-
Linux入门---页表的理解
第一次认识页表
我们第一次认识页表是在介绍地址空间的时候,我们知道操作系统将内存划分为好几个区域,比如说栈区,堆区,未初始化区,已初始化区,代码区,每个区的大小不同所对应的功能也不同,并且在内存中每个字节大小的空间都有一个属于自己的地址,通过这个地址我们就可以访问到内存中具体某个位置所记载的内容,地址从0x00000000开始一直到0xFFFFFFFF结束所以在内存中又有高地址和低地址之分,那么我们就可以简单的画出一个内存的图片出来:
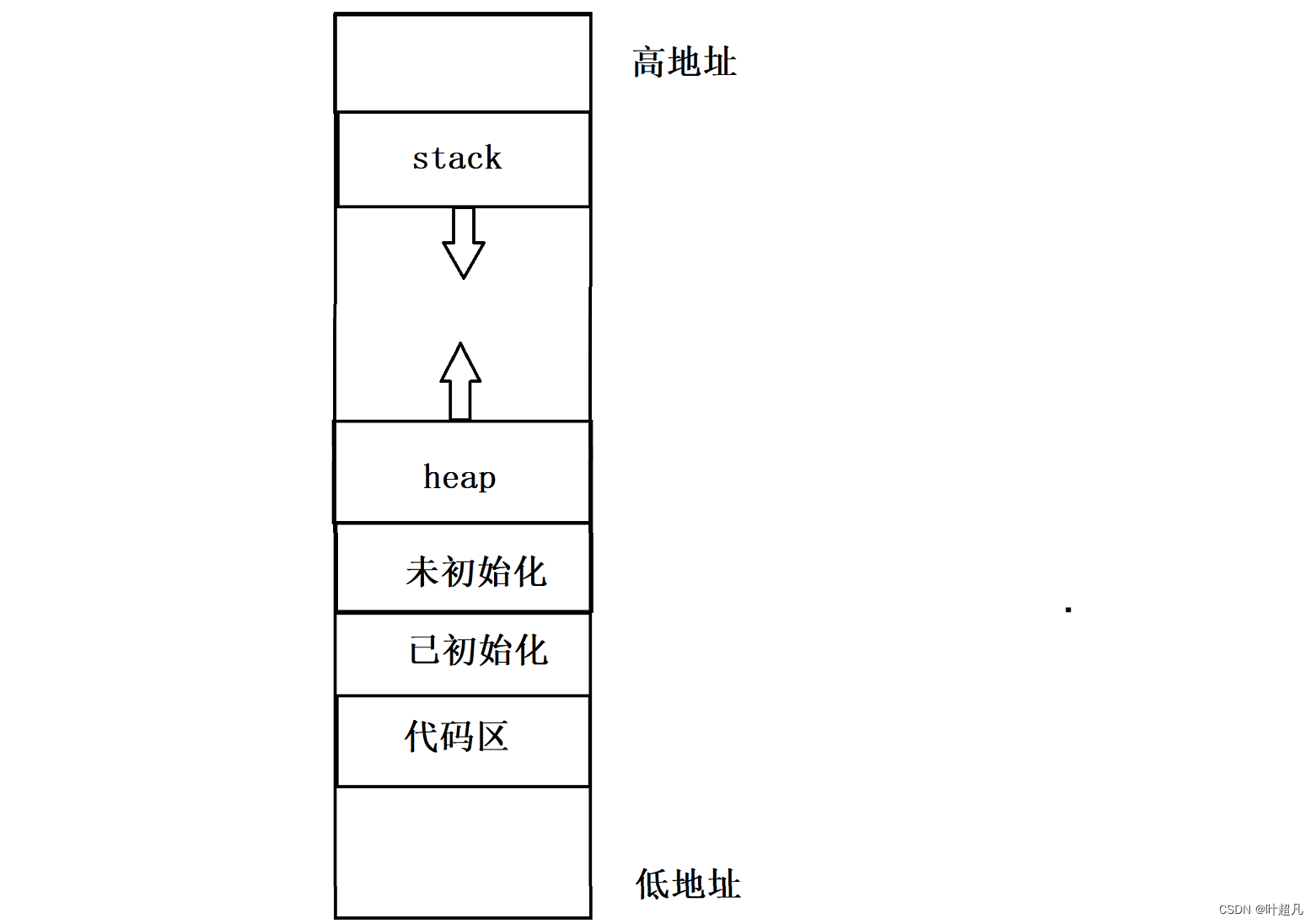
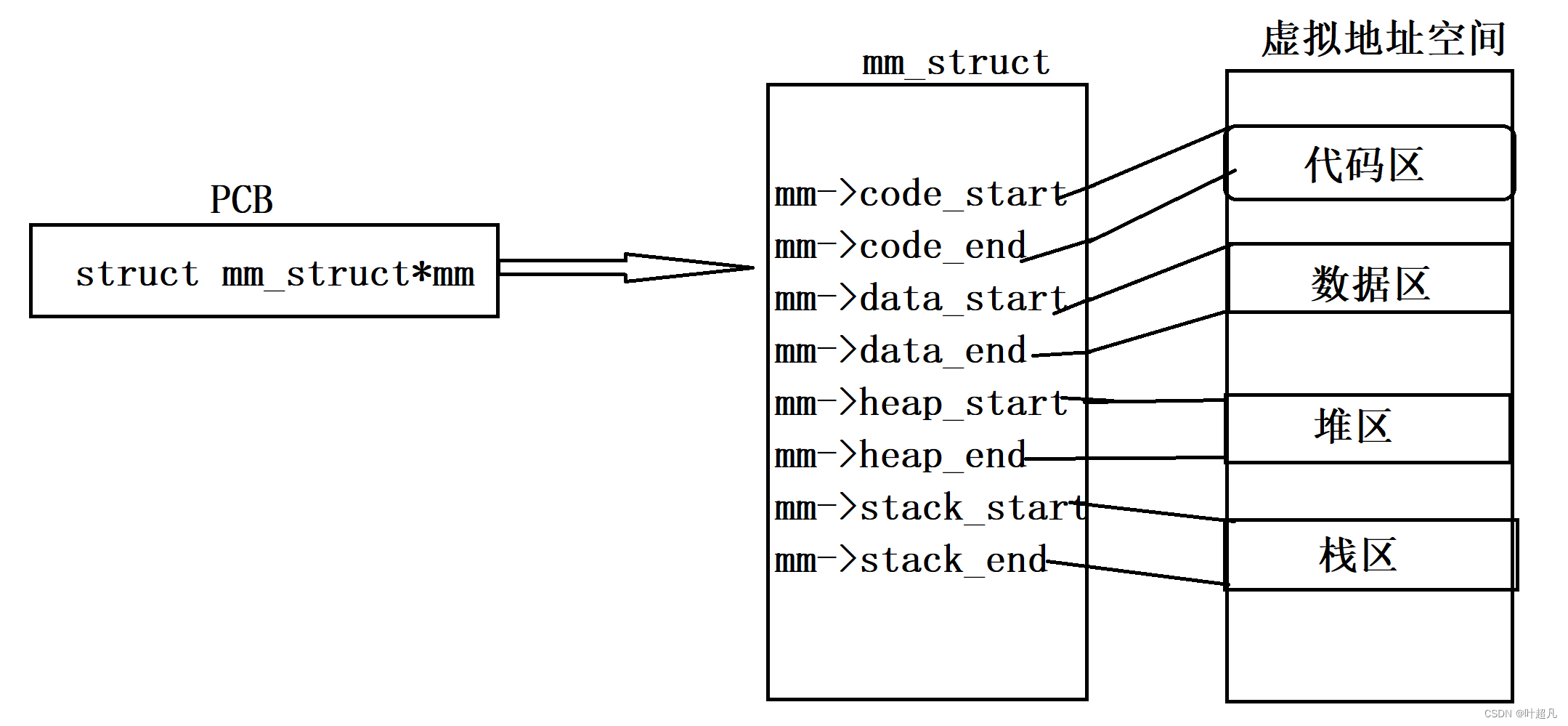
那么这就是我们之前学的内存地址空间的分布,我们平时写的程序和程序在运行的过程中产生的数据就会存放在内存上面,但是我们能向内存上申请非常大的一块数据吗?内存上的每个地址都能被访问被修改吗?答案是肯定不行的因为内存在计算机的组成中有着很大的作用,如果我们向内存申请了很多的空间但是却不对该空间进行使用的话是不是就照成了空间的浪费了呢?你一个进程申请了那么多的空间但是整个计算机中并不只有你一个进程在运行啊!你把内存都申请完了,那其他的进程该怎么存储数据呢?同样的道理进程不能够访问内存上的所以地址上的内容,因为在操作系统中,有些内存空间是被保护的,只有特权级别高的程序才能访问。这些被保护的内存空间包括操作系统的内核空间、硬件设备的映射空间等,既然不是所有的地址都能被访问那就跟不要谈的地址上的所有内容能被修改了,如果内存地址上的内容都能被修改的话,那就很难保护内存上的重要数据被恶意程序修改,所以内存是一个很脆弱的东西,如果将内存直接暴露给用户使用的话就很容易出现问题,出现问题的原因就是用户违规申请,违规使用,违规访问了,但是要想让每个用户都按规范几乎不可能,而且内存上的数据一旦被修改了就很难恢复了,所以我们只能对内存进行保护,那如何保护呢?