-
MySQL查漏补缺
1. UNION和UNION ALL:联合查询
UNION:联合的意思,将多个select查询的结果组合成一个结果集!是SQL中用于合并查询结果的操作符!
- 如果使用UNION,默认DISTINCT方式,会去除重复的行,即所有返回的行记录都是唯一的!
- 如果使用UNION ALL,不会去除重复的记录行,UNION ALL会保留所有行,它返回包含所有合并结果的结果集,包括重复行!
- 由于UNION需要去重操作,MySQL内部会使用自动生成的临时表以辅助SQL的执行,因此会稍微降性能,所以UNION ALL的效率要高于UNION!‘
- 补充:临时表的存在是为了辅助计算,比如group by语句、distinct查询去重也会产生一个临时表!
2. MySQL加密函数
- 在MySQL中,使用MD5()函数可以对字符串进行加密。
- MD5是一种哈希算法,通过降输入字符串转换为固定长度的哈希值表示,并且MD5()是一种单向加密算法,无法逆推还原原始字符串。
- -- 对字符串进行加密,返回使用MD5算法加密后的字符串的哈希值!
- select MD5('your_string');
3. 数据库设计 - 三范式
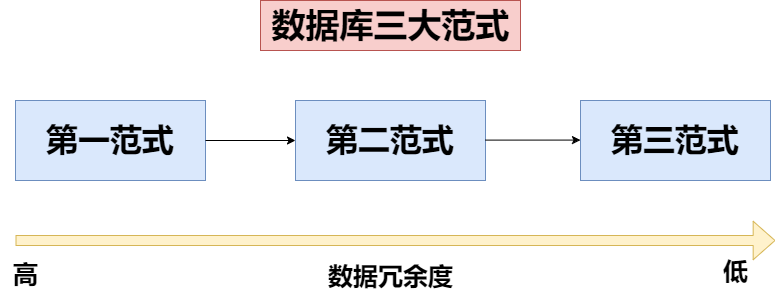
越高的范式表示数据的冗余度越低! - 注:设计只是一种思想一种理念,我们按照规范的设计方式来设计数据库对我们来说有好处,但绝对不是说一定要严格遵守,三范式能极大的减少数据冗余,但是却增加了我们编写SQL语句的难度,所以所有好的设计都是要权衡利弊的。
- 我们在开发中经常反三范式!
设计数据库表的时候所依据的共有三个规范:
- 1NF:第一范式:要求有主键,并且要求数据库表中的每一个字段都是单一属性,都不可以再拆分!即数据库中的每一列属性都是不可再分的原子值!
- 2NF:第二范式:满足第一范式的前提下,要求所有的非主键字段必须完全依赖于主键,不能产生部分或局部依赖,也就是不能是依赖于主键的一部分!第二范式是在第一范式的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。
- 3NF:第三范式:满足第二范式的前提下,要求所有的非主键字段和主键字段之间不能产生传递依赖!即表中的非主键都直接依赖于主键,而不是通过其他列间接依赖于主键。也就是要消除依赖传递!传递依赖就是某个非主键字段依赖于主键,而有其他字段依赖于该非主键字段,这就是传递依赖!
越高的范式表示数据的冗余度越低!
实际开发中一定要遵循三范式吗?为什么会有反范式设计?
- 当然不是!我们在开发中经常反三范式!
- 在项目开发中,如果完全遵循到第三范式,那么数据的查询就一定需要大量的表关联,自然就会造成性能上的问题!降低查询效率!
- 不管是阿里巴巴开发规约还是京东金融研发规约,都禁止超过三表关联。
- 为了满足规范,最简单的解决办法就是往表里增加一些冗余字段,从而解决太多表之间的关联查询问题,
4. 字符集和排序规则
- MySQL支持大量的字符集,但是我们通常使用的时UTF8,show collation 命令可以查看MySQL支持的所有的排序规则和字符集,如下所示:
- -- 查看MySQL支持的所有的排序规则和字符集
- show collation like '%utf8%'; -- collation:排序规则
- utf8mb3(UTF - 8):UTF - 8默认就是utf8mb3。
- utf8mb4:它时UTF-8的超集,甚至可以存储更多的emoji表情,MySQL 8.0已经默认字符集设置为utf8mb4。
- 在操作系统中,定位一个位置通常都是通过offset偏移量来定位!
- 如果按照一页16K计算的话,MySQL一个表空间最大支持64TB的数据!
