-
【Linux】文件IO基础知识——上篇
目录

前文
关于C语言文件操作,请看本篇博客,详解文件操作&相关函数(超详细!)_文件操作函数_花果山~~程序猿的博客-CSDN博客
对C语言接口进行复习。
在C语言中,fwrite, fgets, fprintf仅仅是C语言特有的接口,几乎每个编程语言都拥有其自己的输入,输出流接口,其目的也就是保证语言的跨平台性(语言直接调用系统接口,这会导致跨平台性减弱),这些语言级别输入输出流接口,本质上是对操作系统的调用。
接下来我们来学习操作系统级别的输入输出函数:
一, 系统级——文件操作接口
a. open
 pathname: 要打开或创建的目标文件flags : 打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行 “ 或 ” 运算,构成 flags 。参数 : 以下参数是经过 宏定义 的O_RDONLY (Open Read-Only) : 只读打开O_WRONLY (Open Write Only) : 只写打开O_RDWR (Open Read Write) : 读,写打开这三个常量,必须指定一个且只能指定一个。O_CREAT (Open Creat): 若文件不存在,则创建它。需要使用 mode 选项,来指明新文件的访问权限O_APPEND : 追加写O_TRUNC : 如果文件存在,则清空该文件;不存在则创建该文件。返回值:成功:新打开的文件描述符失败: -1
pathname: 要打开或创建的目标文件flags : 打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行 “ 或 ” 运算,构成 flags 。参数 : 以下参数是经过 宏定义 的O_RDONLY (Open Read-Only) : 只读打开O_WRONLY (Open Write Only) : 只写打开O_RDWR (Open Read Write) : 读,写打开这三个常量,必须指定一个且只能指定一个。O_CREAT (Open Creat): 若文件不存在,则创建它。需要使用 mode 选项,来指明新文件的访问权限O_APPEND : 追加写O_TRUNC : 如果文件存在,则清空该文件;不存在则创建该文件。返回值:成功:新打开的文件描述符失败: -1这些选项可以通过按位或运算进行组合,例如:
int fd = open("file.txt", O_RDWR | O_CREAT | O_TRUNC);参数flags不是普通的参数,我们知道open()函数用于打开或创建一个文件,并返回一个文件描述符。其中,flags参数用于指定打开文件的方式和权限。
那一个一个的传参是否有效率呢?我们看flags如何解决,思想:int 为32(64)个比特位,那么每一个比特位都储存一个参数。
- 2 #include
- 4 using namespace std;
- 6 #define O_ONE 0x1 // 0000 0001
- 7 #define O_two 0x2 // 0000 0010
- 8 #define O_Tree 0x4 // 0000 0100
- 9
- 10 int func(int flags)
- 11 {
- 12 if (flags & O_ONE) cout << "is O_ONE" << endl;
- 13 if (flags & O_two) cout << "is O_two" << endl;
- 14 if (flags & O_Tree) cout << "is O_Tree" << endl;
- W> 15 }
- 16
- 17 int main()
- 18 {
- 19 func(O_ONE);
- 20 func(O_two);
- 21 func(O_ONE | O_two); // 0000 0011, 这样就能同时传入多个标志位
- 22 func(O_ONE | O_two | O_Tree);
- 23 return 0;
- 24 }
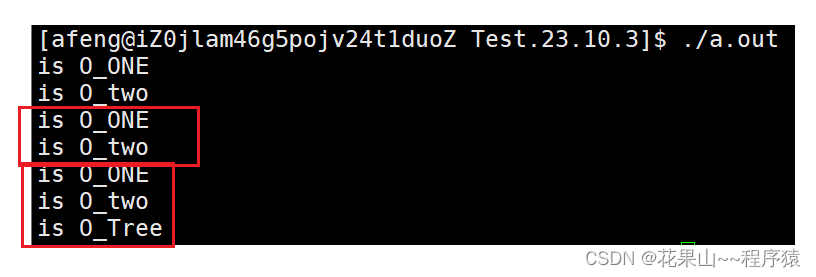
我们开始使用一番:

诺:
- 8 int main()
- 9 {
- 10 int ret = open("my_open_t.txt", O_RDWR | O_CREAT, 0666);
- 11 if (ret < 0)
- 12 {
- 13 perror("open fault:");
- 14 exit(-1);
- 15 }
- 16 cout << "success" << endl;
- 17
- 18 return 0;
- 19 }
而我们用另一个函数,里面有个mode参数,而那个参数本质上就是初始权限,说到初始权限,我们需要了解文件权限有关知识,请参考本篇博文中文件掩码部分:【Linux】权限管理,谁动了我代码?!_代码权限管理_花果山~~程序猿的博客-CSDN博客
那么我们照冒画虎,C语言中"w", "a", 不就有了?
