-
图像语义分割 pytorch复现U2Net图像分割网络详解
图像语义分割 pytorch复现U2Net图像分割网络详解

U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection1、U2Net网络模型结构
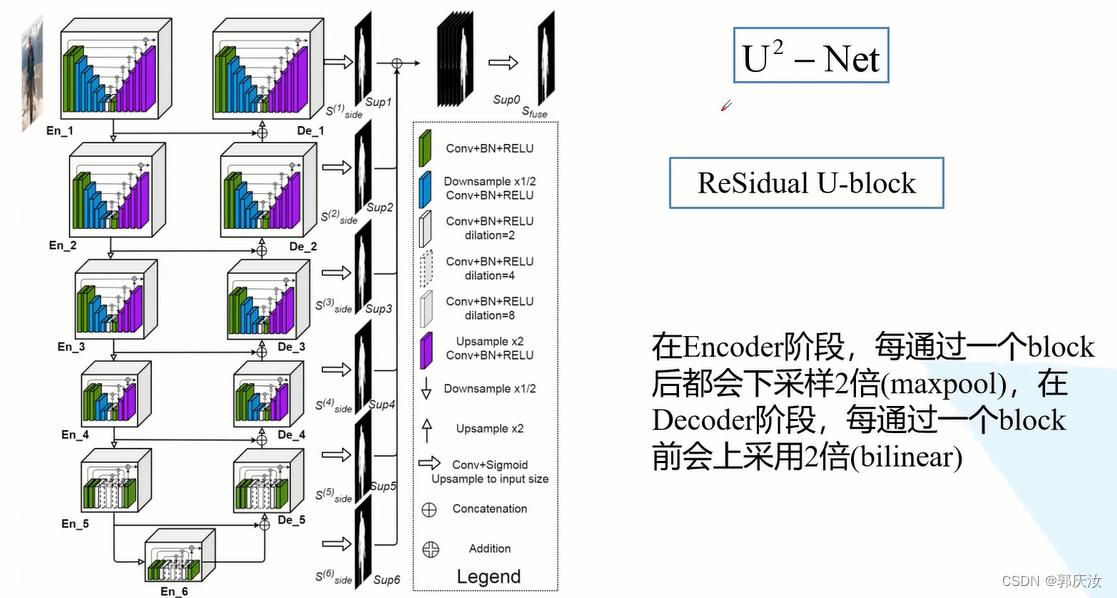
网络的主体类似于U-Net的网络结构,在大的U-Net中,每一个小的block都是一个小型的类似于U-Net的结构,因此作者取名U2Net
仔细观察,可以将网络中的block分成两类:
第一类:En_1 ~ En_4 与 De_1 ~ De_4这8个block采用的block其实是一样的,只不过模块的深度不同。第二类:En_5、En_6、De_5
- 在整个U2Net网络中,在Encoder阶段,每通过一个block都会进行一次下采样操作(下采样2倍,maxpool)
- 在Decoder阶段,在每个block之间,都会进行一次上采样(2倍,bilinear)
2、block模块结构解析
在 En_1 与 De_1 模块中,采用的 block 是RSU-7;
En_2 与 De_2采用的 block 是RSU-6(RSU-6相对于RSU-7 就是少了一个下采样卷积以及上采样卷积的部分,RSU-6 block只会下采样16倍,RSU-7 block下采样的32倍);
En_3 与 De_3采用的 block 是RSU-5
En_4 与 De_4采用的 block 是RSU-4
En_5、En_6、De_5采用的block是RSU-4F
(使用RSU-4F的原因:因为数据经过En_1 ~ En4 下采样处理后对应特征图的高与宽就已经相对比较小了,如果再继续下采样就会丢失很多上下文信息,作者为了保留上下文信息,就对En_5、En_6、De_5不再进行下采样了而是在RSU-4F的模块中,将下采样、上采样结构换成了膨胀卷积)RSU-7模块
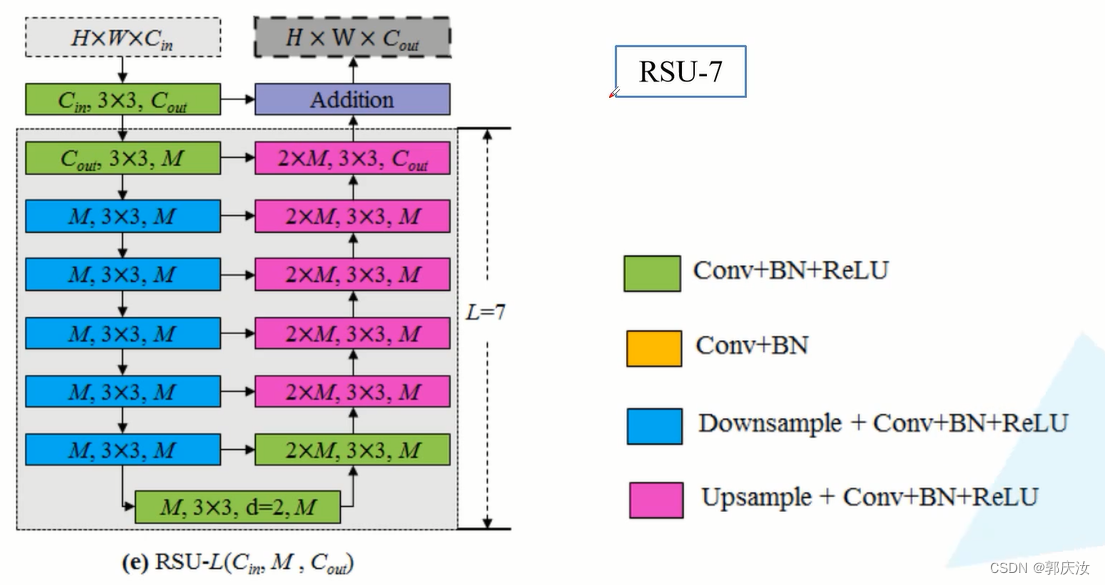 详细结构图解
详细结构图解