5. InnoDB行格式有哪些?Compact行记录格式长什么样?
- Compact:压缩;紧凑 Redundant:冗余 Dynamic:动态的 Compressed:压缩
- Row Format(row_format) - 行记录格式,就是一条行记录的存储结构~!
- 一个表的行记录格式决定了表中数据行的物理存储模式,同时也决定了DQL和DML的操作性能!
- 越多的行被匹配进独立的磁盘页,SQL的性能就会越高,需要的IO操作就越少!
- 我们可以通过 show table like 'table_name' 来查看当前表使用的行格式,其中row_format就代表了档期那使用的行记录结构类型!
- -- 查看当前表使用的行格式
- show table status like 'table_name';
- -- 指定行格式的语法如下:
- -- 1. 创建数据库表时,显示指定行格式
- CREATE TABLE 表名 (列的信息) row_format = 行格式名称;
- -- 2. 创建数据库表时,修改行格式
- ALTER TABLE 表名 row_format = 行格式名称;
InnoDB行格式有哪些?
- InnoDB提供了4种行格式,分别是Redundant、Compact、Dynamic和Compressed行格式!
- Redundant是很古老的行格式了,MySQL 5.0版本之前用的行格式,现在已经基本没人用了。
- 由于Redundant不是一种紧凑的行格式,所以MySQL 5.0之后引入了Compact行记录存储格式!Compact是一种紧凑的行格式,设计的初衷就是为了让一个数据页可以存放更多的行记录,从MySQL 5.1版本之后,行记录格式默认为Compact。
- Dynamic和Compressed两个都是紧凑的行格式,它们的行格式和Compact差不多,因为它们都是基于Compact改进的,从MySQL 5.7版本之后,默认使用Dynamic行格式!
- 这里重点介绍Compact行格式,因为Dynamic和Compressed这两个行格式都跟Compact行格式非常像!
Compact行格式长什么样?
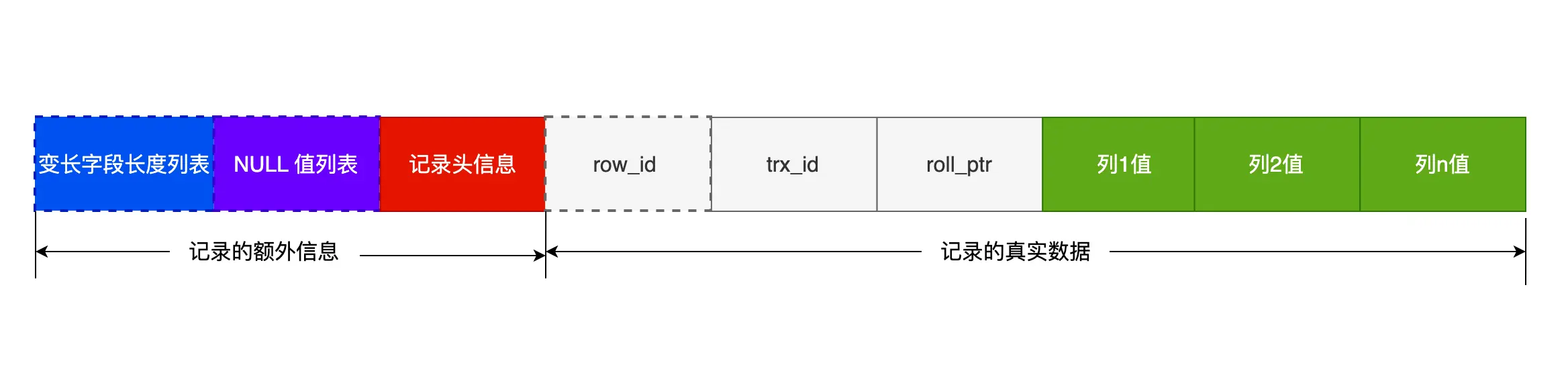
- 一条完整的信息记录分为:记录的额外信息和记录的真实数据两大部分,就如同一箱苹果分为包装箱和苹果一样!
记录的额外信息
- 记录的额外信息包含 3 个部分:变长字段长度列表、NULL 值列表、记录头信息。
- 第一个部分是非NULL的变长字段长度列表:NULL 是不会存放在行格式中记录的真实数据部分里的,我们的数据类型除了定长的char、int,还有不定长的如varchar、text等,「变长字段长度列表」保存的就是「变长字段的真实数据占用的字节数」,「变长字段长度列表」只出现在数据表有变长字段的时候!并且 「变长字段长度列表」的信息要按照逆序存放,这样可以提高CPU Cache(CPU高速缓存)的命中率!