int pd = open("my_open_t.txt", O_CREAT | O_WRONLY | O_TRUNC); // "w"int pd = open("my_open_t.txt", O_CREAT | O_WRONLY | O_APPEND); // "a"存在文件直接用2参数open。
b. close
用法:open(open返回值)即可关闭文件流
c. write


其中fd, 就是我们后面要讲的文件描述符。
d. read
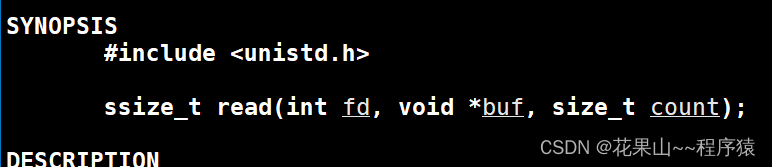
关于read的返回值,返回的是读取的字符数,我们在进程通信再一起讲解。
使用还是挺剪简单的:
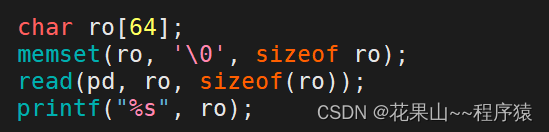
我们在使用read接口时,我们得注意一点,就是我们打印时会根据"\0"进行判断,但read读时,会有多少读多少,在一些情况下这会导致ro被读满,导致打印时发生错误,所以我们在使用read时,会对第三个参数字节数 - 1 来解决这种情况。
二,接口理解
我们尝试着打开多个文件:
- int pd1 = open("my_open_t.txt", O_RDWR | O_CREAT, 0666);
- 30 cout << "my_open pd:" << pd1 << endl;
- 31 int pd2 = open("my_open_t.txt", O_RDWR | O_CREAT, 0666);
- 32 cout << "my_open pd:" << pd2 << endl;
- 33 int pd3 = open("my_open_t.txt", O_RDWR | O_CREAT, 0666);
- 34 cout << "my_open pd:" << pd3 << endl;
- 35 int pd4 = open("my_open_t.txt", O_RDWR | O_CREAT, 0666);
- 36 cout << "my_open pd:" << pd4 << endl;
- 37
- 38 close(pd1);
- 39 close(pd2);
- 40 close(pd3);
- 41 close(pd4);
其中,打开的文件流为什么是从3开始?? 0,1,2这些去哪儿了呢? 原因是:0,1,2这三个流分别就是我们熟知的 stdin, stdout, stderr。
我们在用系统调用接口时,可以直接填0(或1,2)这个可以自己试试水
- 38 const char* s1 = "afeng\n";
- 39 write(1, s1, strlen(s1)); // stdout 1
在C语言中,stdin,stdout, stderr中这是FILE指针,系统层面,0,1,2是int类型;C语言中FILE本质上是一个结构体类型,stdin,stdout,stderr是存在于库中已经实例化的结构体。那么stdin等结构体中是否存在fd呢 ??? 答案是存在的,就在_fileno中
- 40 cout << "stdin :" << stdin->_fileno << endl;
- 41 cout << "stdout :" << stdout->_fileno << endl;
- 42 cout << "stderr :" << stderr->_fileno << endl;
那文件描述符——fd是什么呢?
