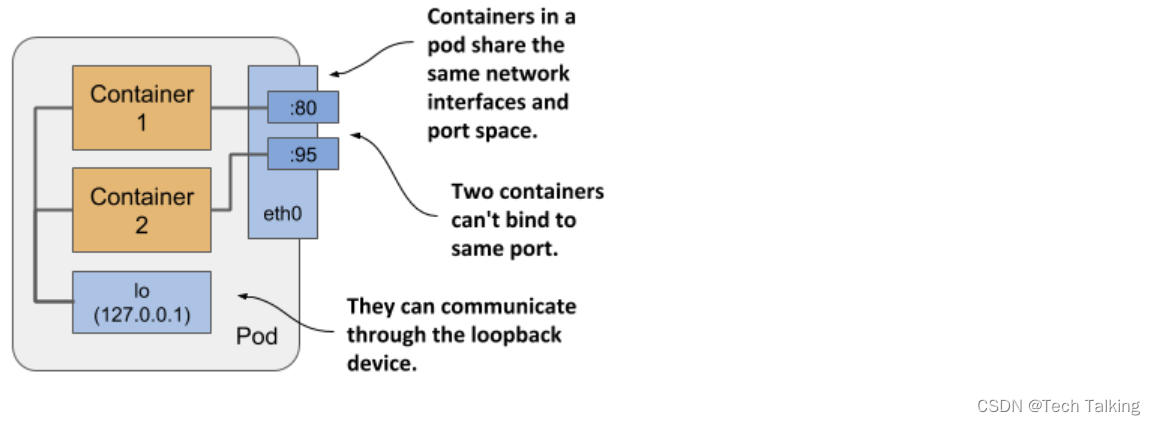
As shown in the above picture, all containers in a pod share the same Network namespace and thus the network interfaces, IP address(es) and port space that belong to it.
Because of the shared port space, processes running in containers of the same pod can’t be bound to the same port numbers, whereas processes in other pods have their own network interfaces and port spaces, eliminating port conflicts between different pods.
All the containers in a pod also see the same system hostname, because they share the UTS namespace, and can communicate through the usual IPC mechanisms because they share the IPC namespace. A pod can also be configured to use a single PID namespace for all its containers, which makes them share a single process tree, but you must explicitly enable this for each pod individually.
It’s this sharing of certain namespaces that gives the processes running in a pod the impression that they run together, even though they run in separate containers.
How to work with Kubernetes Pod
Create A pod with single container
You can think of each pod as a separate computer. Unlike virtual machines, which typically host multiple applications, you typically run only one application in each pod. You never need to combine multiple applications in a single pod, as pods have almost no resource overhead.
You can have as many pods as you need, so instead of stuffing all your applications into a single pod, you should divide them so that each pod runs only closely related application processes. The “one-container-per-Pod” model is the most common Kubernetes use case.
The following is an example of a Pod which consists of a container running the image kubia.
root@AlexRampUpVM-01:~# cat kubia-http.yaml apiVersion: v1 kind: Pod metadata: name: kubia-http spec: containers: - name: kubia image: luksa/kubia:1.0 ports: - name: http containerPort: 8080 root@AlexRampUpVM-01:~# kubectl apply -f kubia-http.yaml pod/kubia-http created root@AlexRampUpVM-01:~# kubectl get pod kubia-http NAME READY STATUS RESTARTS AGE kubia-http 1/1 Running 0 18s- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Each Pod is meant to run a single instance of a given application. If you want to scale your application horizontally (to provide more overall resources by running more instances), you should use multiple Pods, one for each instance. In Kubernetes, this is typically referred to as replication. Replicated Pods are usually created and managed as a group by a workload resource and its controller. We will discuss the replicaset controller in next chapter.
Create A pod with multiple containers
Placing several containers in a single pod is only appropriate if the application consists of a primary process and one or more processes that complement the operation of the primary process. The container in which the complementary process runs is called a sidecar container because it’s analogous to a motorcycle sidecar, which makes the motorcycle more stable and offers the possibility of carrying an additional passenger. But unlike motorcycles, a pod can have more than one sidecar.