答案就是迷惑进程我们创建一个名为mm_struct的数据结构struct mm_struct { uint32_t code_start,code_end; uint32_t date_start,date_end; uint32_t heap_start,heap_end; uint32_t stack_start,stack_end; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
这个数据结构可以维护一个跟内存一摸一样的虚拟内存,我们把这个虚拟内存称之为虚拟地址空间,操作系统每创建一个进程的时候都会给该进程分配一个该数据结构对象,因为维护出来的虚拟地址空间跟内存看起来一摸一样,所以进程申请,访问,修改内存的数据时就可以无缝扭转的对虚拟地址进行操作,这样即使有一些违规的操作也不会伤害物理内存而是伤害虚拟内存,
但是玩归玩闹归闹不拿虚拟地址空间的生命开玩笑,虽然虚拟地址空间上不会跟内存记录一样的数据,但是当访问出现问题的时候我们还是得知道的,比如说申请很多的空间,内存肯定是不会给的,但是虚拟地址空间可以给啊,他修改一下内部变量的值就可以了,至于这块空间你用不用用多少最后虚拟内存再根据你的真实情况才会向物理内存申请合适的空间,再比如说修改内存上的值,进程得先访问虚拟内存然后再修改内存上的值,如果虚拟内存在映射到物理内存的过程中发现有问题就会停止本次的访问和修改,那么这就是虚拟内存的好处,他可以保护物理内存,但是光光一个虚拟地址空间还是不够的,我们上面说虚拟地址空间要映射到物理内存上去,物理内存和虚拟内存是有很强的关联的,那么要维持这个关联要完成虚拟内存到物理内存上的映射靠的就是页表:
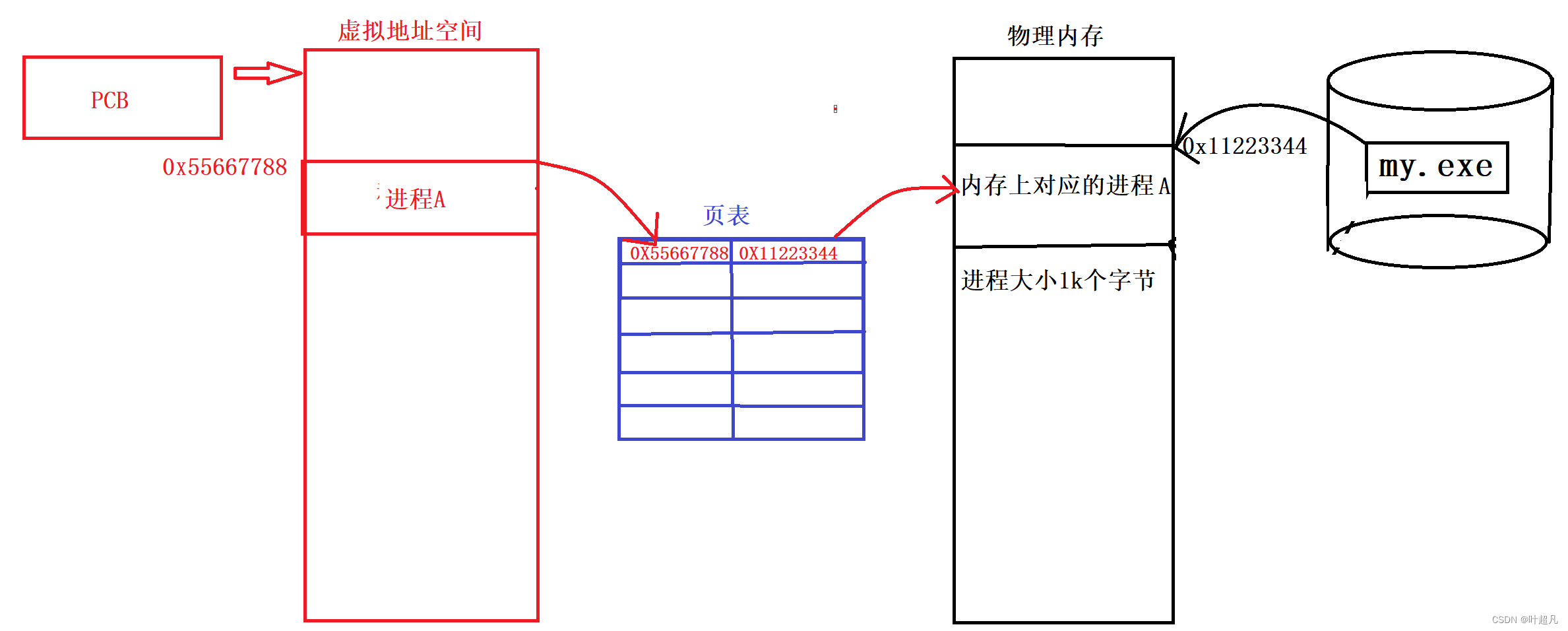
所以通过这里我们就知道虚拟地址空间上是通过页表转换到物理内存上的地址,当出现违规访问和修改的时候页表在转换的过程中将其拦截下来,那么这就是我们第一认识的页表,他只有一个映射地址空间和检查空间的访问和修改是否合理的功能。第二次认识页表
