-
知识蒸馏(Knowledge Distillation)简述
Reference:
知识蒸馏被广泛用于模型压缩和迁移学习当中。开山之作应该是 Distilling the Knowledge in a Neural Network 。这篇文章中,作者的动机是找到一种方法,把多个模型的知识提炼给单个模型。
在大规模的机器学习中,我们通常在训练阶段和部署阶段使用非常相似的模型,尽管他们的要求非常不同:
- 对于语音和目标识别等任务,训练必须从非常大的、高度荣冗余的数据集提取结构,但它不需要实时操作,因此可以使用大量的计算;
- 然而,在部署到用户端时,对于延迟和性格上有着特别高的要求。
这里的蒸馏针对的是神经网络的知识。一般认为模型的参数保留了模型学到的知识,因此最常见的迁移学习的方式就是在一个大的数据集上先做预训练,然后使用预训练得到的参数在一个小的数据集上做微调(两个数据集往往领域不同或者任务不同)。例如先在 ImageNet 上做预训练,然后在 COCO 数据集上做检测。
在这篇论文中,作者认为可以将模型看成是黑盒,知识可以看成是输入到输出的映射关系。因此,我们可以先训练好一个 teacher 网络,然后将 teacher 的网络输出结果 q q q 作为 student 网络的目标,训练 student 网络,使得 student 网络的结果 p p p 接近 q q q。
如果按照这里的想法,我们可以将损失函数写成:
L = C E ( y , p ) + α C E ( q , p ) L=CE(y,p)+\alpha CE(q,p) L=CE(y,p)+αCE(q,p)这里 CE 是 交叉熵(Cross Entropy), y y y 是真实标签的 onehot编码,即表示正确与否, q q q 是 teacher 网络的输出结果, p p p 是 student 网络的输出结果。在模型学习区分大量类别时,正常的训练目标是最大化正确答案的平均对数概率,这是学习还有一个额外的作用,即训练模型会为所有错误答案分配概率,即使这些概率很小,其中一些也比其他的要大得多。错误答案一定程度表示模型倾向于如何去泛化信息。例如,一辆宝马的图像小概率会被误认为是一辆垃圾车,但这种错误也比将它误认为是胡萝卜的可能性大得多。训练模型优化性能的目的是更好的概括新数据,即,训练模型更好的泛化。但这需要一个正确的泛化方法,这些信息通常是无法获得的。使用 teacher 的原因在于,我们可以将这部分的知识,从一个大模型蒸馏(distill)(也可以理解成提炼)到一个小模型中,我们可以就训练小模型以与大模型相同的方式进行泛化。如果大模型泛化得很好,那么在相同训练集上,与大模型有相同泛化方式的小模型在测试数据上的表现通常比在用于训练集成的以正常方式训练的小模型要好得多。
将大模型的泛化能力转移到小模型的一个方法是使用大模型产生的概率作为小模型的“软目标”(soft target)。当大模型是几个简单模型的集合(bagging的思路),可以用他们各自预测分布的算术或几何均值作为软目标。当软目标具有高熵,它们在每个训练案例中提供的信息比硬目标多得多,且不同场景间的梯度有更小的方差,所以小模型往往可以用比原有方式更少的数据训练并且有着高不少的学习率。
综上,按照上面的说法直接使用 teacher 网络的 softmax 的输出结果 q q q 可能不大合适。一个大模型总是以非常高的置信度产生正确答案。例如,在 MINST 数据中,对于某个 2 2 2 的输入,对于 2 2 2 的预测概率会很高,而对于 2 2 2 类似的数字,例如 3 3 3 和 7 7 7 的 预测概率为 1 0 − 6 10^{-6} 10−6 和 1 0 − 9 10^{-9} 10−9。而这些信息是有价值的,它定义了丰富的相似性数据的结构(例如,它说哪些 2 2 2看起来像 3 3 3,哪些看起来像 7 7 7),而在上面的情况下,它几乎没有在传递阶段对交叉熵代价函数产生影响,因为它们的概率值接近 0 0 0。
用于训练小模型的传输集可以完全由未标记的数据组成,或者可以使用原始训练集。文中测试使用原始训练集效果很好。
因此,这里就提出来一种一般解决方式,并将其称为“蒸馏”---------将最后的 softmax 温度升高,直到大模型产生一组合适的软目标。然后再训练小模型时使用相同的温度匹配这些软目标。
文中提出的蒸馏方式为 softmax-T,公式如下所示:
q i = exp ( z i / T ) ∑ j exp ( z j / T ) q_i=\frac{\exp \left(z_i / T\right)}{\sum_j \exp \left(z_j / T\right)} qi=∑jexp(zj/T)exp(zi/T)这里 q i q_i qi 是 student 网络学习的对象(soft targets), z i z_i zi 是神经网络 softmax 前的输出 logit。如果将 T T T 取 1 1 1,这个公式就是 softmax,根据 logit 输出各类别的概率。如果 T T T 接近于 0 0 0,则最大值会越接近 1 1 1,其他值会接近 0 0 0,近似于 onehot编码。如果 T T T 越大,则输出的结果分布越平缓,相当于平滑的一个作用,起到保留相似信息的作用。如果 T T T 等于无穷,就是一个均匀分布。最终文章根据上述的损失函数对网络进行训练:
- 在 MNIST 这个数据集上,先使用大的网络进行训练,测试集错误
67
67
67 个;小网络训练,测试集错误
146
146
146 个。加入
soft targets到目标函数中,相当于正则项,测试集的错误降低到了 74 74 74 个。这证明了 teacher 网络确实把知识转移到了 student 网络,使结果变好了; - 第二个实验是在 speech recognition 领域,使用不同的参数训练了
10
10
10 个 DNN,对这
10
10
10 个模型的预测结果求平均作为 emsemble 的结果,相比于单个模型有一定的提升。然后将这
10
10
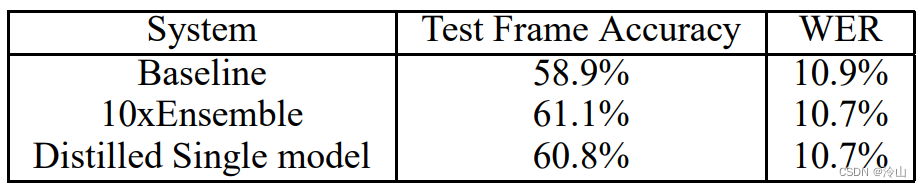
10 个模型作为 teacher 网络,训练 student 网络,得到的 Distilled Single model 相比于直接的单个网络,也有一定的提升,结果见下表:
结论
知识蒸馏,可以将一个网络的知识转移到另一个网络,两个网络可以是同构或者异构。做法是先训练一个 teacher 网络,然后使用这个 teacher 网络的输出和数据的真实标签取训练 student 网络。知识蒸馏可以用来将网络从大网络转化成一个小网络,并保留接近于大网络的性能;也可以将多个网络学习到的知识转移到一个网络中,使得单个网络的性能接近 emsemble 的结果。
-
相关阅读:
RSA密码的手动算法+快速幂算法
(九)集合 - List
使用HuggingFace实现 DiffEdit论文的掩码引导语义图像编辑
AQS源码解析 7.共享模式_CyclicBarrier重复屏障
OpenStack 下 CentOS6.X 镜像网络初始化失败问题排查
【计算机网络实验】TCP和UDP传输过程仿真与分析
INI 配置文件
算法结构-树状数组
进程地址空间
ADSP-21479的开发详解五(AD1939 C Block-Based Talkthru 48 or 96 kHz)音频直通
- 原文地址:https://blog.csdn.net/qq_28087491/article/details/133843823