-
Flink测试利器之DataGen初探 | 京东云技术团队
什么是 Flinksql
Flink SQL 是基于 Apache Calcite 的 SQL 解析器和优化器构建的,支持ANSI SQL 标准,允许使用标准的 SQL 语句来处理流式和批处理数据。通过 Flink SQL,可以以声明式的方式描述数据处理逻辑,而无需编写显式的代码。使用 Flink SQL,可以执行各种数据操作,如过滤、聚合、连接和转换等。它还提供了窗口操作、时间处理和复杂事件处理等功能,以满足流式数据处理的需求。
Flink SQL 提供了许多扩展功能和语法,以适应 Flink 的流式和批处理引擎的特性。他是Flink最高级别的抽象,可以与 DataStream API 和 DataSet API 无缝集成,利用 Flink 的分布式计算能力和容错机制。
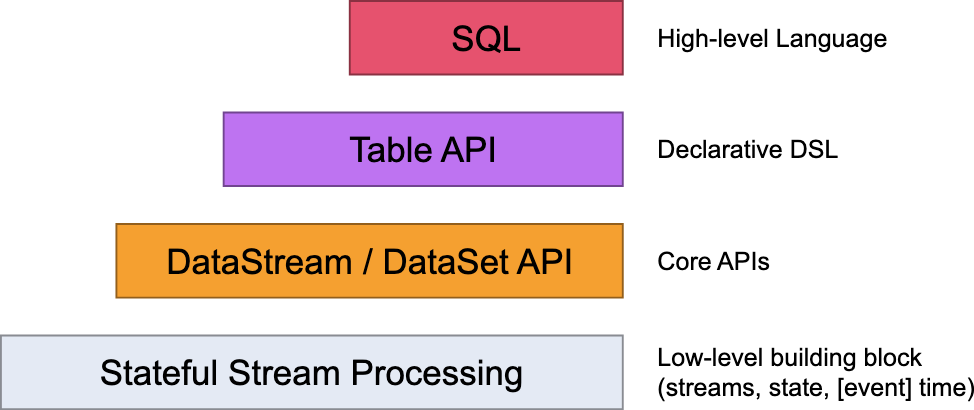
使用 Flink SQL处理数据的基本步骤:
-
定义输入表:使用 CREATE TABLE 语句定义输入表,指定表的模式(字段和类型)和数据源(如 Kafka、文件等)。
-
执行 SQL 查询:使用 SELECT、INSERT INTO 等 SQL 语句来执行数据查询和操作。您可以在 SQL 查询中使用各种内置函数、聚合操作、窗口操作和时间属性等。
-
定义输出表:使用 CREATE TABLE 语句定义输出表,指定表的模式和目标数据存储(如 Kafka、文件等)。
-
提交作业:将 Flink SQL 查询作为 Flink 作业提交到 Flink 集群中执行。Flink会根据查询的逻辑和配置自动构建执行计划,并将数据处理任务分发到集群中的任务管理器进行执行。
总而言之,我们可以通过Flink SQL 查询和操作来处理流式和批处理数据。它提供了一种简化和加速数据处理开发的方式,尤其适用于熟悉 SQL 的开发人员和数据工程师。
什么是 connector
Flink Connector 是指用于连接外部系统和数据源的组件。它允许 Flink 通过特定的连接器与不同的数据源进行交互,例如数据库、消息队列、文件系统等。它负责处理与外部系统的通信、数据格式转换、数据读取和写入等任务。无论是作为输入数据表还是输出数据表,通过使用适当的连接器,可以在 Flink SQL 中访问和操作外部系统中的数据。目前实时平台提供了很多常用的连接器:
例如:
-
JDBC :用于与关系型数据库(如 MySQL、PostgreSQL)建立连接,并支持在 Flink SQL 中读取和写入数据库表的数据。
-
JDQ :用于与 JDQ 集成,可以读取和写入 JDQ 主题中的数据。
-
Elasticsearch :用于与 Elasticsearch 集成,可以将数据写入 Elasticsearch 索引或从索引中读取数据。
-
File Connector:用于读取和写入各种文件格式(如 CSV、JSON、Parquet)的数据。
-
…
还有如HBase、JMQ4、Doris、Clickhouse,Jimdb,Hive等,用于与不同的数据源进行集成。通过使用 Flink SQL Connector,我们可以轻松地与外部系统进行数据交互,将数据导入到 Flink 进行处理,或将处理结果导出到外部系统。

DataGen Connector
DataGen 是 Flink SQL 提供的一个内置连接器,用于生成模拟的测试数据,以便在开发和测试过程中使用。
使用 DataGen,可以生成具有不同数据类型和分布的数据,例如整数、字符串、日期等。这样可以模拟真实的数据场景,并帮助验证和调试 Flink SQL 查询和操作。
demo
以下是一个使用 DataGen 函数的简单示例:
-- 创建输入表 CREATE TABLE input_table ( order_number BIGINT, price DECIMAL(32,2), buyer ROW, order_time TIMESTAMP(3) ) WITH ( 'connector' = 'datagen', ); - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
在上面的示例中,我们使用 DataGen 连接器创建了一个名为 `input_table` 的输入表。该表包含了 `order_number`、`price` 和 `buyer` ,`order_time`四个字段。默认是random随机生成对应类型的数据,生产速率是10000条/秒,只要任务不停,就会源源不断的生产数据。当然也可以指定一些参数来定义生成数据的规则,例如每秒生成的行数、字段的数据类型和分布。
生成的数据样例:
{"order_number":-6353089831284155505,"price":253422671148527900374700392448,"buyer":{"first_name":"6e4df4455bed12c8ad74f03471e5d8e3141d7977bcc5bef88a57102dac71ac9a9dbef00f406ce9bddaf3741f37330e5fb9d2","last_name":"d7d8a39e063fbd2beac91c791dc1024e2b1f0857b85990fbb5c4eac32445951aad0a2bcffd3a29b2a08b057a0b31aa689ed7"},"order_time":"2023-09-21 06:22:29.618"} {"order_number":1102733628546646982,"price":628524591222898424803263250432,"buyer":{"first_name":"4738f237436b70c80e504b95f0d9ec3d7c01c8745edf21495f17bb4d7044b4950943014f26b5d7fdaed10db37a632849b96c","last_name":"7f9dbdbed581b687989665b97c09dec1a617c830c048446bf31c746898e1bccfe21a5969ee174a1d69845be7163b5e375a09"},"order_time":"2023-09-21 06:23:01.69"}- 1