我们第二次认识页表是在学习信号的时候,我们说操作系统会在合适的时间检查是否收到了信号,也就是检查pending表和block表里面值,判断是否需要处理,如果需要处理就在handler表上查找对应的方法,那么这里就有个问题:什么是合适的时候?答案是从内核态转换到用户态的时候就会检查一下那三张表的内容,因为那三张表属于操作系统管理的内容,作为用户身份的我们是没有能力查看三张表的内容的,所以得将当前的身份转换成为内核态,又因为将身份从用户态转到内核态换会消耗一些资源所以从每次从内核态转换到用户态的时候操作系统都会想来都来了要不再消耗点资源检查一下是否有信号要被处理吧,所以从内核态转换到用户态的时候都会检查一下那三个表,既然我们知道了内核态转换到用户态会检查一下三张表,那么什么时候从用户态转换到内核态呢?那么这就跟我们写的程序有关,我们在写程序的时候难免会访问到操作系统的资源(getpid,waitpid)和硬件资源(printf,read,write),当我们访问操作系统的资源或者硬件资源的时候,我们都得直接或者间接的访问系统提供的借口,通过这些接口来访问操作系统的资源,我们把这些接口称为系统调用
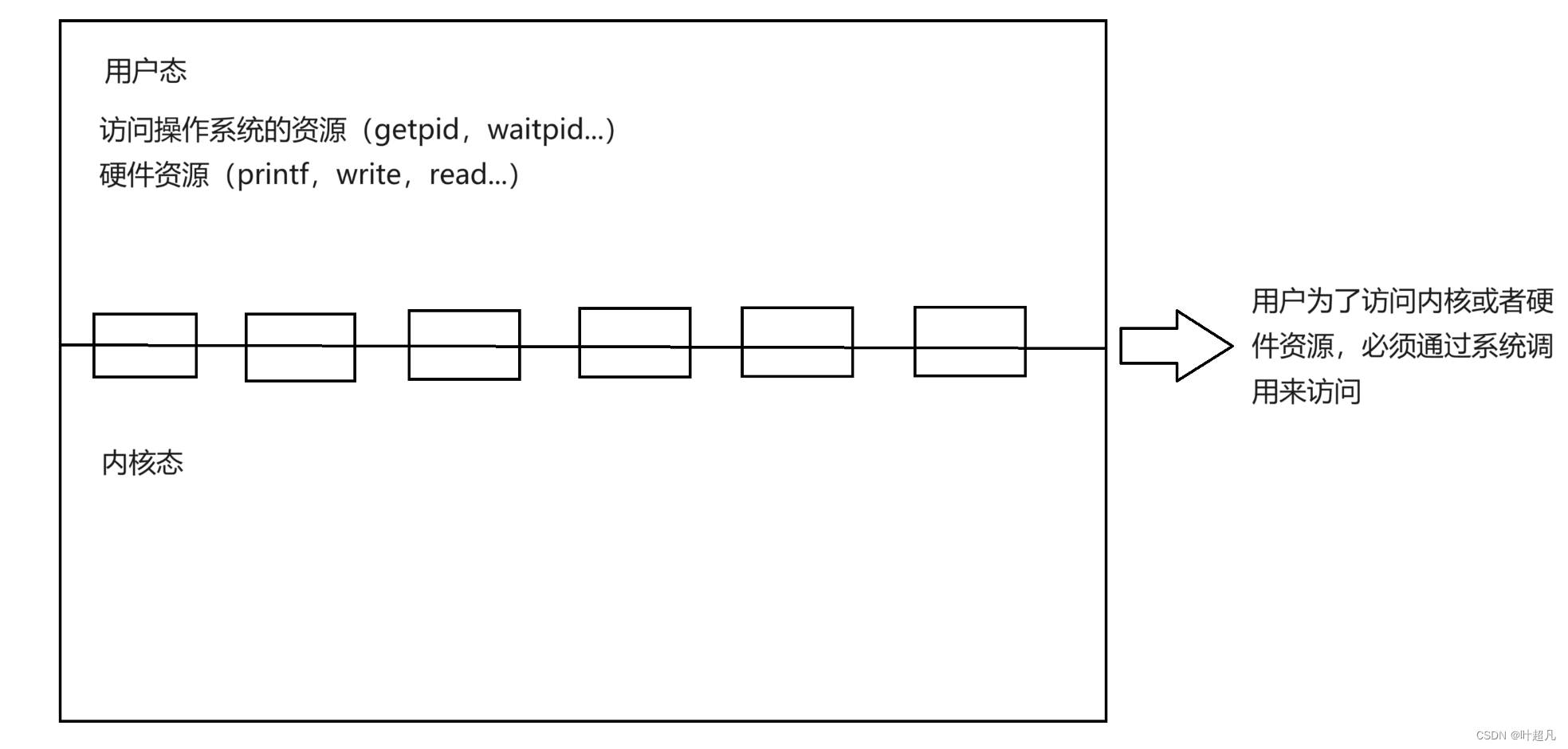
虽然将其称之为接口,但是这些接口本质上还是函数,既然是函数就有内容,有内容就要被执行,那么在执行这些函数内容的时候必须得以内核态的身份来执行:
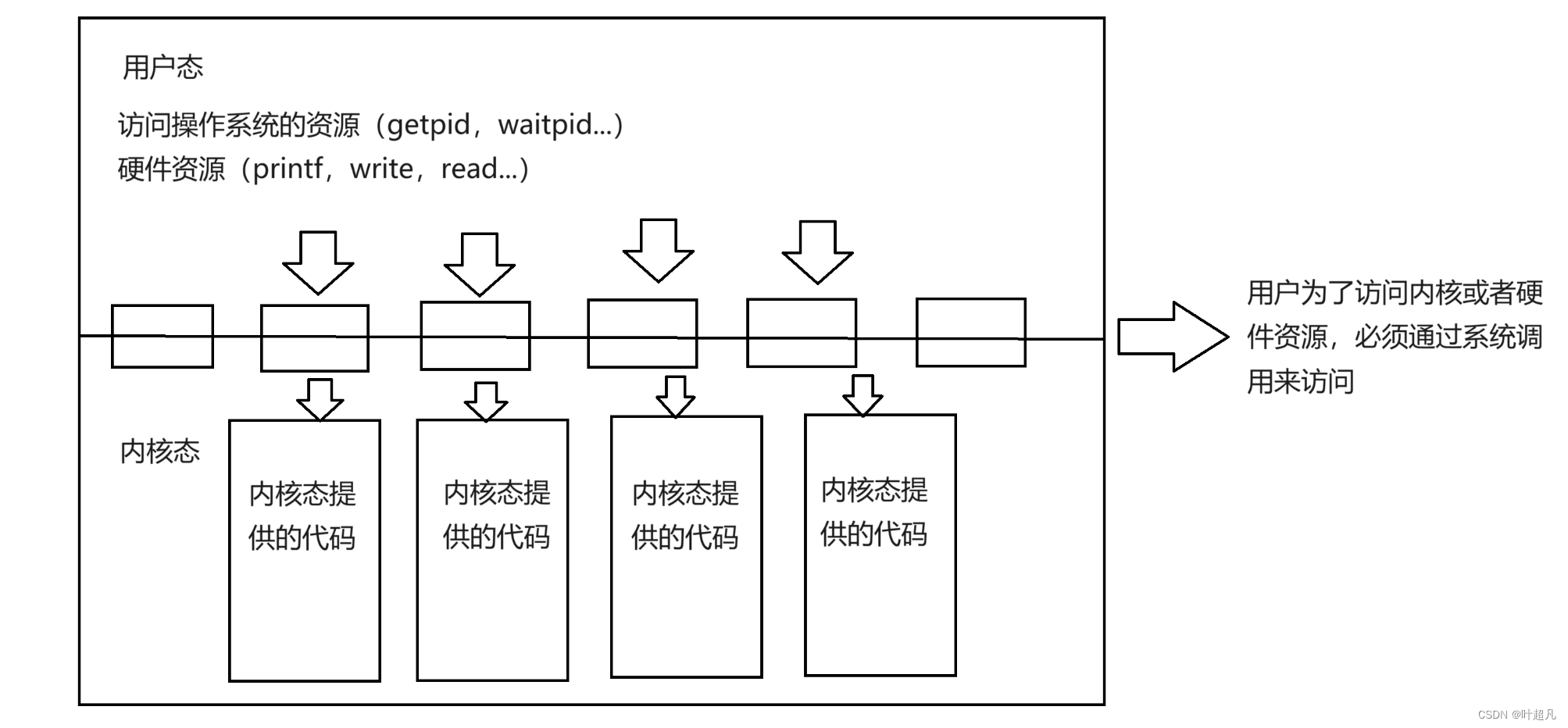 所以在执行系统调用访问硬件资源操作系统资源的时候就会将身份从用户态转换到内核态然后执行对应系统调用的代码,这些代码一定是在开机的时候由硬盘加载进内存里面,然后进程在访问的时候也是先通过虚拟地址空间加上页表来访问对应在内存上的系统调用代码,但是这里就存在一个问题我们知道操作系统的代码通常是在内存中的固定位置,这是因为操作系统需要在启动时加载到内存中,并且需要一直运行,因此需要一个固定的位置来存储它的代码和数据,在一些嵌入式系统中,操作系统的代码可能会被编译成只读存储器(ROM)中,以确保其不会被修改,也就是说在内存上操作系统的代码是固定的,并且一般情况下,操作系统有关的代码在不同进程的虚拟地址空间上是相同位置的。这是因为操作系统内核代码是共享的,每个进程都有自己的虚拟地址空间,但是内核代码在所有进程中都是相同的,因此它们在不同进程的虚拟地址空间上的位置是相同的。