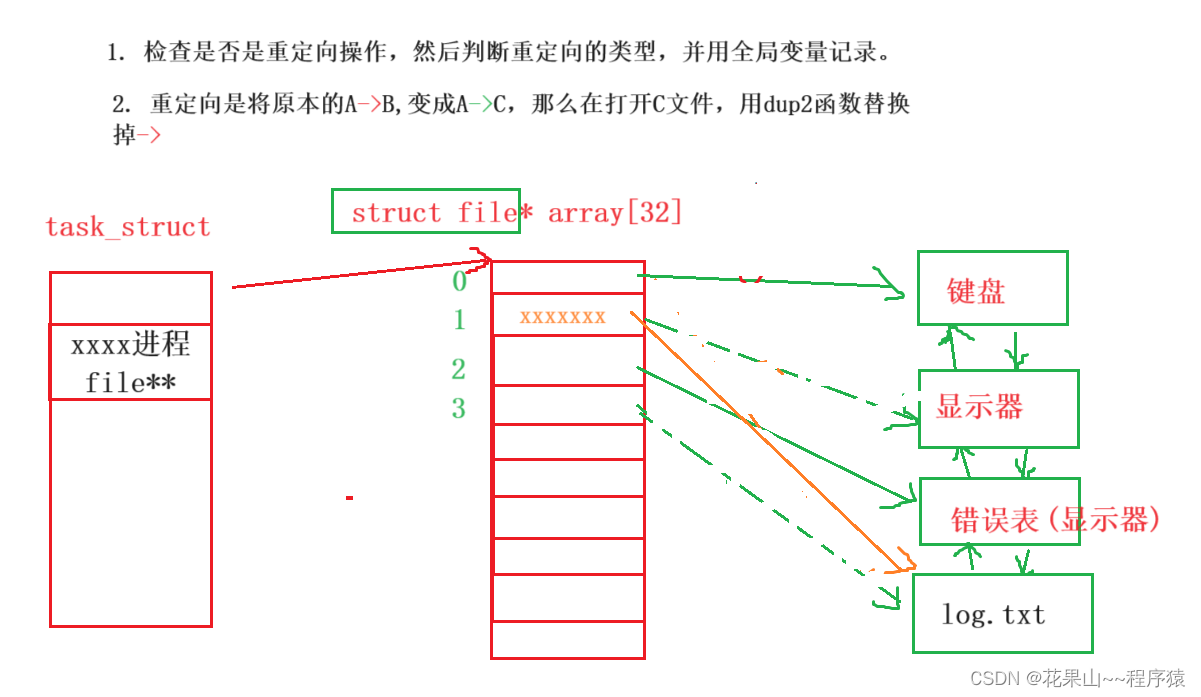
我们要访问文件,就必须先打开文件。而一般来说一个进程,理论上可以打开N个文件,但文件打开肯定是先被加载在内存中,这会消耗内存。那我打开多个文件那我怎么管理起来呢?答案还是:先描述,后组织。系统内核,怎么管理文件打开的呢? 请看下图:
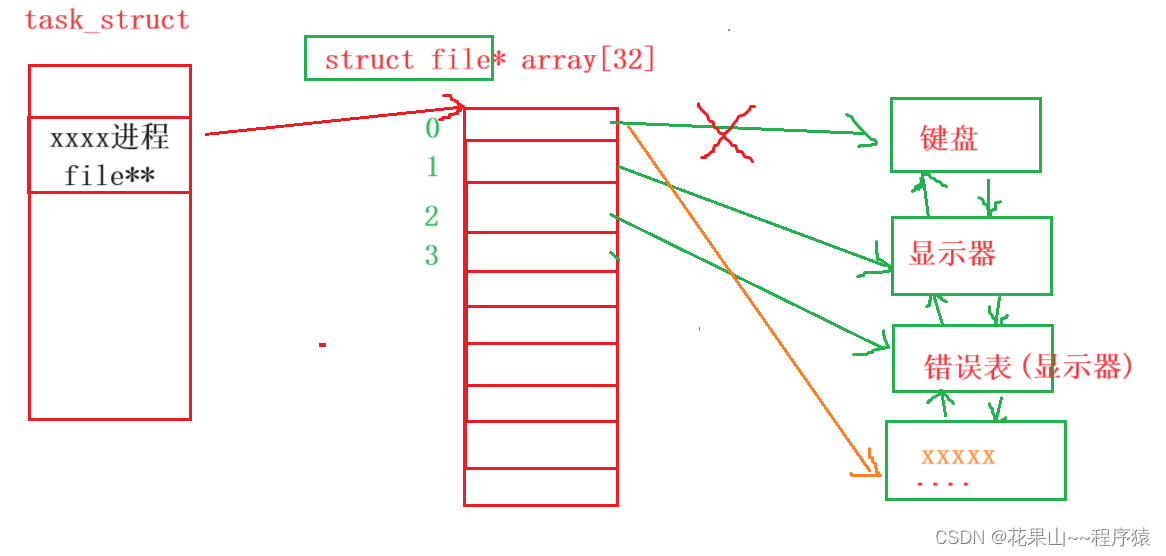
如你所见,fd(文件描述符)就是从0开始的小整数。当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了file结构体。表示一个已经打开的文件对象。而进程执行open系统调用,所以必须让进 程和文件关联起来。每个进程都有一个指针*files, 指向一张表files_struct,该表最重要的部分就是包涵一个指针数组,每个元素都是一个指向打开文件的指针!所以,本质上,文件描述符就是该数组的下标。所以,只要拿着文件描述符,就可以找到对应的文件。
三,文件描述符分配规则
尝试下面代码:
- close(0);
- 39 int fd = open("my_open_t.txt", O_RDWR | O_APPEND);
- 40 cout << "fd : " << fd << endl;

如你所见,当我关闭stdin后,打开的新文件在0下标处,我们能发现其规则:
在 files_struct 数组当中,找到当前没有被使用的 最小的一个下标 ,作为新的文件描述符。原理
以关闭键盘文件为例, 我们通过close(0), 本质上就是对键盘文件描述符置为NULL,然后在打开新文件时,在最小下标内容改为新文件描述符,这本质上也是输出重定向。
可能这个不怎么理解,下面请测试一下下面代码:
- close(1);
- 39 int fd = open("my_open_t.txt", O_RDWR | O_APPEND);
- 40 cout << "fd : " << fd << endl;
- 41 cout << "fd cout_success" << endl;
- 42 printf(" fd printf\n");

如你所见,关闭stdout后,由于stdout结构体中,文件描述符默认的是1,关闭后并打开新的文件,这就导致输出重定向,数据输出到了打开的文件。输入重定向原理也是如此