RSU-4F

saliency map fusion module
saliency map fusion module模块是将每个阶段的特征图进行融合,得到最终的预测概率图,即下图中,红色框标注的模块

其会收集De_1、De_2、De_3、De_4、De_5、En_6模块的输出,将这些输出分别通过一个3x3的卷积层(这些卷积层的kerner的个数都是为1)输出的featuremap的channel是为1的,在经过双线性插值算法将得到的特征图还原回输入图像的大小;再将得到的6个特征图进行concant拼接;在经过一个1x1的卷积层以及sigmoid激活函数,最终得到融合之后的预测概率图。U2Net网络结构详细参数配置

u2net_full大小为176.3M、u2net_lite大小为4.7MRSU模块代码实现

class RSU(nn.Module): def __init__(self, height: int, in_ch: int, mid_ch: int, out_ch: int): super().__init__() assert height >= 2 self.conv_in = ConvBNReLU(in_ch, out_ch) encode_list = [DownConvBNReLU(out_ch, mid_ch, flag=False)] decode_list = [UpConvBNReLU(mid_ch * 2, mid_ch, flag=False)] for i in range(height - 2): encode_list.append(DownConvBNReLU(mid_ch, mid_ch)) decode_list.append(UpConvBNReLU(mid_ch * 2, mid_ch if i < height - 3 else out_ch)) encode_list.append(ConvBNReLU(mid_ch, mid_ch, dilation=2)) self.encode_modules = nn.ModuleList(encode_list) self.decode_modules = nn.ModuleList(decode_list) def forward(self, x: torch.Tensor) -> torch.Tensor: x_in = self.conv_in(x) x = x_in encode_outputs = [] for m in self.encode_modules: x = m(x) encode_outputs.append(x) x = encode_outputs.pop() for m in self.decode_modules: x2 = encode_outputs.pop() x = m(x, x2) return x + x_in- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
RSU4F模块代码实现