这也是为什么操作系统可以在不同进程之间共享内存的原因之一,那么这就说明操作系统的代码在内存和虚拟地址空间上的位置都是固定的,而我们之前说操作系统每创建一个进程的时候都会创建对应的页表来完成映射,也就说操作系统如果有10个进程那么就会有10个页表,但是操作系统对应的代码不管是在内存上还是在虚拟地址空间上都是固定的啊,每个进程都可以访问这部分的代码,那创建多个页表来完成这部分的转换是不是有点多余啊对吧,我们只创建一个页表然后所有的进程共用这个页表不就可以了吗?所以我们之前讲的页表是用户级页表用来完成0~3GB的地址空间到内存的转换,然后内存还剩下的4-4GB的空间就靠内核级页表来进行映射,因为页表两侧的地址都是固定的,所以内核级页表就只有一个:
所以在执行系统调用访问硬件资源操作系统资源的时候就会将身份从用户态转换到内核态然后执行对应系统调用的代码,这些代码一定是在开机的时候由硬盘加载进内存里面,然后进程在访问的时候也是先通过虚拟地址空间加上页表来访问对应在内存上的系统调用代码,但是这里就存在一个问题我们知道操作系统的代码通常是在内存中的固定位置,这是因为操作系统需要在启动时加载到内存中,并且需要一直运行,因此需要一个固定的位置来存储它的代码和数据,在一些嵌入式系统中,操作系统的代码可能会被编译成只读存储器(ROM)中,以确保其不会被修改,也就是说在内存上操作系统的代码是固定的,并且一般情况下,操作系统有关的代码在不同进程的虚拟地址空间上是相同位置的。这是因为操作系统内核代码是共享的,每个进程都有自己的虚拟地址空间,但是内核代码在所有进程中都是相同的,因此它们在不同进程的虚拟地址空间上的位置是相同的。这也是为什么操作系统可以在不同进程之间共享内存的原因之一,那么这就说明操作系统的代码在内存和虚拟地址空间上的位置都是固定的,而我们之前说操作系统每创建一个进程的时候都会创建对应的页表来完成映射,也就说操作系统如果有10个进程那么就会有10个页表,但是操作系统对应的代码不管是在内存上还是在虚拟地址空间上都是固定的啊,每个进程都可以访问这部分的代码,那创建多个页表来完成这部分的转换是不是有点多余啊对吧,我们只创建一个页表然后所有的进程共用这个页表不就可以了吗?所以我们之前讲的页表是用户级页表用来完成0~3GB的地址空间到内存的转换,然后内存还剩下的4-4GB的空间就靠内核级页表来进行映射,因为页表两侧的地址都是固定的,所以内核级页表就只有一个:
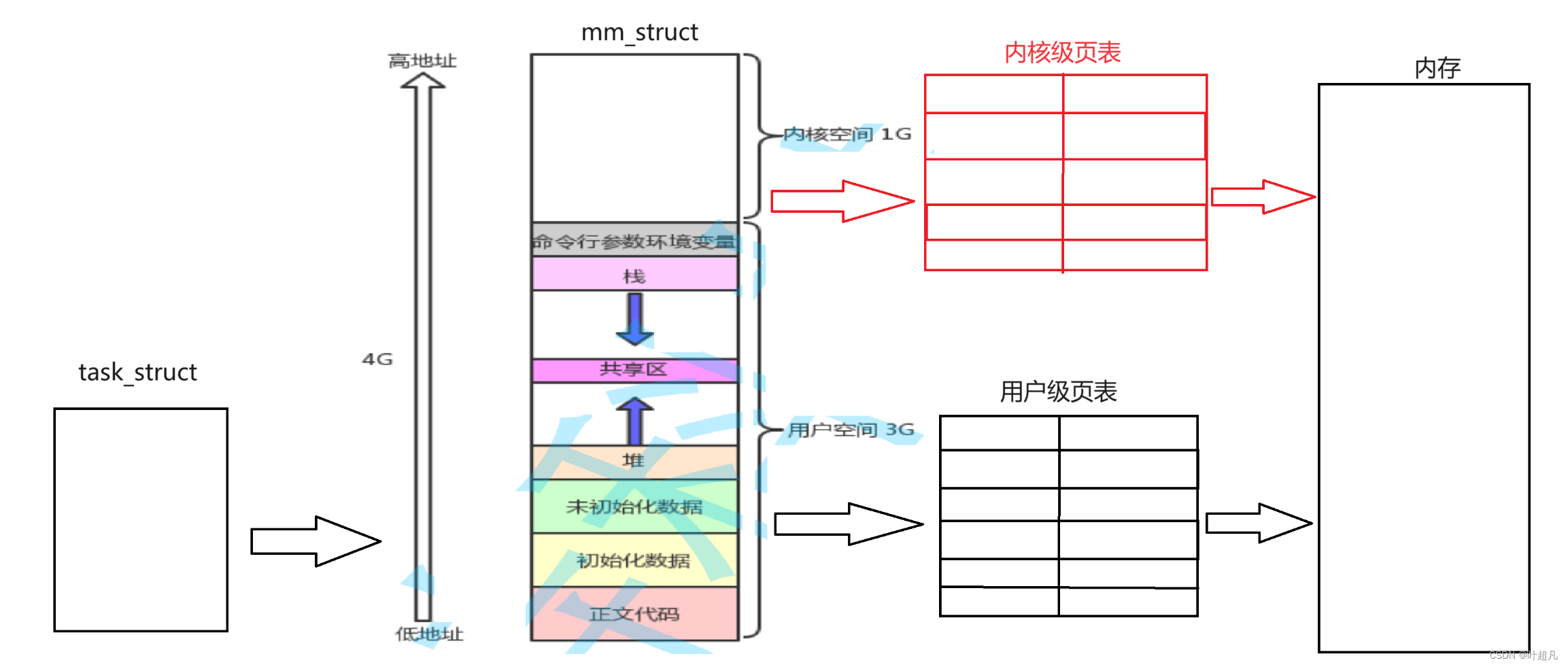
那么这就是我们第二次认识的页表。如何看待页表
在c语言中str="hello world"运行的时候是不会报错的,比如说下面的代码:
#includeint main() { char* s = "abc"; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
代码的运行结果如下:

但是使用*str="world hello"就会报错:
#includeint main() { char* s = "abc"; *s = 'a'; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
加上const并修改的话也是会报错的但是这个报错是语言上的报错并不是系统上的报错,之所以出现这样的原因是因为常量区位于已初始化数据和代码区之间,这部分区域的数据是不允许被修改的,那操作系统是怎么知道我们要对这部分的数据进行修改的呢?答案是通过页表来得知的,页表包含几个部分:物理地址,是否命中,rwx权限,U/K权限
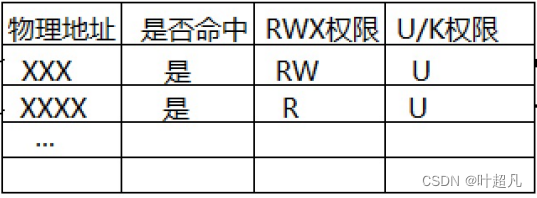
当对地址解引用的时候虚拟地址会映射到物理地址,然后页表中就会记录这个地址的RWX权限,常量区中的权限是没有W的但是刚刚的操作是W操作,所以当页表就发现执行行为出现了异常,mmu就会对当前的操作进行终止,终止的方式就是硬件报错,然后操作系统再将报错直接转换称为信号发送给进程,进程就会处理这个信号并退出,U/K就表示访问当前区域的权限,当进程访问某个区域的时候操作系统就会根据页表来判断当前的cpu的运行级别是是内核级别还是用户级别,内核级别才能访问带K的,用户级别只能访问U的,看到了这里想必大家能够更加的理解页表的功能,那我们应该如何看待页表呢?