那这真的是重定向吗? 答案不是,我们只是利用了打开的新文件把最小下标作为文件描述符这一规则而已,那输入输出重定向的实现到底是如何实现???
答案是系统调用函数
四,重定向——dup2

关于dup2的两个参数是那些?这里用一张图进行表示:
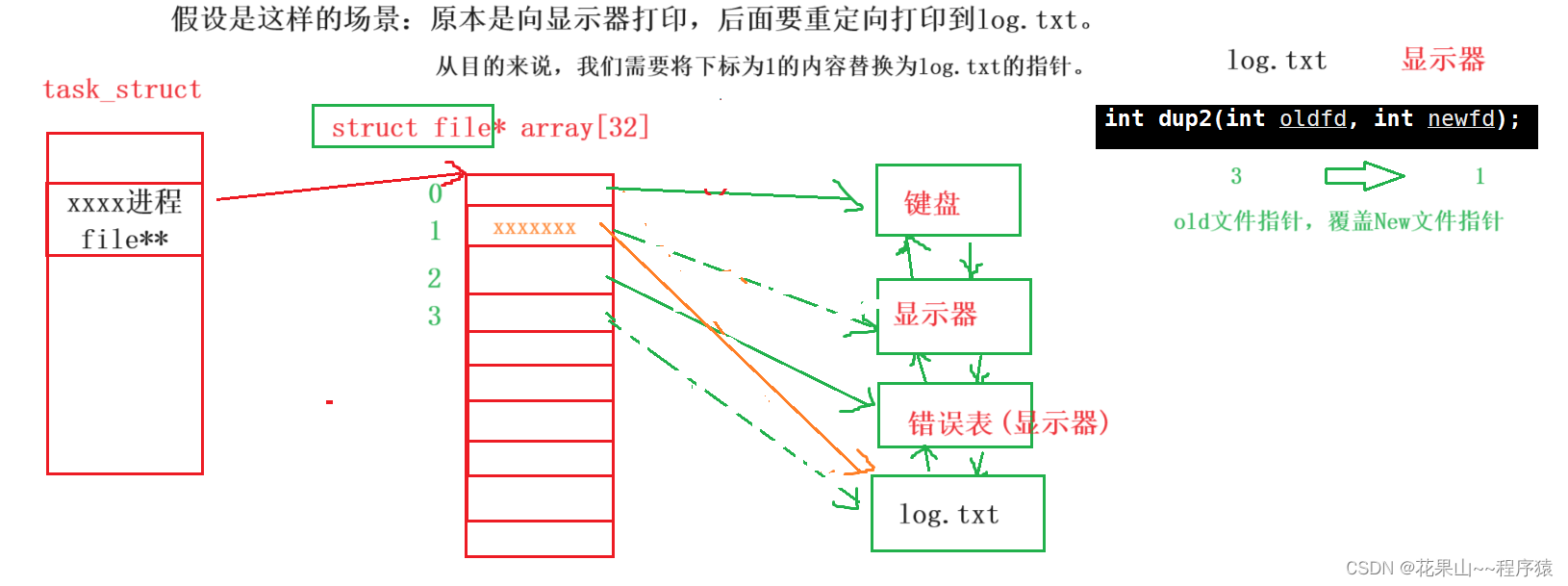
补充知识:问在linux中如何实现面向对象语言中的多态??? 函数指针,通过在结构体中包含函数指针,来实现像类中成员方法。
简易shell——重定向
在进程管理中我们制作了一个简单shell, 但当时没有实现重定向功能。
今天我们就通过学习到的dup2()覆盖文件标识符的方法来实现
里面代码重合比较严重,就只展示实现的check_TRUNC和 在创建子进程之前,对重定向的特殊处理,代码如下:
- 12 #define OUTPUT 1 // 输出重定向
- 13 #define ADD_OUTPUT 2 // 追加输出重定向
- 14 #define INTPUT 3 // 输入重定向
- 16
- 17
- 18 // check_TRUNC的目标:
- 19 // 1. 若是重定向则返回需要重定向的文件名位置
- 20 // 2. 并且确定重定向的类型
- 21 int TRUNC_status = -1;
- 22 char* check_TRUNC(char* ptr)
- 23 {
- 24 assert(ptr);
- 25 char* start = ptr;
- 26 char* end = ptr + strlen(ptr) - 1;
- 27
- 28 while (start <= end)
- 29 {
- 30 if (*end == '>')
- 31 {
- 32 if (*(end - 1) == '>')
- 33 {
- 34 // 追加输出重定向
- 35 TRUNC_status = ADD_OUTPUT;
- 36 *(end - 1) = '\0';
- 37 end++;
- 38 break;
- 39 }
- 41 TRUNC_status = OUTPUT;
- 42 *end = '\0';
- 43 end++;
- 44 break;
- 45 }else if (*end == '<')
- 46 {
- if (*(end - 1) == '<')
- 33 {
- 34 // 追加输出重定向