It’s difficult to imagine what constitutes a complementary process, so I’ll give you some examples. In the previous section, you deployed pods with one container that runs a Node.js application. The Node.js application only supports the HTTP protocol. To make it support HTTPS, we could add a bit more JavaScript code, but we can also do it without changing the existing application at all - by adding an additional container to the pod – a reverse proxy that converts HTTPS traffic to HTTP and forwards it to the Node.js container. The Node.js container is thus the primary container, whereas the container running the proxy is the sidecar container. Figure 5.6 shows this example.
root@AlexRampUpVM-01:~# cat kubia-ssl.yaml apiVersion: v1 kind: Pod metadata: name: kubia-ssl spec: containers: - name: kubia image: luksa/kubia:1.0 ports: - name: http containerPort: 8080 - name: envoy image: luksa/kubia-ssl-proxy:1.0 ports: - name: https containerPort: 8443 - name: admin containerPort: 9901 root@AlexRampUpVM-01:~# kubectl apply -f kubia-ssl.yaml pod/kubia-ssl created- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
The name of this pod is kubia-ssl. It has two containers: kubia and envoy.
Kubernetes Pod States
After you create a pod object and it runs, you can see what’s going on with the pod by reading the pod object back from the API. The pod object manifest, as well as the manifests of most other kinds of objects, contain a section, which provides the status of the object. A pod’s status section contains the following information:
- the IP addresses of the pod and the worker node that hosts it
- when the pod was started
- the pod’s quality-of-service (QoS) class
- what phase the pod is in,
- the conditions of the pod, and
- the state of its individual containers.
The IP addresses and the start time don’t need any further explanation, and the QoS class isn’t relevant now - you’ll learn about it in later of this chapter. However, the phase and conditions of the pod, as well as the states of its containers are important for you to understand the pod lifecycle.
In any moment of the pod’s life, it’s in one of the five phases shown in the following figure.
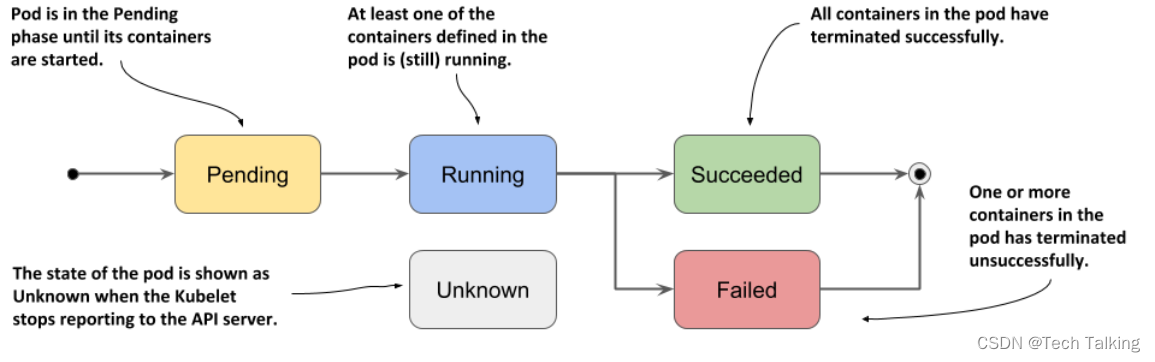
Pod Phase Description Pending After you create the Pod object, this is its initial phase. Until the pod is scheduled to a node and the images of its containers are pulled and started, it remains in this phase. Running At least one of the pod’s containers is running. Succeeded Pods that aren’t intended to run indefinitely are marked as Succeeded when all their containers complete successfully. Failed When a pod is not configured to run indefinitely and at least one of its containers terminates unsuccessfully, the pod is marked as Failed. Unknown The state of the pod is unknown because the Kubelet has stopped reporting communicating with the API server. Possibly the worker node has failed or has disconnected from the network. Displaying a pod’s phase
The pod’s phase is one of the fields in the pod object’s status section. You can see it by displaying its manifest and optionally grepping the output to search for the field:
root@AlexRampUpVM-01:~# kubectl get pod kubia-http -o yaml |grep phase phase: Running- 1
- 2
If the pod phase is not running, just go through the following part to learn how to interact with the pod and check the pod logs.
Interacting with the Pod
Your container is now running. In this section, you’ll learn how to communicate with the application, inspect its logs, and execute commands in the container to explore the application’s environment. Let’s confirm that the application running in the container responds to your requests.