1:地址空间是进程能看到的资源窗口。
2.:页表决定进程真正拥有的资源亲况。
3:合理的对地址空间+页表进行资源划分,我们就可以对一个进程的所有资源进行分类,地址空间划分为哪些区域,页表再将不同的区域映射到内存的不同的区域。页表的大致构成
地址空间存在2^32个地址,如果页表要对应内存上的每个地址的话那与之对应的页表中就应该存在2^32个条目来进行映射,假设每个条目的类型为6个字节,那么这样的话光一个页表就需要24GB的空间,这还只是一个页表如果存在多个页表的话大小将不敢想象,所以我们之前的对页表的理解是不正确的,虚拟地址有32个比特位,而操作系统为了方便管理物理内存,将物理内存分为一个一个的数据块(也可以称之为数据页),因为操作系统要对物理内存进行管理,管理的方式也是先描述再组织,所以有一个名为page的结构体,这个结构体里面包含有内存的属性(大小很小),这些属性就管理这4KB大小的内存,在操作系统中我们就把这样4KB的大小的物理内存称为页框,那么操作系统要想管理物理内存就只需要管理page结构体就行,这样操作系统就知道内存哪些地方被使用了,哪些地方没有被使用,所以操作系统就采用一个名为伙伴系统的管理算法来管理着物理内存,其次磁盘在编译生成对应的可执行程序的时候,其实也是被划分称为一个一个4KB的数据块的,那么我们把磁盘中的一个一个4KB数据就称为页帧,那么将磁盘的数据搬到内存中时不是一个字节一个字节的搬而是4KB的4KB的搬,虚拟地址有32个比特位,那么我们把32个比特位分为10 10 12