- 35 TRUNC_status = INTPUT;
- 36 *(end - 1) = '\0';
- 37 end++;
- 38 break;
- 39 }
- 55 TRUNC_status = INTPUT;
- 56 *end = '\0';
- 57 end++;
- 58 break;
- 59 }
- 60
- 61 end--;
- 62 if (start > end)
- 63 {
- 64 end = nullptr;
- 65 }
- 66 }
- 67
- 68 return end;
- 69 }
- ..................
- 90 // 拆分前先判断重定向,从而找出重定向的文件
- 91 int fd;
- 92 char* ptr = nullptr;
- W> 93 if (ptr = check_TRUNC(instruct))
- 94 {
- 95 // 给出重定向解决方案
- 96 switch(TRUNC_status)
- 97 {
- 98 case ADD_OUTPUT:
- 99 fd = open(ptr, O_WRONLY | O_APPEND | O_CREAT, 0666);
- 100 if (fd < 0)
- 101 {
- 102 perror("pd:");
- 103 exit(-1);
- 104 }
- 105 dup2(fd, 1);
- 106 break;
- 108 case OUTPUT:
- 109 fd = open(ptr, O_WRONLY | O_TRUNC | O_CREAT, 0666);
- 110 if (fd < 0)
- 111 {
- 112 perror("pd:");
- 113 exit(-1);
- 114
- 115 dup2(fd, 1);
- 116 break;
- 118 case INTPUT:
- 119 fd = open(ptr, O_RDONLY);
- 120 if (fd < 0)
- 121 {
- 122 perror("pd:");
- 123 exit(-1);
- 124 }
- 125 dup2(fd, 0);
- 126 break;
- 130 default:
- 131 printf("what? bug?");
- 132 break;
- 133 }
- 134 }
- ..........
