-
JVM字节码指令详解
前言
在我们日常的Java开发中,我们的IDE开发工具会自动的通过编译器将Java代码编译成字节码文件,最后通过JVM来执行这些字节码文件。在这个过程中,一个重要的环节就是Java字节码。Java字节码是Java虚拟机(JVM)可以执行的指令集,它在一定程度上代表了Java的跨平台特性,因为不同的操作系统平台上的JVM都可以执行相同的Java字节码。因此,深入理解Java字节码对于掌握Java的运行机制是非常重要的。
在本篇博文中,我将对JVM字节码的基础知识、指令类型、命名规则以及优化策略等方面进行详细的讲解。我和大家一起更好地理解JVM的工作原理,同时也能够在实际开发中遇到性能问题时,能够更好地进行问题定位和性能调优。本文假设读者已经有一定的Java基础,并且熟悉基本的计算机原理,例如栈、堆等基本概念。如果你对这些还不是很熟悉,建议先补充相关的基础知识。
一、JVM字节码指令概述
1. 什么是JVM字节码指令:
JVM字节码指令是Java Virtual Machine(JVM)在执行Java程序时所遵循的一种低级指令集。在Java应用程序编译为.class文件后,存储在文件中的就是这些字节码指令。这些指令是在Java虚拟机上运行的,与具体的操作系统和硬件无关,实现了Java语言的“一次编译,到处运行”的特性。
2. 字节码指令的作用:
JVM字节码指令的主要作用是定义了执行Java类或者接口中方法的操作语义,包括如何加载数据,如何存储数据,如何操作数据,如何控制流程等等。同时,字节码还能保证Java程序在不同的平台上都能得到正确且一致的执行效果。
3. 字节码指令的分类:
参考Oracle官网 Chapter 6. The Java Virtual Machine Instruction Set
JVM字节码指令大致可以分为以下几类:- 加载指令(Load):用于把变量从主存加载到栈内存。
- 存储指令(Store):用于把变量从栈内存存储到主存。
- 栈操作指令(Stack):用于对栈进行操作,比如交换栈顶元素,复制栈顶元素等。
- 算术指令(Arithmetic):用于进行算术运算,比如加法,减法,乘法,除法等。
- 转换指令(Conversion):用于进行类型转换,比如将int类型转为float类型等。
- 比较指令(Comparison):用于进行数值比较。
- 控制指令(Control):用于进行控制流转移。
- 引用指令(Reference):用于操作对象,比如创建对象,获取对象的字段等。
- 扩展指令(Extended):用于对指令集进行扩展。
- 同步指令(Synchronization):用于线程同步。
二、字节码指令的种类
我们使用一个简单的Java类然后使用
javap -c 类名输出字节码指令,来分析一下public class HelloByteCode { private int num; private String str; public HelloByteCode(int num, String str) { this.num = num; this.str = str; } public int addNum(int add) { return this.num + add; } public String appendStr(String append) { return this.str + append; } public static void main(String[] args) { HelloByteCode helloByteCode = new HelloByteCode(10, "Hello"); int resultNum = helloByteCode.addNum(20); String resultStr = helloByteCode.appendStr(" ByteCode"); System.out.println(resultNum); System.out.println(resultStr); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
使用Java的javap工具输出它的字节码指令。在命令行中输入