- 第二个部分是NULL值列表或NULL标志位:它指示了当前行数据中哪些列为NULL值,NULL 值并不会存储在行格式中的真实数据部分,NULL值列表用一个BitMap表示,NULL值列表也不是必须的,当数据库表中的字段都定义成NOT NULL的时候,这时候表里面的行格式就不会有NULL值列表了!
- 记录头信息:记录头信息中包含的内容很多,我就不一一列举了,这里说几个比较重要的:
- delete_mask:标识这条数据是否被删除。从这里我们可以知道,我们在执行delete删除记录的时候,并不会真正的删除记录,只是将这个记录的delete_mask标记为1。
- next_record下一条记录的位置。
- redcord_type:标识当前记录的类型,0表示普通记录,1表示B+Tree非叶子节点记录,2表示最小记录,3表示最大记录。
问题抛出:MySQL怎么知道varchar(n)实际占用数据的大小?
- MySQL中的Compact行格式中会用 变长字段长度列表 存储变长字段实际占用的数据大小!
记录的真实数据
- 记录的真实数据除了我们定义的字段,还有三个隐藏字段,分别是:DB_ROW_ID、DB_TRX_ID和DB_ROLL_PTR。
- DB_ROW_ID:隐藏主键,占用6个字节大小。
- DB_TRX_ID:事务ID,创建这条记录或最后一次修改该记录的事务ID的值,DB_TRX_ID是必须的,占用6个字节大小!
- DB_ROLL_PTR:Roll-Pointer - 回滚指针,被改动前的 undo log 日志指针,指向上一个历史版本状态的数据,通过它可以找到修改前的记录!
6. 行溢出后,MySQL是怎么处理的?
- 行溢出:一个Page数据页的默认大小上限是16KB,大于这个值就是行溢出!
- 一些大对象比如TEXT、BLOB可能存储更多的数据,此时一个Page页可能就存放不了一条记录,这时候就会发生行溢出,多的数据就会被存到另外的溢出页当中。
- 如果一个数据页存不了一条记录,InnoDB存储引擎会自动的将溢出的数据存放到溢出页当中。我们知道在一般情况下,InnoDB的数据都是存放在数据页当中,但是当发生行溢出时,溢出的数据会被存放到溢出页当中!
7. 什么是外键?
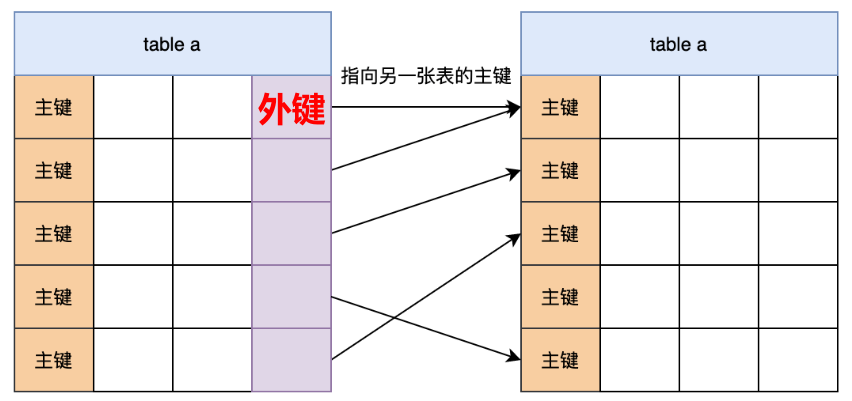
- 外键是说某张表的主键,在另一张表中被使用!
- 外键约束主要用来维护两个表之间的数据一致性!
8. 知识补充 - Duplicate Exception
- 该字段添加了唯一约束,当然同时也会为该字段自动建立唯一索引,该字段添加唯一约束后所插入的值不能重复,如果重复则会报错:Duplicate Exception - 重复异常 - 重复数据的报错!
-
相关阅读:
springmvc http请求,支持get,post,附件传输和参数传输
WZOI-222最小公倍数
【复盘】主从延迟以及 Waiting for tablemetadata lock 线上问题
mysql数据库使用useSSL=true,并配置ca证书和密钥连接
OP-TEE中的线程管理(三)
MySQL数据库基础
(C++)验证回文字符串
D - United We Stand
c#数据类型
基于python-socket构建任务服务器(基于socket发送指令创建、停止任务)
- 原文地址:https://blog.csdn.net/weixin_53622554/article/details/133823273