五,回看缓冲区
首先是为什么需要缓冲区,对数据传输我们有两种模式,一种是写透模式(WT)(说人话是,来一份数据就传递一份),结果就是效率低;另一种是写回模式(WB)(积累一定数据,再传递),效率就比较高。
缓冲区的刷新策略:一般情况 + 特殊情况
a, 缓冲区刷新策略
一般情况:
1. 立即刷新2. 行刷新(行缓冲,遇到\n刷新)
3. 全刷新(全缓冲)
特殊情况:
1. 用户强制刷新(fflush函数)2. 进程退出
一般的设备,都倾向于全缓冲,这样以来就减少了对外设的访问次数,从而提高整机效率。(其中对外设的访问中,外设准备IO操作最废资源,相反数据量并不是主要问题)
但不同使用场景就会有不同的刷新策略:比如:显示器刷新策略,则可以是行刷新。磁盘文件写入 ,刷新策略就会是全刷新。
b, 缓冲区存在哪儿??
我们通过这段代码来引入这个知识,请看下面这段代码:
- printf("%s\n", "C_printf");
- 22 const char* c1 = "const_char_fputs\n";
- 23 fputs(c1, stdout);
- 24 fprintf(stdout, "%s\n", "fprintf");
- 25
- 26 // 系统接口
- 27 const char* c2 = "系统_write\n";
- 28 write(1, c2, strlen(c2));
- 29
- 30 fork(); // fork前面的代码虽然被执行完,但并不代表被刷新出来
- 31 return 0;
结果:
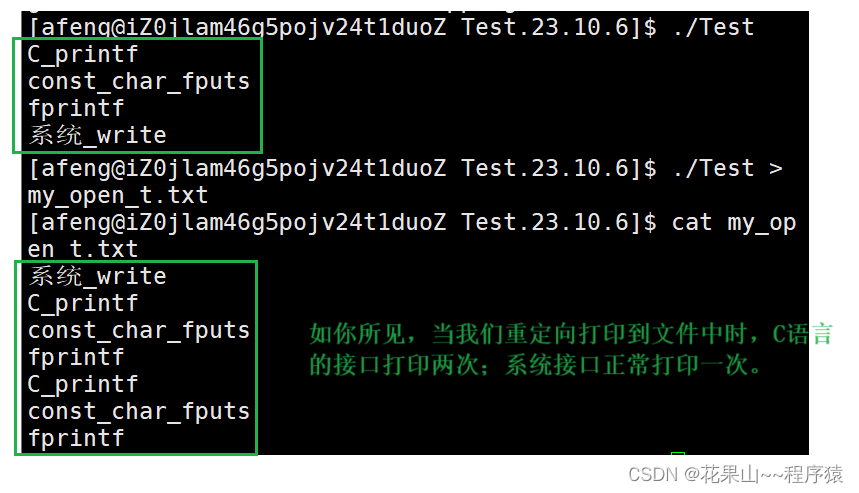
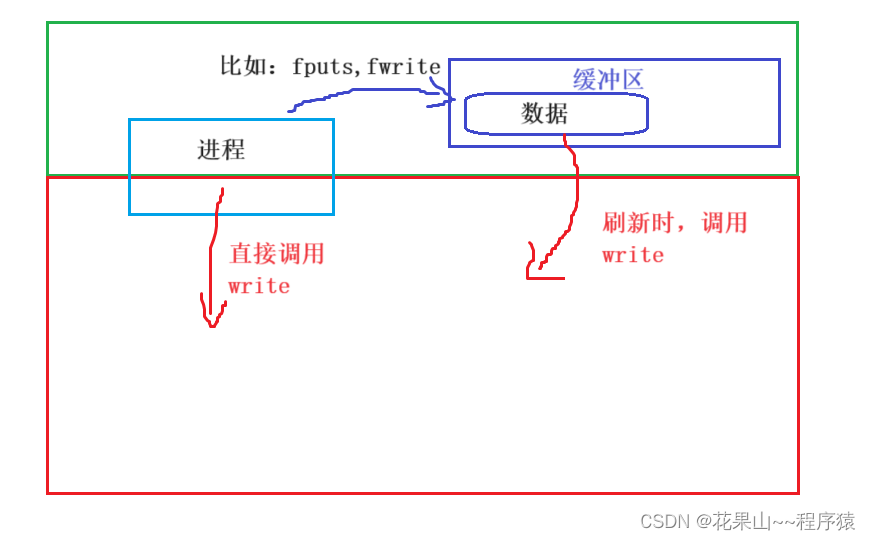
这里我们可以设想缓冲区是那里储存的呢? 是OS,还是C标准库?? 答案是:C标准库,请看下图进行理解
从代码上分析:
1,第一次,我们打印至显示器,我们采用了行刷新。等到执行到了fork函数时,缓冲区已经没有数据了,fork则失去了意义。
2. 第二次, 我们打印至文件中,本质上是向磁盘写入,隐形的刷新策略从行刷新变成全刷新,\n则失去意义。当fork时,前面代码已经执行完毕,C标准库,缓冲区储存着父进程的数据,子进程退出时,触发进程退出的缓冲区刷新机制,向磁盘文件进行写入,此时子进程进行写时拷贝,拷贝缓冲区的数据。
等到父进程退出,至此就有了两份C接口数据。
C语言中有缓冲区,那内核有吗?
诶! 还真有,内核缓冲区的内容我们在网络部分再给大家讲解。
c, 尝试手搓一个——缓冲区
代码也有100行,我们先聊思路。
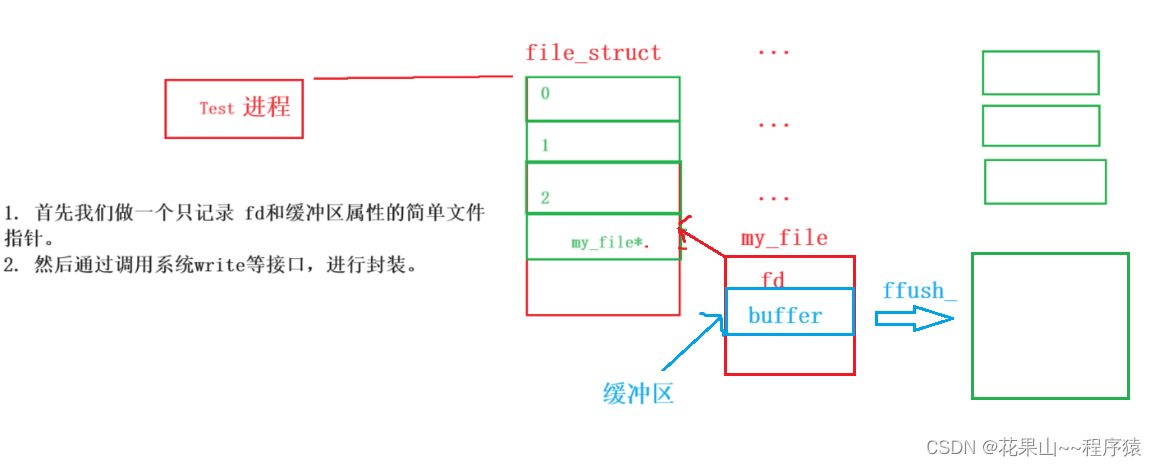
- #include
- 2 #include
- 3 #include
- 4 #include
- 5 #include
- 6 #include
- 7 #include
- 8 #include
- 9
- 10
- 11 #define NUM 1024
- 12
- 13 struct My_File
- 14 {