javap -c HelloByteCode,将得到下面的结果:public class HelloByteCode { // 构造函数 public HelloByteCode(int, java.lang.String); Code: 0: aload_0 // 将第一个引用类型本地变量加载到操作数栈顶 1: invokespecial #1 // 调用超类构造函数,实例初始化 4: aload_0 // 将第一个引用类型本地变量加载到操作数栈顶 5: iload_1 // 将第二个int类型本地变量加载到操作数栈顶 6: putfield #2 // 将栈顶的数值存入到对象的num字段 9: aload_0 // 将第一个引用类型本地变量加载到操作数栈顶 10: aload_2 // 将第三个引用类型本地变量加载到操作数栈顶 11: putfield #3 // 将栈顶的数值存入到对象的str字段 14: return // 返回 // 方法:加数 public int addNum(int); Code: 0: aload_0 // 将第一个引用类型本地变量加载到操作数栈顶 1: getfield #2 // 获取对象的num字段值 4: iload_1 // 将第二个int类型本地变量加载到操作数栈顶 5: iadd // 执行加法操作 6: ireturn // 返回int值 // 方法:拼接字符串 public java.lang.String appendStr(java.lang.String); Code: 0: new #4 // 创建一个StringBuilder对象 3: dup // 复制栈顶元素并压入栈顶 4: invokespecial #5 // 调用StringBuilder构造函数,实例初始化 7: aload_0 // 将第一个引用类型本地变量加载到操作数栈顶 8: getfield #3 // 获取对象的str字段值 11: invokevirtual #6 // 调用StringBuilder的append方法 14: aload_1 // 将第二个引用类型本地变量加载到操作数栈顶 15: invokevirtual #6 // 调用StringBuilder的append方法 18: invokevirtual #7 // 调用StringBuilder的toString方法 21: areturn // 返回引用类型值 // 主函数 public static void main(java.lang.String[]); Code: 0: new #8 // 创建一个HelloByteCode对象 3: dup // 复制栈顶元素并压入栈顶 4: bipush 10 // 将int类型常量10压入栈顶 6: ldc #9 // 将String类型常量"Hello"压入栈顶 8: invokespecial #10 // 调用HelloByteCode构造函数,实例初始化 11: astore_1 // 将栈顶引用类型值存入第二个本地变量 12: aload_1 // 将第二个引用类型本地变量加载到操作数栈顶 13: bipush 20 // 将int类型常量20压入栈顶 15: invokevirtual #11 // 调用HelloByteCode的addNum方法 18: istore_2 // 将栈顶int类型值存入第三个本地变量 19: aload_1 // 将第二个引用类型本地变量加载到操作数栈顶 20: ldc #12 // 将String类型常量" ByteCode"压入栈顶 22: invokevirtual #13 // 调用HelloByteCode的appendStr方法 25: astore_3 // 将栈顶引用类型值存入第四个本地变量 26: getstatic #14 // 获取System.out静态字段值 29: iload_2 // 将第三个int类型本地变量加载到操作数栈顶 30: invokevirtual #15 // 调用PrintStream的println方法 33: getstatic #14 // 获取System.out静态字段值 36: aload_3 // 将第四个引用类型本地变量加载到操作数栈顶 37: invokevirtual #16 // 调用PrintStream的println方法 40: return // 返回 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
这里的每一行是一条字节码指令,如
aload_0是将第一个引用类型本地变量加载到操作数栈顶,putfield是将栈顶的数值存入到对象的字段中,iadd是将栈顶两个int类型数值相加并将结果压入栈顶,等等。其实jvm的指令是可以分为9类。我们都分别了解一下。
1. 加载和存储指令
加载和存储指令是Java字节码中的一种类型,主要用于从本地变量表中加载值到操作数栈,或者将操作数栈的值存储到本地变量表中。这里的值可以是基本类型,也可以是引用类型。