Get Pod IP
root@AlexRampUpVM-01:~# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kubia-ssl 2/2 Running 0 5s 10.243.0.45 aks-usernodepool-33612472-vmss000003kubia-http 1/1 Running 0 44s 10.243.0.14 aks-usernodepool-33612472-vmss000003 - 1
- 2
- 3
- 4
As indicated in the IP column, kubia-ssl pod’s IP is 10.243.0.45. Now I need to determine the port number the application is listening on.
Executing commands in running containers
When debugging an application running in a container, it may be necessary to examine the container and its environment from the inside. Kubectl provides this functionality, too. You can execute any binary file present in the container’s file system using the kubectl exec command. We will take bash shell as an example. The
-itoption attaches your console to the container’s standard input and output.kubectl exec -ti kubia-http bash- 1
If your pod has multiple containers and you’d like to run a command in one of the pod’s containers using the kubectl exec command, you also specify the container name using the
--containeror-coption. For example, to run a shell inside the envoy container, run the following command:root@AlexRampUpVM-01:~# kubectl exec -it kubia-ssl -c envoy -- bash root@kubia-ssl:/#- 1
- 2
Connecting to the pod from another Pod
One way to test the connectivity of your application is to run
curlin another pod that you create specifically for this task. To run curl in a pod, use the following command:root@AlexRampUpVM-01:~# kubectl exec -ti kubia-http bash kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead. root@kubia-http:/# root@kubia-http:/# curl http://10.243.0.45:8080 Hey there, this is kubia-ssl. Your IP is ::ffff:10.243.0.49. root@kubia-http:/# root@kubia-http:/# curl -k https://10.243.0.45:8443 Hey there, this is kubia-ssl. Your IP is ::ffff:127.0.0.1.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Checking the container logs
To view the log of your pod (more specifically, the container’s log), run the command shown in the following listing on your local computer:
kubectl logs-n - 1
For example,
root@AlexRampUpVM-01:~# kubectl logs kubia-http -n default Kubia server starting... Local hostname is kubia-http Listening on port 8080- 1
- 2
- 3
- 4
The above example is for the pod with single container. But the kubia-ssl pod contains two containers, so if you want to display the logs, you must specify the name of the container using the
--containeror-coption. For example, to view the logs of the kubia container, run the following command:kubectl logs kubia-ssl -c kubia- 1
The Envoy proxy runs in the container named envoy, so you display its logs as follows:
kubectl logs kubia-ssl -c envoy- 1
Alternatively, you can display the logs of both containers with the --all-containers option:
kubectl logs kubia-ssl --all-containers- 1
Deleting kubernetes Pod
The easiest way to delete an object is to delete it by name. Use the following command to remove the kubia pod from your cluster:
root@AlexRampUpVM-01:~# kubectl delete pod kubia-ssl pod "kubia-ssl" deleted- 1
- 2
By deleting a pod, you state that you no longer want the pod or its containers to exist. The Kubelet shuts down the pod’s containers, removes all associated resources, such as log files, and notifies the API server after this process is complete. The Pod object is then removed.
Deleting multiple pods with a single command
You can also delete multiple pods with a single command. If you ran the kubia-init and the kubia-init-slow pods, you can delete them both by specifying their names separated by a space, as follows:
kubectl delete pod kubia-init kubia-init-slow pod "kubia-init" deleted pod "kubia-init-slow" deleted- 1
- 2
- 3
Deleting all pods with a single command
Instead of deleting these pods by name, we can delete them all using the
--alloption:kubectl delete pod --all- 1
-
相关阅读:
iptables 之 state模块(ftp服务练习)
NFT入门:部署示例等
SpringBoot+Minio实现上传凭证、分片上传、秒传和断点续传
webpack前端性能优化的操作有哪些?
笔算开2次方根、3次方根详细教程
【SA8295P 源码分析 (一)】54 - /ifs/bin/startupmgr 程序工作流程分析 及 script.c 介绍
什么是应用性能管理(APM)
jquery的隐藏和显示
Hugging News #0428: HuggingChat 来啦
Python的collections包中的双端队列deque
- 原文地址:https://blog.csdn.net/mukouping82/article/details/133910211
