-
从Flink的Kafka消费者看算子联合列表状态的使用
背景
算子的联合列表状态是平时使用的比较少的一种状态,本文通过kafka的消费者实现来看一下怎么使用算子列表联合状态
算子联合列表状态
首先我们看一下算子联合列表状态的在进行故障恢复或者从某个保存点进行扩缩容启动应用时状态的恢复情况
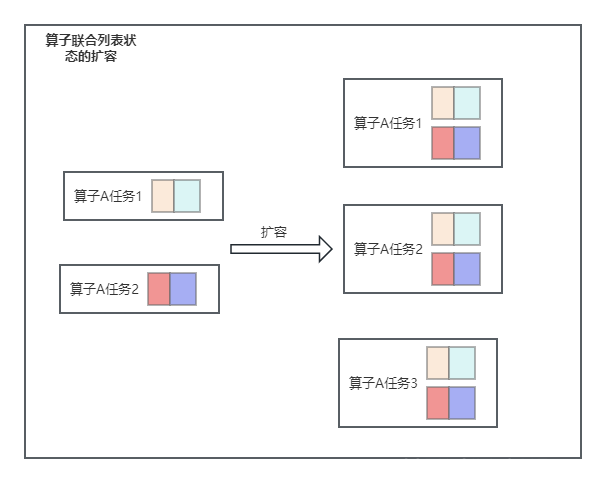
算子联合列表状态主要由这两个方法处理:
1初始化方法public final void initializeState(FunctionInitializationContext context) throws Exception { OperatorStateStore stateStore = context.getOperatorStateStore(); // 在初始化方法中获取联合列表状态 this.unionOffsetStates = stateStore.getUnionListState( new ListStateDescriptor<>( OFFSETS_STATE_NAME, createStateSerializer(getRuntimeContext().getExecutionConfig()))); if (context.isRestored()) { restoredState = new TreeMap<>(new KafkaTopicPartition.Comparator()); // 把联合列表状态的数据都恢复成类的本地变量中 // populate actual holder for restored state for (Tuple2<KafkaTopicPartition, Long> kafkaOffset : unionOffsetStates.get()) { restoredState.put(kafkaOffset.f0, kafkaOffset.f1); } LOG.info( "Consumer subtask {} restored state: {}.", getRuntimeContext().getIndexOfThisSubtask(), restoredState); } else { LOG.info( "Consumer subtask {} has no restore state.", getRuntimeContext().getIndexOfThisSubtask()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
2.开始通知检查点开始的方法:
public final void snapshotState(FunctionSnapshotContext context) throws Exception { if (!running) { LOG.debug("snapshotState() called on closed source"); } else { unionOffsetStates.clear(); final AbstractFetcher<?, ?> fetcher = this.kafkaFetcher; if (fetcher == null) { // the fetcher has not yet been initialized, which means we need to return the // originally restored offsets or the assigned partitions for (Map.Entry<KafkaTopicPartition, Long> subscribedPartition : subscribedPartitionsToStartOffsets.entrySet()) { // 进行checkpoint时,把数据保存到联合列表状态中进行保存 unionOffsetStates.add( Tuple2.of( subscribedPartition.getKey(), subscribedPartition.getValue())); } if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) { // the map cannot be asynchronously updated, because only one checkpoint call // can happen // on this function at a time: either snapshotState() or // notifyCheckpointComplete() pendingOffsetsToCommit.put(context.getCheckpointId(), restoredState); } } else { HashMap<KafkaTopicPartition, Long> currentOffsets = fetcher.snapshotCurrentState(); if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) { // the map cannot be asynchronously updated, because only one checkpoint call // can happen // on this function at a time: either snapshotState() or // notifyCheckpointComplete() pendingOffsetsToCommit.put(context.getCheckpointId(), currentOffsets); } for (Map.Entry<KafkaTopicPartition, Long> kafkaTopicPartitionLongEntry : currentOffsets.entrySet()) { unionOffsetStates.add( Tuple2.of( kafkaTopicPartitionLongEntry.getKey(), kafkaTopicPartitionLongEntry.getValue())); } } if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) { // truncate the map of pending offsets to commit, to prevent infinite growth while (pendingOffsetsToCommit.size() > MAX_NUM_PENDING_CHECKPOINTS) { pendingOffsetsToCommit.remove(0); } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
-
相关阅读:
Python对数据进行分类统计
多测师肖sir_高级金牌讲师__git讲解
二叉树题目:从前序与中序遍历序列构造二叉树
如何知道当前ubuntu的版本
LabVIEW中的自动保存功能
数据库例题精选
C语言中的文件操作指南
Mac运行Docker报错
【问答】入职一家新公司,需要重头搭建自动化测试框架,该如何开始呢?
xcode15出现大量Duplicate symbols
- 原文地址:https://blog.csdn.net/lixia0417mul2/article/details/133850371