以下是Java字节码中加载和存储指令的一部分:指令 描述 aload 将引用类型本地变量加载到操作数栈顶 aload_0 将第一个引用类型本地变量加载到操作数栈顶 aload_1 将第二个引用类型本地变量加载到操作数栈顶 aload_2 将第三个引用类型本地变量加载到操作数栈顶 aload_3 将第四个引用类型本地变量加载到操作数栈顶 astore 将栈顶引用类型数值存入本地变量 astore_0 将栈顶引用类型数值存入第一个本地变量 astore_1 将栈顶引用类型数值存入第二个本地变量 astore_2 将栈顶引用类型数值存入第三个本地变量 astore_3 将栈顶引用类型数值存入第四个本地变量 iload 将int类型本地变量加载到操作数栈顶 iload_0 将第一个int类型本地变量加载到操作数栈顶 iload_1 将第二个int类型本地变量加载到操作数栈顶 iload_2 将第三个int类型本地变量加载到操作数栈顶 iload_3 将第四个int类型本地变量加载到操作数栈顶 istore 将栈顶int类型数值存入本地变量 istore_0 将栈顶int类型数值存入第一个本地变量 istore_1 将栈顶int类型数值存入第二个本地变量 istore_2 将栈顶int类型数值存入第三个本地变量 istore_3 将栈顶int类型数值存入第四个本地变量 对于其他类型(如long,float,double),也有相应的lload,lstore,fload,fstore,dload,dstore等指令。
2. 算术指令
以下是Java字节码中的一些算术指令:
指令 描述 iadd 将栈顶两int类型数值相加并将结果压入栈顶 ladd 将栈顶两long类型数值相加并将结果压入栈顶 fadd 将栈顶两float类型数值相加并将结果压入栈顶 dadd 将栈顶两double类型数值相加并将结果压入栈顶 isub 将栈顶两int类型数值相减并将结果压入栈顶 lsub 将栈顶两long类型数值相减并将结果压入栈顶 fsub 将栈顶两float类型数值相减并将结果压入栈顶 dsub 将栈顶两double类型数值相减并将结果压入栈顶 imul 将栈顶两int类型数值相乘并将结果压入栈顶 lmul 将栈顶两long类型数值相乘并将结果压入栈顶 fmul 将栈顶两float类型数值相乘并将结果压入栈顶 dmul 将栈顶两double类型数值相乘并将结果压入栈顶 idiv 将栈顶两int类型数值相除并将结果压入栈顶 ldiv 将栈顶两long类型数值相除并将结果压入栈顶 fdiv 将栈顶两float类型数值相除并将结果压入栈顶 ddiv 将栈顶两double类型数值相除并将结果压入栈顶 这些只是算术指令的一部分,还有很多其他的算术指令,如irem(取余),ineg(取负)等。
以下是Java字节码中各类别指令的一部分:3. 类型转换指令
指令 描述 i2l 将栈顶int类型数值转换为long类型并压入栈顶 i2f 将栈顶int类型数值转换为float类型并压入栈顶 i2d 将栈顶int类型数值转换为double类型并压入栈顶 4. 对象和数组操作指令
指令 描述 new 创建一个对象,并将引用值压入栈顶 anewarray 创建一个引用类型数组,并将引用值压入栈顶 arraylength 获取数组的长度值,并将长度值压入栈顶 5. 操作数栈管理指令
指令 描述 pop 弹出栈顶数值 pop2 弹出栈顶的一个或两个数值 dup 复制栈顶数值并压入栈顶 6. 控制转移指令
指令 描述 ifeq 当栈顶int类型数值等于0时跳转 ifne 当栈顶int类型数值不等于0时跳转 goto 无条件跳转 7. 方法调用和返回指令
指令 描述 invokevirtual 调用实例方法 invokespecial 调用构造函数,私有方法和父类方法 invokestatic 调用静态方法 return 从当前方法返回void 8. 异常处理指令
指令 描述 athrow 将栈顶的异常抛出 9. 同步指令
指令 描述 monitorenter 获取对象的锁 monitorexit 释放对象的锁 学到了这些指令后,我们尝试的解析一下这个java类生成的字节码指令
下面是一个复杂的Java类(一个简单的计数器)及其对应的一部分字节码指令:Java代码:
public class Counter { private int count = 0; public int getCount() { return count; } public void increment() { count++; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
对应的字节码指令(只展示了部分):
0: aload_0 1: dup 2: getfield #2 // Field count:I 5: iconst_1 6: iadd 7: putfield #2 // Field count:I 10: return- 1
- 2
- 3
- 4
- 5
- 6
- 7
说明:
aload_0:将局部变量表的第0个局部变量加载到操作数栈顶,这里的局部变量0是this。dup:复制栈顶的一个元素并将复制的元素重新压入栈顶。getfield:从对象中取出一个字段的值,这里是取出count字段的值。iconst_1:将int型常量1推送到操作数栈顶。
-iadd:将栈顶的两个int型数值出栈,相加,然后将结果入栈。putfield:将栈顶的一个值(即iadd的结果)存储到对象的字段中,这里是存储到count字段。return:从当前方法返回。
总结一下指令命名规律
JVM字节码指令(opcode)的命名有其特点和规律,总结一些常见的命名技巧和规律:
通过命名规律,可以更容易地理解JVM字节码指令的含义和功能。1. 操作数类型前缀
字节码指令通常以一个字符作为前缀,表示操作数的类型。这些字符包括:
i:表示操作数是int类型。l:表示操作数是long类型。f:表示操作数是float类型。d:表示操作数是double类型。a:表示操作数是对象引用类型。b:表示操作数是byte类型。c:表示操作数是char类型。s:表示操作数是short类型。
例如:
iload表示加载一个int类型的局部变量,fadd表示将两个float类型的值相加。2. 指令的操作:
load:加载操作,通常表示从局部变量表或数组中加载一个值到操作数栈。store:存储操作,通常表示将一个值从操作数栈存储到局部变量表或数组中。add、sub、mul、div、rem:分别表示加、减、乘、除和取余运算。and、or、xor:分别表示位与、位或和位异或运算。neg:表示取反操作。shl、shr、ushr:分别表示左移、有符号右移和无符号右移操作。cmpeq、cmpne、cmplt、cmpge、cmpgt、cmple:表示比较操作。
3. 指令的粒度:
const:用于表示将常量加载到操作数栈。2、3:表示指令操作两个或三个操作数。例如,iadd表示将栈顶两个int值相加,dup2表示复制栈顶两个元素。x:表示指令可以操作多种类型的值。例如,aaload表示从数组中加载一个对象引用,bastore表示将一个byte或boolean值存储到数组中。
4. 数组操作相关:
aload:表示从数组中加载一个元素到操作数栈。astore:表示将一个元素从操作数栈存储到数组中。length:表示获取数组的长度。
5. 控制转移和方法调用:
goto:表示无条件跳转。if:表示条件跳转。return:表示从方法返回。invoke:表示调用方法。
三、字节码指令的详细解读
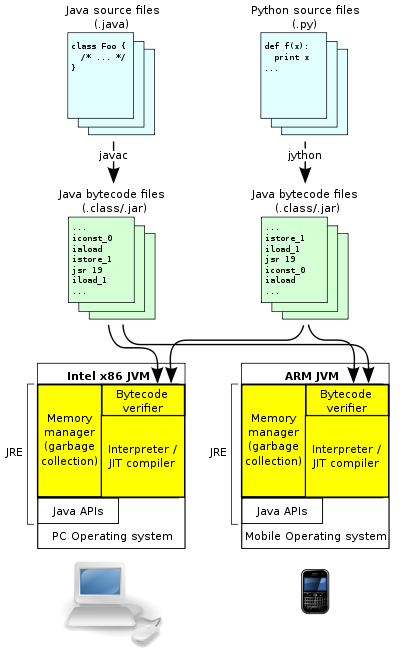
1. JVM如何解析字节码指令
JVM(Java虚拟机)是一个基于栈的解释执行引擎,它通过逐个解析和执行字节码指令来运行Java程序。字节码指令是一种特定于JVM的低级二进制格式,它们将Java源代码的高级表示形式转换为一种更适合计算机执行的格式。在执行字节码之前,JVM首先将Java类加载到内存中,初始化类的静态变量,然后在需要时解析和执行相应的方法。以下是JVM解析字节码指令的过程:
-
类加载:JVM通过类加载器将.class文件加载到内存中,并进行链接和初始化。链接包括验证、准备和解析三个阶段。验证确保字节码符合JVM规范,准备阶段为类变量分配内存并设置初始值,解析阶段将符号引用转换为直接引用。初始化阶段为类变量赋予正确的初始值,并执行类构造器方法。
-
创建线程栈:每个Java线程在JVM中都有一个线程栈,用于存储方法调用所需的数据,包括局部变量、操作数栈和帧数据。线程栈中的每个方法调用都对应一个栈帧。
-
方法调用:当JVM调用一个方法时,会为该方法创建一个新的栈帧,并将其压入线程栈顶。栈帧包含了方法的局部变量表、操作数栈和帧数据。局部变量表用于存储方法的参数和局部变量,操作数栈用于存储计算过程中产生的中间结果,帧数据包含方法返回地址和其他一些元数据。
-
解析指令:JVM逐个解析方法中的字节码指令,根据指令操作码执行相应的操作。这些操作包括但不限于数据加载、存储、算术运算、类型转换、对象创建、方法调用、控制转移等。解析指令时,JVM会根据指令操作数类型和数量获取操作数(如果有),并根据指令语义对局部变量表和操作数栈进行操作。
-
执行指令:JVM根据指令语义执行相应的操作,这可能会导致更改局部变量表、操作数栈或其他系统状态。执行完指令后,JVM将程序计数器(PC)设置为下一条指令的地址,然后继续解析和执行下一条指令。
-
方法返回:当JVM遇到方法返回指令(如return)时,它会将当前栈帧弹出线程栈,并将返回值(如果有)压入调用者的操作数栈。然后,JVM将程序计数器设置为当前方法的返回地址,继续执行调用者的剩余指令。
通过以上过程,JVM能够逐个解析和执行字节码指令,从而完成Java程序的运行。
2. JVM如何执行字节码指令
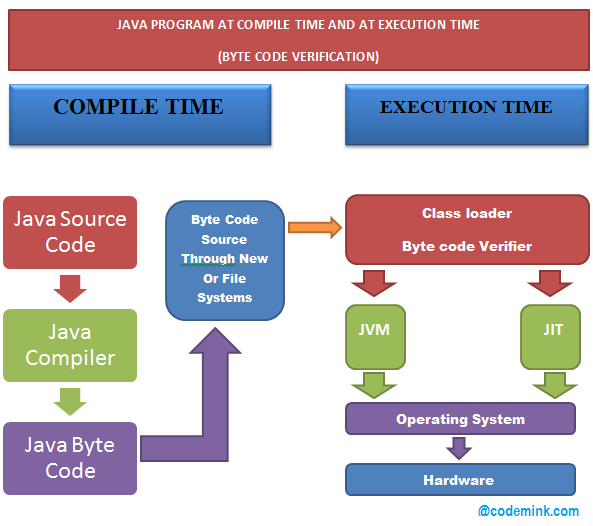