class RSU4F(nn.Module): def __init__(self, in_ch: int, mid_ch: int, out_ch: int): super().__init__() self.conv_in = ConvBNReLU(in_ch, out_ch) self.encode_modules = nn.ModuleList([ConvBNReLU(out_ch, mid_ch), ConvBNReLU(mid_ch, mid_ch, dilation=2), ConvBNReLU(mid_ch, mid_ch, dilation=4), ConvBNReLU(mid_ch, mid_ch, dilation=8)]) self.decode_modules = nn.ModuleList([ConvBNReLU(mid_ch * 2, mid_ch, dilation=4), ConvBNReLU(mid_ch * 2, mid_ch, dilation=2), ConvBNReLU(mid_ch * 2, out_ch)]) def forward(self, x: torch.Tensor) -> torch.Tensor: x_in = self.conv_in(x) x = x_in encode_outputs = [] for m in self.encode_modules: x = m(x) encode_outputs.append(x) x = encode_outputs.pop() for m in self.decode_modules: x2 = encode_outputs.pop() x = m(torch.cat([x, x2], dim=1)) return x + x_in- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
u2net_full与u2net_lite模型配置函数
def u2net_full(out_ch: int = 1): cfg = { # height, in_ch, mid_ch, out_ch, RSU4F, side side:表示是否要收集当前block的输出 "encode": [[7, 3, 32, 64, False, False], # En1 [6, 64, 32, 128, False, False], # En2 [5, 128, 64, 256, False, False], # En3 [4, 256, 128, 512, False, False], # En4 [4, 512, 256, 512, True, False], # En5 [4, 512, 256, 512, True, True]], # En6 # height, in_ch, mid_ch, out_ch, RSU4F, side "decode": [[4, 1024, 256, 512, True, True], # De5 [4, 1024, 128, 256, False, True], # De4 [5, 512, 64, 128, False, True], # De3 [6, 256, 32, 64, False, True], # De2 [7, 128, 16, 64, False, True]] # De1 } return U2Net(cfg, out_ch) def u2net_lite(out_ch: int = 1): cfg = { # height, in_ch, mid_ch, out_ch, RSU4F, side "encode": [[7, 3, 16, 64, False, False], # En1 [6, 64, 16, 64, False, False], # En2 [5, 64, 16, 64, False, False], # En3 [4, 64, 16, 64, False, False], # En4 [4, 64, 16, 64, True, False], # En5 [4, 64, 16, 64, True, True]], # En6 # height, in_ch, mid_ch, out_ch, RSU4F, side "decode": [[4, 128, 16, 64, True, True], # De5 [4, 128, 16, 64, False, True], # De4 [5, 128, 16, 64, False, True], # De3 [6, 128, 16, 64, False, True], # De2 [7, 128, 16, 64, False, True]] # De1 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
U2Net网络整体定义类
class U2Net(nn.Module): def __init__(self, cfg: dict, out_ch: int = 1): super().__init__() assert "encode" in cfg assert "decode" in cfg self.encode_num = len(cfg["encode"]) encode_list = [] side_list = [] for c in cfg["encode"]: # c: [height, in_ch, mid_ch, out_ch, RSU4F, side] assert len(c) == 6 encode_list.append(RSU(*c[:4]) if c[4] is False else RSU4F(*c[1:4])) # 判断当前是构建RSU模块,还是构建RSU4F模块 if c[5] is True: side_list.append(nn.Conv2d(c[3], out_ch, kernel_size=3, padding=1)) self.encode_modules = nn.ModuleList(encode_list) decode_list = [] for c in cfg["decode"]: # c: [height, in_ch, mid_ch, out_ch, RSU4F, side] assert len(c) == 6 decode_list.append(RSU(*c[:4]) if c[4] is False else RSU4F(*c[1:4])) if c[5] is True: side_list.append(nn.Conv2d(c[3], out_ch, kernel_size=3, padding=1)) # 收集当前block的输出 self.decode_modules = nn.ModuleList(decode_list) self.side_modules = nn.ModuleList(side_list) self.out_conv = nn.Conv2d(self.encode_num * out_ch, out_ch, kernel_size=1) # 构建一个1x1的卷积层,去融合来自不同尺度的信息 def forward(self, x: torch.Tensor) -> Union[torch.Tensor, List[torch.Tensor]]: _, _, h, w = x.shape # collect encode outputs encode_outputs = [] for i, m in enumerate(self.encode_modules): x = m(x) encode_outputs.append(x) if i != self.encode_num - 1: # 此处需要进行判断,因为在没通过一个encoder模块后,都需要进行下采样的,但最后一个模块后,是不需要下采样的 x = F.max_pool2d(x, kernel_size=2, stride=2, ceil_mode=True) # collect decode outputs x = encode_outputs.pop() decode_outputs = [x] for m in self.decode_modules: x2 = encode_outputs.pop() x = F.interpolate(x, size=x2.shape[2:], mode='bilinear', align_corners=False) x = m(torch.concat([x, x2], dim=1)) decode_outputs.insert(0, x) # collect side outputs side_outputs = [] for m in self.side_modules: x = decode_outputs.pop() x = F.interpolate(m(x), size=[h, w], mode='bilinear', align_corners=False) side_outputs.insert(0, x) x = self.out_conv(torch.concat(side_outputs, dim=1)) if self.training: # do not use torch.sigmoid for amp safe return [x] + side_outputs # 用于计算损失 else: return torch.sigmoid(x)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
损失函数计算