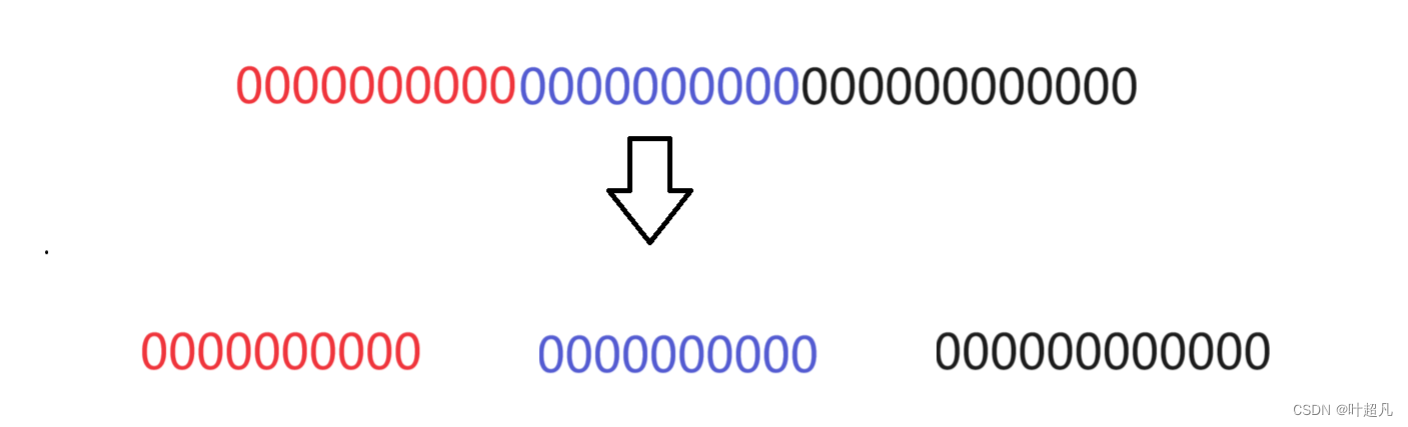
而且页表不只有一张页表,第一个页表称为页目录这个目录里面存放着2^10个索引也就对应着虚拟地址的前10个比特位:
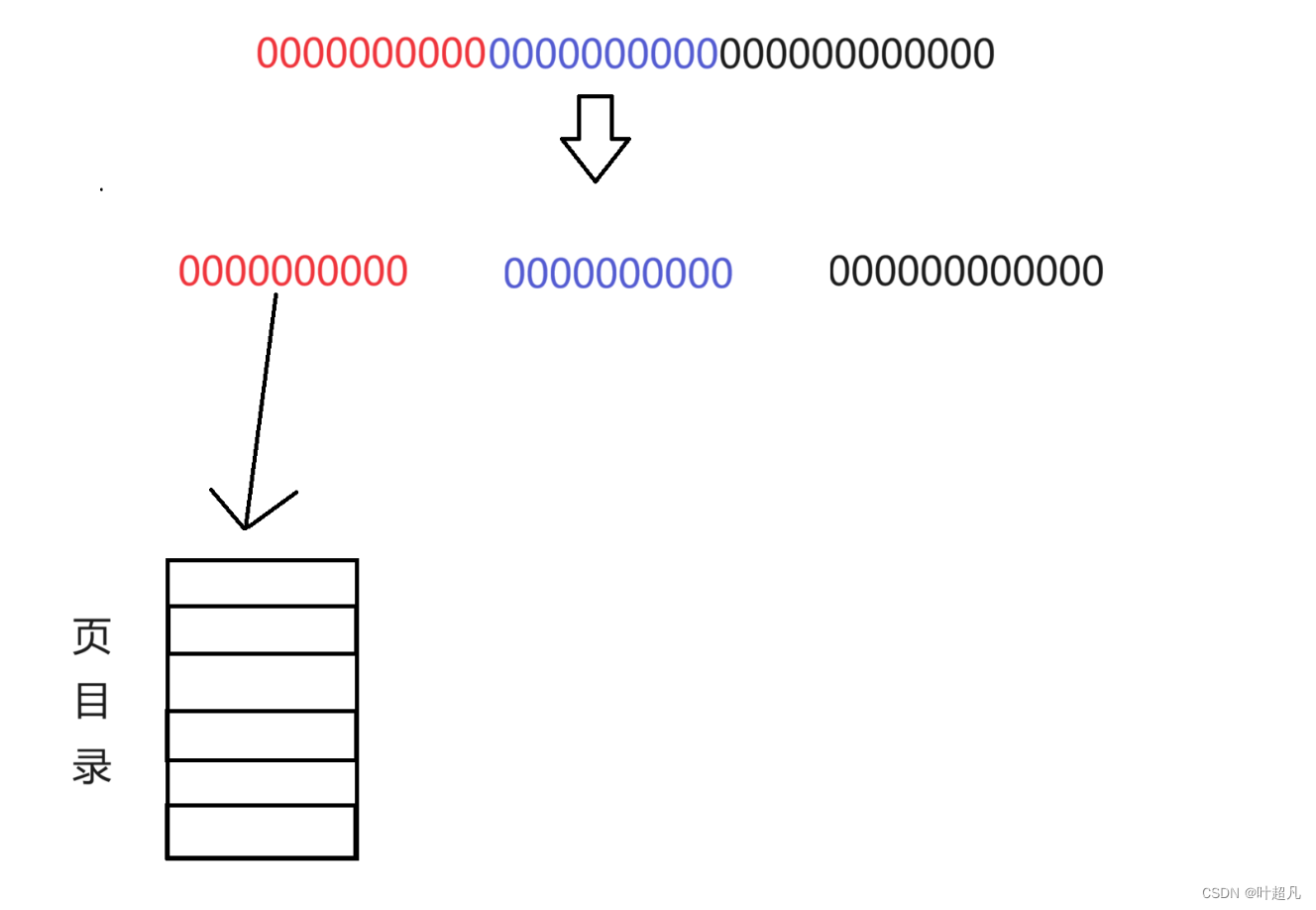
2^10也就差不多1KB的大小,假设每个条目的大小为10个字节,那么这个页目录的大小就是10KB的大小,因为页目录中的每个元素都是索引,所以他们也指向了一个对象,我们把这个对象称为页表项也可以叫为页表,而每个页表又有2^10个元素,所以每个页表就对应的是地址中的10个比特位
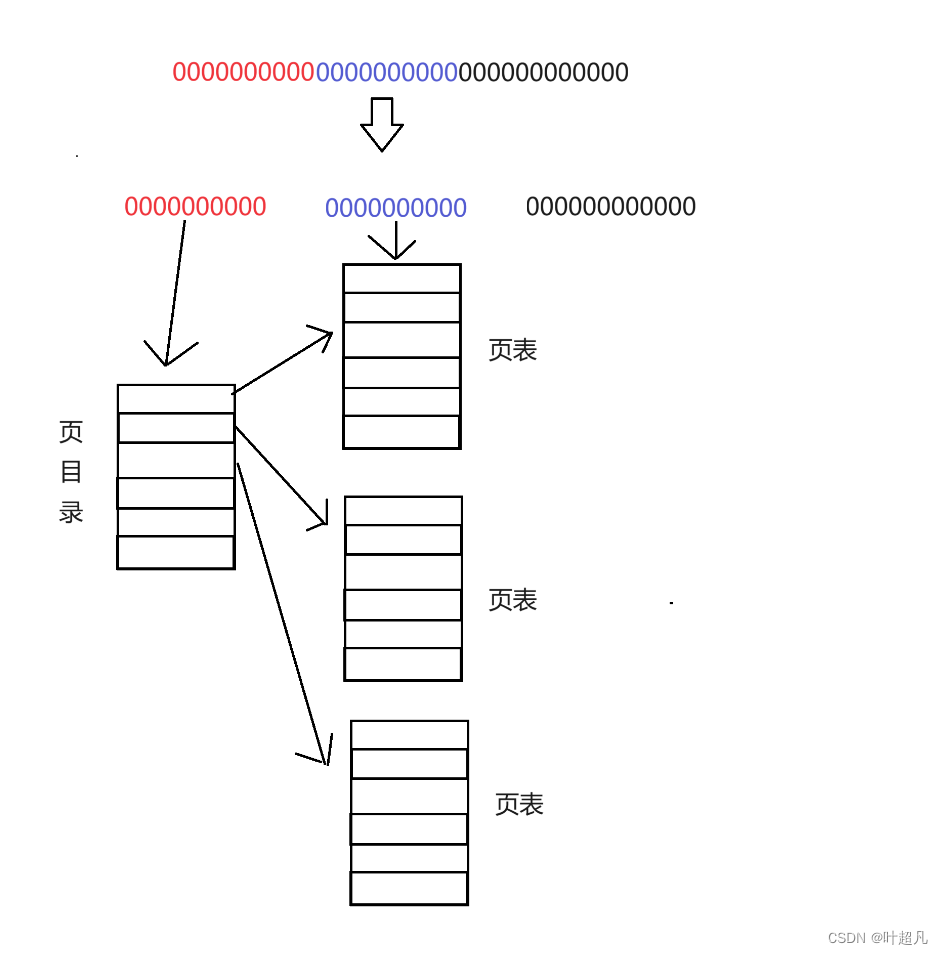
而页表中每个元素记录的是页框的起始物理地址,因为页框的大小刚好为4KB也就是2的12次方,也就刚好是32个比特位中的最后12个:
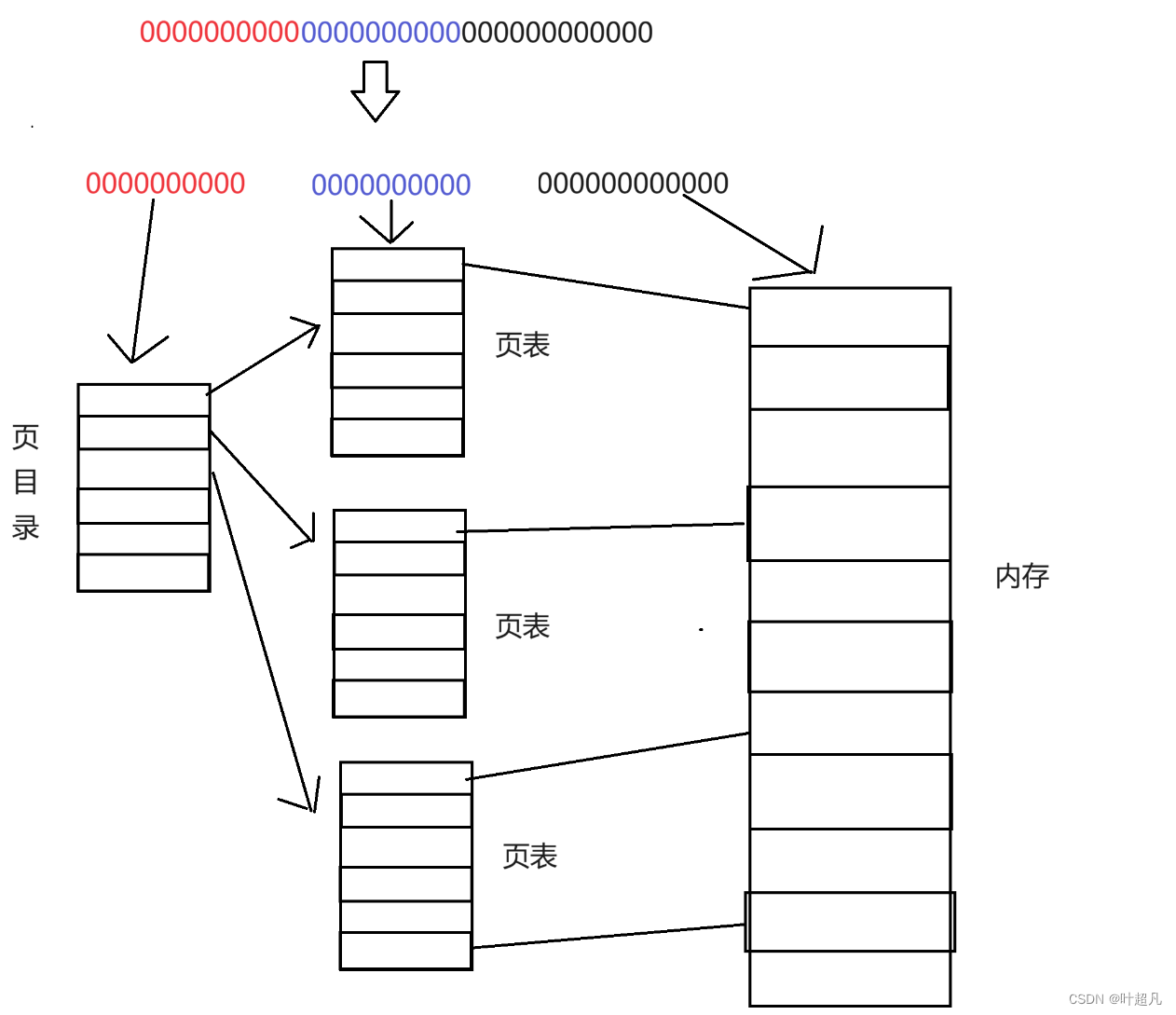
所以虚拟地址在向物理地址进行映射的时候首先根据虚拟地址的前10个比特位结合数组的起始位置和偏移量就可以找到页目录中指向的元素,找到对应的页表之后就又可以根据32个比特位的中间10个比特位找到页表中的指定元素,根据该元素我们就可以找到对应页框在内存上的起始地址,得到该地址之后就可以根据32个比特位中的最后12个比特位和页框的起始地址找打