Java虚拟机 它将字节码指令解析和执行过程分为以下几个步骤:
-
加载:首先,JVM将字节码文件(.class文件)加载到内存中。字节码文件是由Java编译器从Java源代码转换而来的。
-
验证:加载完成后,JVM会对字节码指令进行验证,确保它符合JVM的规范、安全且结构正确。
-
预处理:JVM可能会对字节码进行一些预处理操作,例如:解析、优化等。
-
解析与执行:经过预处理后,JVM会开始解析和执行字节码。JVM拥有一个程序计数器(PC寄存器),用以存储下一条需要执行的字节码指令的地址。JVM会根据程序计数器的指示,一条一条地解析并执行字节码指令。解析指令是指把二进制格式的指令转换成JVM可以理解的操作,执行指令则是指按照解析出来的操作进行相应的操作。
例如,对于算术指令,JVM会从操作数栈取出操作数,执行相应的算术操作,并将结果压回操作数栈。对于方法调用指令,JVM会调度相应的方法,并为该方法创建一个新的栈帧。对于跳转指令,JVM会修改程序计数器的值,使其指向跳转目标的地址。
-
管理内存:在执行过程中,JVM还负责管理内存。根据字节码指令的需要,JVM会在堆中分配或回收对象的内存。
-
处理异常:如果在执行字节码指令过程中发生异常,JVM会寻找合适的异常处理器来处理它。
四、字节码工具的使用
1. 如何使用javap查看字节码
javap是Java官方提供的一个命令行工具,用于反编译已编译的Java类文件,输出字节码指令。要使用javap查看字节码,请按照以下步骤操作:
-
打开命令行窗口(在Windows上可以使用cmd,Linux和Mac上可以使用Terminal)。
-
定位到目标类文件所在的目录。例如,如果目标类文件在D:\MyJavaProject\out\production\MyJavaProject目录下,可以使用以下命令导航到该目录:
cd D:\MyJavaProject\out\production\MyJavaProject- 1
- 使用javap命令查看字节码。以下是一些常用的选项:
-c:输出字节码指令。-p:输出私有属性和方法。-l:输出行号和局部变量表。-v:输出详细信息。
例如,要查看名为MyClass的类的字节码,可以使用以下命令:
javap -c -p -l -v MyClass- 1
这将输出MyClass类的字节码指令、私有属性、方法、行号和局部变量表等信息。
2. 如何使用ASM等工具修改字节码
ASM是一个Java字节码操作和分析框架,可以用来动态生成、修改和分析Java类文件。以下是一个使用ASM修改字节码的简单示例:
- 添加ASM依赖。在Maven项目中,可以在pom.xml文件中添加以下依赖:
<dependency> <groupId>org.ow2.asmgroupId> <artifactId>asmartifactId> <version>9.1version> dependency>- 1
- 2
- 3
- 4
- 5
- 使用ASM Core API进行字节码修改。以下是一个简单的例子,使用ASM将一个类的方法返回值修改为42:
import org.objectweb.asm.*; import java.io.FileInputStream; import java.io.FileOutputStream; public class AsmDemo { public static void main(String[] args) throws Exception { // 读取并修改字节码 ClassReader classReader = new ClassReader(new FileInputStream("MyClass.class")); ClassWriter classWriter = new ClassWriter(classReader, 0); MyClassModifier classModifier = new MyClassModifier(); classReader.accept(classModifier, 0); // 将修改后的字节码写入文件 byte[] modifiedClassByteArray = classWriter.toByteArray(); try (FileOutputStream fos = new FileOutputStream("MyClassModified.class")) { fos.write(modifiedClassByteArray); } } static class MyClassModifier extends ClassVisitor { public MyClassModifier() { super(Opcodes.ASM9); } @Override