如上图所示,红色框部分为每个分量与真实标签的交叉熵损失函数求和;黄色框标部分为将各个分量经双线性插值恢复至原始尺寸、进行concant处理、经过1x1的卷积核与sigmoid处理后的结果与真实标签的交叉熵损失函数。
损失函数代码实现:import math import torch from torch.nn import functional as F import train_utils.distributed_utils as utils def criterion(inputs, target): losses = [F.binary_cross_entropy_with_logits(inputs[i], target) for i in range(len(inputs))] total_loss = sum(losses) return total_loss- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
评价指标

其中F-measure是在0~1之间的,数值越大,代表的网络分割效果越好;
MAE是Mean Absolute Error的缩写,其值是在0~1之间的,越趋近于0,代表网络性能越好。数据集


pytorch训练U2Net图像分割模型
项目目录结构:
├── src: 搭建网络相关代码 ├── train_utils: 训练以及验证相关代码 ├── my_dataset.py: 自定义数据集读取相关代码 ├── predict.py: 简易的预测代码 ├── train.py: 单GPU或CPU训练代码 ├── train_multi_GPU.py: 多GPU并行训练代码 ├── validation.py: 单独验证模型相关代码 ├── transforms.py: 数据预处理相关代码 └── requirements.txt: 项目依赖- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
项目目录:

项目中u2net_full大小为176.3M、u2net_lite大小为4.7M,演示过程中,训练的为u2net_lite版本
多GPU训练指令:
pytorch版本为1.7CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 --use_env train_multi_GPU.py --data-path ./data_root- 1
训练过程损失函数,评估指标变化[epoch: 0] train_loss: 3.0948 lr: 0.000500 MAE: 0.263 maxF1: 0.539 [epoch: 10] train_loss: 1.1108 lr: 0.000998 MAE: 0.111 maxF1: 0.729 [epoch: 20] train_loss: 0.8480 lr: 0.000993 MAE: 0.093 maxF1: 0.764 [epoch: 30] train_loss: 0.7438 lr: 0.000984 MAE: 0.086 maxF1: 0.776 [epoch: 40] train_loss: 0.6625 lr: 0.000971 MAE: 0.082 maxF1: 0.790 [epoch: 50] train_loss: 0.5897 lr: 0.000954 MAE: 0.077 maxF1: 0.801 [epoch: 60] train_loss: 0.5273 lr: 0.000934 MAE: 0.071 maxF1: 0.808 [epoch: 70] train_loss: 0.5139 lr: 0.000911 MAE: 0.079 maxF1: 0.787 [epoch: 80] train_loss: 0.4775 lr: 0.000885 MAE: 0.073 maxF1: 0.801 [epoch: 90] train_loss: 0.4601 lr: 0.000855 MAE: 0.069 maxF1: 0.809 [epoch: 100] train_loss: 0.4529 lr: 0.000823 MAE: 0.065 maxF1: 0.805 [epoch: 110] train_loss: 0.4441 lr: 0.000788 MAE: 0.068 maxF1: 0.810 [epoch: 120] train_loss: 0.3991 lr: 0.000751 MAE: 0.066 maxF1: 0.806 [epoch: 130] train_loss: 0.3903 lr: 0.000712 MAE: 0.065 maxF1: 0.824 [epoch: 140] train_loss: 0.3770 lr: 0.000672 MAE: 0.060 maxF1: 0.823 [epoch: 150] train_loss: 0.3666 lr: 0.000630 MAE: 0.064 maxF1: 0.825 [epoch: 160] train_loss: 0.3530 lr: 0.000587 MAE: 0.060 maxF1: 0.829 [epoch: 170] train_loss: 0.3557 lr: 0.000544 MAE: 0.063 maxF1: 0.820 [epoch: 180] train_loss: 0.3430 lr: 0.000500 MAE: 0.065 maxF1: 0.816 [epoch: 190] train_loss: 0.3366 lr: 0.000456 MAE: 0.059 maxF1: 0.832 [epoch: 200] train_loss: 0.3285 lr: 0.000413 MAE: 0.062 maxF1: 0.822 [epoch: 210] train_loss: 0.3197 lr: 0.000370 MAE: 0.058 maxF1: 0.829 [epoch: 220] train_loss: 0.3093 lr: 0.000328 MAE: 0.058 maxF1: 0.828 [epoch: 230] train_loss: 0.3071 lr: 0.000288 MAE: 0.058 maxF1: 0.827 [epoch: 240] train_loss: 0.2983 lr: 0.000249 MAE: 0.056 maxF1: 0.830 [epoch: 250] train_loss: 0.2932 lr: 0.000212 MAE: 0.060 maxF1: 0.825 [epoch: 260] train_loss: 0.2908 lr: 0.000177 MAE: 0.060 maxF1: 0.828 [epoch: 270] train_loss: 0.2895 lr: 0.000145 MAE: 0.057 maxF1: 0.832 [epoch: 280] train_loss: 0.2834 lr: 0.000115 MAE: 0.057 maxF1: 0.832 [epoch: 290] train_loss: 0.2762 lr: 0.000089 MAE: 0.056 maxF1: 0.833 [epoch: 300] train_loss: 0.2760 lr: 0.000066 MAE: 0.056 maxF1: 0.832 [epoch: 310] train_loss: 0.2752 lr: 0.000046 MAE: 0.057 maxF1: 0.832 [epoch: 320] train_loss: 0.2782 lr: 0.000029 MAE: 0.056 maxF1: 0.834 [epoch: 330] train_loss: 0.2744 lr: 0.000016 MAE: 0.056 maxF1: 0.832 [epoch: 340] train_loss: 0.2752 lr: 0.000007 MAE: 0.056 maxF1: 0.832 [epoch: 350] train_loss: 0.2739 lr: 0.000002 MAE: 0.057 maxF1: 0.831 [epoch: 359] train_loss: 0.2770 lr: 0.000000 MAE: 0.056 maxF1: 0.833- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
模型测试
import os import time import cv2 import numpy as np import matplotlib.pyplot as plt import torch from torchvision.transforms import transforms from src import u2net_full,u2net_lite def time_synchronized(): torch.cuda.synchronize() if torch.cuda.is_available() else None return time.time() def main(): weights_path = "./multi_train/model_best.pth" img_path = "./test_image.PNG" threshold = 0.5 assert os.path.exists(img_path), f"image file {img_path} dose not exists." device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") data_transform = transforms.Compose([ transforms.ToTensor(), transforms.Resize(320), transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)) ]) origin_img = cv2.cvtColor(cv2.imread(img_path, flags=cv2.IMREAD_COLOR), cv2.COLOR_BGR2RGB) h, w = origin_img.shape[:2] img = data_transform(origin_img) img = torch.unsqueeze(img, 0).to(device) # [C, H, W] -> [1, C, H, W] # model = u2net_full() model =u2net_lite() weights = torch.load(weights_path, map_location='cpu') if "model" in weights: model.load_state_dict(weights["model"]) else: model.load_state_dict(weights) model.to(device) model.eval() with torch.no_grad(): # init model img_height, img_width = img.shape[-2:] init_img = torch.zeros((1, 3, img_height, img_width), device=device) model(init_img) t_start = time_synchronized() pred = model(img) t_end = time_synchronized() print("inference time: {}".format(t_end - t_start)) pred = torch.squeeze(pred).to("cpu").numpy() # [1, 1, H, W] -> [H, W] pred = cv2.resize(pred, dsize=(w, h), interpolation=cv2.INTER_LINEAR) pred_mask = np.where(pred > threshold, 1, 0) origin_img = np.array(origin_img, dtype=np.uint8) seg_img = origin_img * pred_mask[..., None] plt.imshow(seg_img) plt.show() cv2.imwrite("pred_result.png", cv2.cvtColor(seg_img.astype(np.uint8), cv2.COLOR_RGB2BGR)) if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72