- 15 int fd;
- 16 char buffer[NUM];
- 17 int end; // 记录缓冲区末尾
- 18 };
- 19
- 20 typedef struct My_File My_File;
- 21
- 22 My_File* fopen_(const char* path, const char* mode)
- 23 {
- 24 assert(path);
- 25 assert(mode);
- 26 My_File* file = NULL;
- 27
- if (strcmp(mode, "w") == 0)
- 29 {
- 30 file = (My_File*)malloc(sizeof (My_File));
- 31 file->fd = open(path, O_WRONLY | O_TRUNC | O_CREAT , 0666);
- 32 if (file->fd < 0)
- 33 {
- 34 perror("fail open");
- 35 // 在底层为fopen进行调用
- 36 // 没找到,则要free掉malloc结构体
- 37 free(file);
- 38 return NULL;
- 39 }
- 40 // 成功打开文件,就要对缓冲区进行处理
- 41 memset(file->buffer, '0', sizeof(file->buffer));
- 42 file->end = 0;
- 43 return file;
- 44 }
- 45 else if (strcmp(mode, "w+") == 0)
- 46 {
- 47
- 48 }
- 49 else if (strcmp(mode, "r") == 0)
- 50 {
- 52 }
- 53 else if (strcmp(mode, "r+") == 0)
- 54 {
- 55
- 56 }
- 57 else if (strcmp(mode, "a") == 0)
- 58 {
- 59
- 60 }
- 61 else if (strcmp(mode, "a+") == 0)
- 62 {
- 63
- 64 }else
- 65 {
- 66 // 都没有匹配
- 67 }
- 68
- 69 return file;
- 70 }
- 71
- 72 int fflush_(My_File* file)
- 73 {
- 74 assert(file);
- 75 if (file->end != 0)
- {
- 77 write(file->fd, file->buffer, file->end);
- 78 // 然后调用一个系统级的刷新函数
- 79 syncfs(file->fd);
- 80 file->end = 0;
- 81 }
- 82 return 0;
- 83 }
- 84
- 86 int fputs_(const char* str, My_File* file)
- 87 {
- 88 // 底层还是调用write