public MethodVisitor visitMethod(int access, String name, String descriptor, String signature, String[] exceptions) { MethodVisitor mv = super.visitMethod(access, name, descriptor, signature, exceptions); return new MethodModifier(mv); } } static class MethodModifier extends MethodVisitor { public MethodModifier(MethodVisitor methodVisitor) { super(Opcodes.ASM9, methodVisitor); } @Override public void visitInsn(int opcode) { // 将方法的返回值修改为42(int类型) if (opcode == Opcodes.IRETURN) { super.visitLdcInsn(42); } super.visitInsn(opcode); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
3. 如何使用JIT编译器优化字节码
JIT(Just-In-Time)编译器是Java虚拟机的一个组件,用于将字节码动态编译为本地机器代码,以提高程序执行速度。JIT编译器在运行时自动优化热点代码(即执行频繁的代码片段),无需手动启用或配置。
然而,可以使用一些JVM参数来控制JIT编译器的行为。以下是一些常用的JIT编译器选项:
-XX:+PrintCompilation:输出JIT编译过程中的日志信息。-XX:CompileThreshold:设置触发JIT编译的方法调用次数阈值(默认值为10000)。-XX:ReservedCodeCacheSize:设置JIT编译器的代码缓存大小,可以调整此值以改善性能。
例如,要启用JIT编译器日志,并将编译阈值设置为5000,可以在启动Java程序时添加以下JVM参数:
java -XX:+PrintCompilation -XX:CompileThreshold=5000 MyClass- 1
JIT编译器的优化是透明的,通常无需手动干预。在实际应用中,可能需要根据具体场景和性能需求调整JVM参数。
五、字节码指令的优化策略
1. 常量折叠优化:
常量折叠是一种编译器的优化技术,旨在计算和简化在编译时期已知的常量表达式。例如,对于表达式2+3,编译器在编译时就可以直接将其计算为5,而不必等到运行时。
2. 代码重排序优化:
代码重排序是一种优化策略,它通过调整指令的执行顺序,来提高指令的并行度以提高程序运行效率。但是需要注意的是,代码重排序不能改变程序的语义,也就是说,重排序后的代码执行结果必须与原始代码一致。
3. 常量传播优化:
常量传播是一种编译器优化技术,通过跟踪程序中的常量赋值语句,将这些常量传播到他们可能被使用的地方。这样可以避免运行时的查找或计算常量值的操作,提高程序运行效率。
4. 公共子表达式消除:
公共子表达式消除是一种编译器优化技术,旨在找出并消除在多个位置重复出现的表达式。通过避免重复计算相同的表达式,可以显著提高程序的运行效率。
5. 死代码消除:
死代码是指在程序运行过程中永远不会被执行到的代码。死代码消除就是找出并删除这些代码,从而减少程序的大小,并稍微提高程序的运行效率。
六、字节码指令的实际应用
- AOP编程
- 动态代理
- ORM框架
- 热部署
7.参考文档
- https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-6.html
- https://en.wikipedia.org/wiki/List_of_Java_bytecode_instructions
- https://blog.jamesdbloom.com/JVMInternals.html
-
相关阅读:
浅析vue的createApp方法
Met no ‘TRANSLATIONS’ entry in project
STM32物联网项目-GPRS模块通信编程
软件测试 - 项目实战篇
箭头函数
远端rostopic的本地rviz调用及显示
ke8学校陈老师H5
9.spark自适应查询-AQE之动态调整Join策略
基于matlab实现的中点放炮各类地震波时距曲线程序
龙迅LT2611UX—LVDS至HDMI2.0转换器概述资料分享
- 原文地址:https://blog.csdn.net/wangshuai6707/article/details/133828914