-
数据库如何储存和管理数据的?
前言:众所周知,数据库就是一个将各类数据,以表格的形式存储的,但是看似如此简单的功能它是真的简单吗?我们和直接使用简单的Excel建立的表格有区别吗?如果有在哪里?
PS:本文以常用的MySQL为例
磁盘IO
在不考虑缓存等机制(数据IO)的前提下,首先我们知道,对于用户来说他使用数据时,会和其内部的存储设备,一般为磁盘(当然也有固态之类的更高效的存储设备,但是数据库一般是部署在服务端,而服务端的主机或集群,考虑安全、可靠和成本等问题一般是使用磁盘),交互寻找和提取对应的数据.
找了一篇写的不错的磁盘IO文章:一提到mysql,总有人说磁盘IO,到底什么是磁盘IO?-CSDN博客
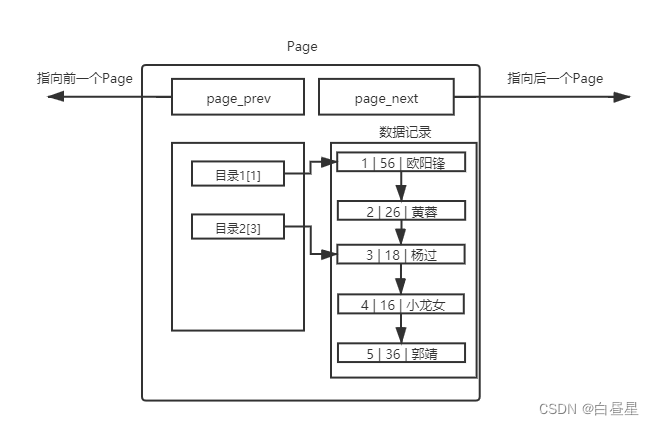
在浅浅的了解了磁盘IO后我们大概有如下认知:
- MySQL 中的数据文件,是以page为单位保存在磁盘当中的。
- MySQL 的 CURD 操作,都需要通过计算,找到对应的插入位置,或者找到对应要修改或者查询的数据。
- 而只要涉及计算,就需要CPU参与,而为了便于CPU参与,一定要能够先将数据移动到内存当中。
- 所以在特定时间内,数据一定是磁盘中有,内存中也有。后续操作完内存数据之后,以特定的刷新策略,刷新到磁盘。而这时,就涉及到磁盘和内存的数据交互,也就是IO了。而此时IO的基本单位就是Page。
- 为了更好的进行上面的操作, MySQL 服务器在内存中运行的时候,在服务器内部,就申请了被称为 Buffer Pool 的的大内存空间,来进行各种缓存。其实就是很大的内存空间,来和磁盘数据进行IO交互。
- 为何更高的效率,一定要尽可能的减少系统和磁盘IO的次数
数据的存储
现在我们知道了数据库是数据文件的,但是又有一个新问题,那他是如何管理这些不同的page的呢?
-
链表?线性遍历
-
二叉搜索树?退化问题,可能退化成为线性结构
-
AVL &&红黑树?虽然是平衡或者近似平衡,但是毕竟是二叉结构,意味着系统与硬盘更少的IO Page交互。能把树的高度想办法再压缩一点吗?
-
Hash?官方的索引实现方式中, MySQL 是支持HASH的,不过 InnoDB 和 MyISAM 并不支持.Hash跟进其算法特征,决定了虽然有时候也很快(O(1)),不过,在面对范围查找就明显不行(哈希无序),当然如果使用的话也不是不行.
-
B树?
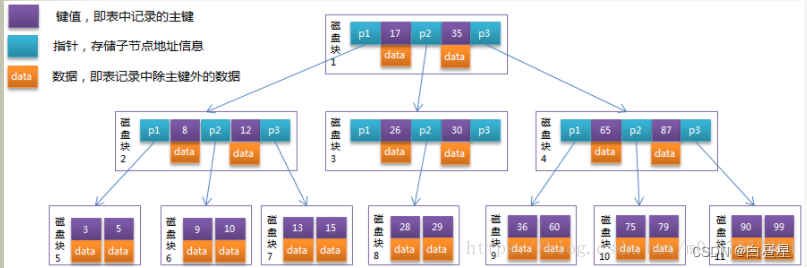
- B树看起来还可以但是如果在跨越了多个叶子节点的话,我们要连续的的查的话,就需要回到父节点再到下一个节点,IO次数多了(叶子节点不相连)
- 而且B树是每个节点都储存了数据,使得单个节点能储存的key少了,我们能不能极端一点,把数据都放在叶子上,把让出的空间放更多的目录呢?.
