-
sklearn处理离散变量的问题——以决策树为例
最近做项目遇到的数据集中,有许多高维类别特征。catboost是可以直接指定categorical_columns的【直接进行ordered TS编码】,但是XGboost和随机森林甚至决策树都没有这个接口。但是在学习决策树的时候(无论是ID3、C4.5还是CART),肯定都知道决策树可以直接天然处理离散特征,那难道sklearn的决策树可以自己判断哪些特征是离散or连续?
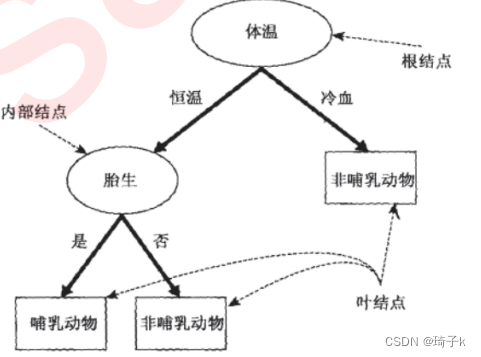
决策树怎么处理连续特征
首先要明确,分类树和回归树,只是看label值是类别型还是连续型,和特征中是离散还是连续没有关系。并不是说CART回归树不能使用离散的特征,只是CART回归树里并不使用gini系数来计算增益。【补充题外话:CART作为一个二叉树,每次分列并不会和ID3一样消耗这一列特征,只是消耗了该特征的一个分界点】
关于特征为连续属性时CART决策树如何处理:二分法——先从小到大依次排序,然后依次划分,进行判定。具体可以参考这篇博客。
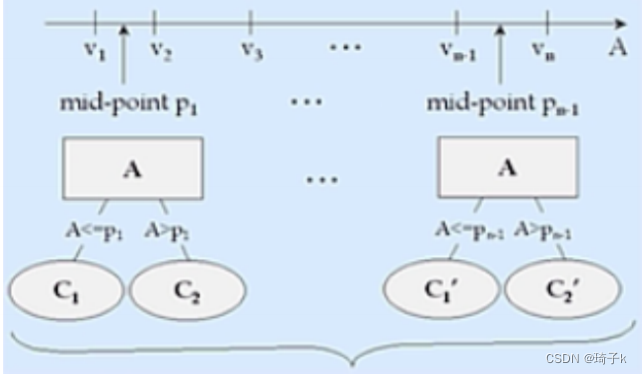
sklearn里的决策树怎么处理类别特征的
答案是——不处理。在sklearn实现的CART树中,是用同一种方式去处理离散与连续的特征的,即:把离散的特征也都当做连续的处理了,只能处理连续特征 和 做编码成数字的离散特征。


可以看这个问题,我的理解是sklearn为了速度对CART的原来算法做了一定的改进,不再按照原来的方法处理离散特征,而是都统一成连续特征来处理了【所以没有categorical_columns接口】。
其实理论上来说,XGB是可以用离散变量的,毕竟增益只和结点上的样本有关,特征只是决定树的结构:

解决方案
如果想使用DT、RF、XGB,离散特征需要人为进行处理。可以看这个博客,对类别特征进行编码。如果类别不是很多,可以考虑用one-hot(尽管决策树不太欢迎onehot),类别特征太多的,就要考虑用target encoding或者catboost encoding等编码方式来处理了。
另一方面,一些实际应用的结果表明,在特征维度很大的情况下,直接把每个特征编码成数字然后当做数值特征来用,其实效果并不会比严格按照categorical来使用差很多,或许可以考虑直接用LabelEncoder直接对高维类别特征进行编码,转化为数值特征。
或者考虑换LGBM、CatBoost -
相关阅读:
丹麦技术大学首创将量子计算应用于能源系统潮流建模
Java 华为真题-选修课
MFC 打印图片 dc.EndDoc(); 并没有释放怎么办? 原因:打印到pdf才会出现,打印到真实打印机就正常
程序员敲诈老板,或面临37年监禁
代码随想录day50:动态规划
Java小树的参天成长【Integer缓冲区】
day 0912
Java计算机毕业设计实验室设备管理系统演示录像2020源码+系统+数据库+lw文档
超图WMTS服务的几个关键参数
xen-trap
- 原文地址:https://blog.csdn.net/QIzikk/article/details/133815704