数据位于页框的具体位置,因为每个变量都有自己具体的大小,然后根据该变量的大小往后边偏移边读取就可以得到我们想要的所有数据,这就是为什么我们在写c语言取地址的时候得到都是起始地址,而不是所有地址,因为根据起始地址加上大小进行偏移就可以了,那么这就是页表的构成,并且并不是每个页表都需要创建,当页目录中不需要某个页表的时候就可以不创建该页表,所以页表的创建就变成了按需申请进而再减小了页表所占用的内存所以经过上面的操作页表的占用的空间一点都不大了,那么这就是页表构成希望大家能够理解。 -
相关阅读:
手记系列之七 ----- 分享Linux使用经验
【算法|贪心算法系列No.3】leetcode334. 递增的三元子序列
【前端实例代码】Html5+css3创建拟物风格昏昏欲睡的云朵动画网页效果~前端开发网页设计基础入门教程~适合初学者~超简单~
c++模板
基于SSM的人事档案管理系统(有报告)。Javaee项目。
计算机毕业设计php_thinkphp_vue的校园论坛网站
教资作文极简易[teacher zhouyin]
解决“service nginx does not support chkconfig”的问题?
风火编程--playwright爬虫
【K8S专栏】Kubernetes应用质量管理
- 原文地址:https://blog.csdn.net/qq_68695298/article/details/133848253