- 最终我们选择了它B+树
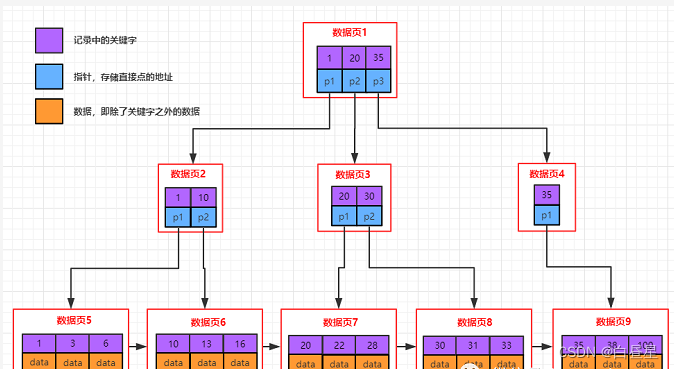
小结
- Page分为目录页和数据页。目录页只放各个下级Page的最小键值。
- 查找的时候,自定向下找,只需要加载部分目录页到内存,即可完成算法的整个查找过程,**大大减少了IO次数 **。
下图为常见的存储引擎底层所使用的储存的数据结构

特别的
MyISAM 存储引擎-主键索引
MyISAM 引擎同样使用B+树作为索引结果,叶节点的data域存放的是数据记录的地址。下图为 MyISAM表的主索引, Col1 为主键。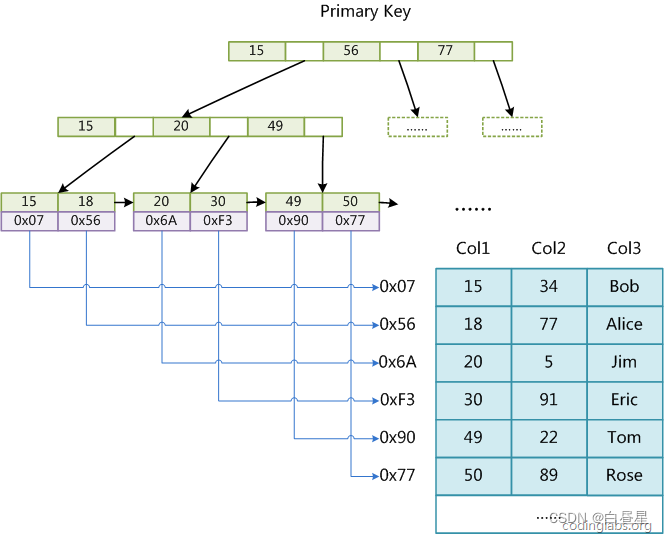
其中, MyISAM 最大的特点是,将索引Page和数据Page分离,也就是叶子节点没有数据,只有对应数据的地址。
相较于 InnoDB 索引, InnoDB 是将索引和数据放在一起的。其中, InnoDB 这种用户数据与索引数据在一起索引方案,叫做聚簇索引
当然, MySQL 除了默认会建立主键索引外,我们用户也有可能建立按照其他列信息建立的索引,一般这种索引可以叫做辅助(普通)索引。
对于 MyISAM ,建立辅助(普通)索引和主键索引没有差别,无非就是主键不能重复,而非主键可重复。
下图就是基于 MyISAM 的 Col2 建立的索引,和主键索引没有差别 .立辅助(普通)索引和主键索引没有差别,无非就是主键不能重复,而非主键可重复。
下图就是基于 MyISAM 的 Col2 建立的索引,和主键索引没有差别 . -
相关阅读:
入门力扣自学笔记203 C++ (题目编号:878)
NoC流量控制
18.ROS编程:ROS中的时间c++
【分享】从Mybatis源码中,学习到的10种设计模式
回文字符串与动态规划
Android笔记(九):Compose组件的状态(一)
汇凯金业:黄金5g工艺是什么意思
【力扣每日一题】2023.9.15 宝石补给
在byrut下载过游戏的可能会中挖矿病毒导致常见杀软无法安装
全志V3S嵌入式驱动开发(开发环境再升级)
- 原文地址:https://blog.csdn.net/qq_68140277/article/details/133887143