- 89 assert(str);
- 90 assert(file);
- 91 // strcpy 一定得跟这end走,不然会出现数据覆盖的问题
- 92 strcpy(file->buffer + file->end, str);
- 93 file->end = file->end + strlen(str);
- 94
- 95 // 测试一下标准输出
- 96 // file->fd = 1;
- 97
- 98 if (file->fd == 1)
- 99 {
- // 标准输出,关于标准输出的策略,我们可以只需给缓冲区,
- 101 // 其余交给标准输出文件自己的刷新策略。
- 102 if (file->buffer[file->end - 1] == '\n')
- 103 {
- 104 write(1, file->buffer, file->end);
- 105 file->end = 0;
- 106 }
- 107 }else if (file->fd == 2)
- 108 {
- 109 //标准错误输出
- 111 }
- 114 return 0;
- 115 }
- 116
- 117
- 118 void fclose_(My_File* file)
- 119 {
- 120 assert(file);
- 121 fflush_(file);
- 122 free(file);
- }
六,测试题
- int main()
- 11 {
- 12 close(1);
- 13 int fd = open("my_ls.txt", O_WRONLY | O_TRUNC | O_CREAT, 0666);
- 14 if (fd < 0)
- 15 {
- 16 cout << "fail open" << endl;
- 17 exit(-1);
- 18 }
- 19
- 20 printf("hello linux\n");
- 21 close(fd);
- 22 return 0;
- 23 }
请解释一下,为什么在close(1)之后,在显示器和my_ls.txt文件都没有查看到打印的原因??
如图解释:

结语
本小节就到这里了,感谢小伙伴的浏览,如果有什么建议,欢迎在评论区评论,如果给小伙伴带来一些收获请留下你的小赞,你的点赞和关注将会成为博主创作的动力。
-
相关阅读:
[新增EA028高压注射器]24套UML+EA和StarUML的建模示范视频-全程字幕(2022.7.4更新)
JavaScript面向对象
css 块级元素与内联元素
前后端分离解决跨域问题
python模块的介绍和导入
百位上的数字(蓝桥杯真题)
本地数据库IndexedDB - 学员管理系统之列表管理(二)
c++ SQLite 特别好用的库使用实例-创建数据库(1)
Python中dataframe.groupby()根据数据属性对数据分组
树与二叉树
- 原文地址:https://blog.csdn.net/qq_72112924/article/details/133499683