训练的为u2net_full版本
训练指标如下:[epoch: 0] train_loss: 2.7158 lr: 0.000500 MAE: 0.216 maxF1: 0.583 [epoch: 10] train_loss: 1.0359 lr: 0.000998 MAE: 0.105 maxF1: 0.745 [epoch: 20] train_loss: 0.7130 lr: 0.000993 MAE: 0.087 maxF1: 0.778 [epoch: 30] train_loss: 0.5375 lr: 0.000984 MAE: 0.077 maxF1: 0.810 [epoch: 40] train_loss: 0.4661 lr: 0.000971 MAE: 0.069 maxF1: 0.826 [epoch: 50] train_loss: 0.4181 lr: 0.000954 MAE: 0.065 maxF1: 0.823 [epoch: 60] train_loss: 0.3914 lr: 0.000934 MAE: 0.065 maxF1: 0.826 [epoch: 70] train_loss: 0.3353 lr: 0.000911 MAE: 0.059 maxF1: 0.840 [epoch: 80] train_loss: 0.2847 lr: 0.000885 MAE: 0.058 maxF1: 0.835 [epoch: 90] train_loss: 0.2977 lr: 0.000855 MAE: 0.056 maxF1: 0.843 [epoch: 100] train_loss: 0.2538 lr: 0.000823 MAE: 0.054 maxF1: 0.848 [epoch: 110] train_loss: 0.2653 lr: 0.000788 MAE: 0.052 maxF1: 0.848 [epoch: 120] train_loss: 0.2365 lr: 0.000751 MAE: 0.052 maxF1: 0.841 [epoch: 130] train_loss: 0.2397 lr: 0.000712 MAE: 0.056 maxF1: 0.843 [epoch: 140] train_loss: 0.2180 lr: 0.000672 MAE: 0.051 maxF1: 0.854 [epoch: 150] train_loss: 0.2060 lr: 0.000630 MAE: 0.051 maxF1: 0.853 [epoch: 160] train_loss: 0.2002 lr: 0.000587 MAE: 0.052 maxF1: 0.853 [epoch: 170] train_loss: 0.1952 lr: 0.000544 MAE: 0.050 maxF1: 0.859 [epoch: 180] train_loss: 0.1893 lr: 0.000500 MAE: 0.053 maxF1: 0.851 [epoch: 190] train_loss: 0.1838 lr: 0.000456 MAE: 0.050 maxF1: 0.852 [epoch: 200] train_loss: 0.1779 lr: 0.000413 MAE: 0.049 maxF1: 0.858 [epoch: 210] train_loss: 0.1745 lr: 0.000370 MAE: 0.052 maxF1: 0.851 [epoch: 220] train_loss: 0.1703 lr: 0.000328 MAE: 0.050 maxF1: 0.854 [epoch: 230] train_loss: 0.1667 lr: 0.000288 MAE: 0.049 maxF1: 0.855 [epoch: 240] train_loss: 0.1640 lr: 0.000249 MAE: 0.049 maxF1: 0.855 [epoch: 250] train_loss: 0.1618 lr: 0.000212 MAE: 0.049 maxF1: 0.855 [epoch: 260] train_loss: 0.1598 lr: 0.000177 MAE: 0.048 maxF1: 0.856 [epoch: 270] train_loss: 0.1580 lr: 0.000145 MAE: 0.049 maxF1: 0.856 [epoch: 280] train_loss: 0.1572 lr: 0.000115 MAE: 0.049 maxF1: 0.853 [epoch: 290] train_loss: 0.1561 lr: 0.000089 MAE: 0.047 maxF1: 0.857 [epoch: 300] train_loss: 0.1550 lr: 0.000066 MAE: 0.047 maxF1: 0.858 [epoch: 310] train_loss: 0.1543 lr: 0.000046 MAE: 0.048 maxF1: 0.854 [epoch: 320] train_loss: 0.1539 lr: 0.000029 MAE: 0.048 maxF1: 0.854- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35

-
相关阅读:
湘乡秸秆综合利用组合拳完善产业链 国稻种芯现代饲料规划
HTML5+CSSday4综合案例二——banner效果
力扣labuladong一刷day14天翻转单链表共2题
【Router】PC连接到路由LAN,但是无法获取到IP地址问题分析及解决方案
[附源码]Python计算机毕业设计Django教务管理系统
CSP 2020 入门级第一轮1~17题解析
MW:3400 4-Arm PEG-DSPE 四臂-聚乙二醇-磷脂一种饱和的18碳磷脂
用C++标准库生成制定范围内的整数随机数
基于FPGA的电风扇控制器verilog,视频/代码
数据结构— —哈希表顺序实现
- 原文地址:https://blog.csdn.net/guoqingru0311/article/details/133814862