- 2
- 3
支持的类型
字段类型 数据生成方式 BOOLEAN random CHAR random / sequence VARCHAR random / sequence STRING random / sequence DECIMAL random / sequence TINYINT random / sequence SMALLINT random / sequence INT random / sequence BIGINT random / sequence FLOAT random / sequence DOUBLE random / sequence DATE random TIME random TIMESTAMP random TIMESTAMP_LTZ random INTERVAL YEAR TO MONTH random INTERVAL DAY TO MONTH random ROW random ARRAY random MAP random MULTISET random 连接器属性
属性 是否必填 默认值 类型 描述 connector required (none) String ‘datagen’. rows-per-second optional 10000 Long 数据生产速率 number-of-rows optional (none) Long 指定生产的数据条数,默认是不限制。 fields.#.kind optional random String 指定字段的生产数据的方式 random还是sequence fields.#.min optional (Minimum value of type) (Type of field) random生成器 指定字段 # 最小值, 支持数字类型 fields.#.max optional (Maximum value of type) (Type of field) random生成器的指定字段 # 最大值, 支持数字类型 fields.#.length optional 100 Integer char/varchar/string/array/map/multiset 类型的长度. fields.#.start optional (none) (Type of field) sequence生成器的开始值 fields.#.end optional (none) (Type of field) sequence生成器的结束值 DataGen使用
了解了dategen的基本使用方法,那么下面来结合其他类型的连接器实践一下吧。
场景1 生成一亿条数据到hive表
CREATE TABLE dataGenSourceTable ( order_number BIGINT, price DECIMAL(10, 2), buyer STRING, order_time TIMESTAMP(3) ) WITH ( 'connector'='datagen', 'number-of-rows'='100000000', 'rows-per-second' = '100000' ) ; CREATECATALOG myhive WITH ( 'type'='hive', 'default-database'='default' ); USECATALOG myhive; USE dev; SETtable.sql-dialect=hive; CREATETABLEifnotexists shipu3_test_0932 ( order_number BIGINT, price DECIMAL(10, 2), buyer STRING, order_time TIMESTAMP(3) ) PARTITIONED BY (dt STRING) STORED AS parquet TBLPROPERTIES ( 'partition.time-extractor.timestamp-pattern'='$dt', 'sink.partition-commit.trigger'='partition-time', 'sink.partition-commit.delay'='1 h', 'sink.partition-commit.policy.kind'='metastore,success-file' ); SETtable.sql-dialect=default; insert into myhive.dev.shipu3_test_0932 select order_number,price,buyer,order_time, cast( CURRENT_DATE as varchar) from default_catalog.default_database.dataGenSourceTable;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
当每秒生产10万条数据的时候,17分钟左右就可以完成,当然我们可以通过增加Flink任务的计算节点、并行度、提高生产速率’rows-per-second’的值等来更快速的完成大数据量的生产。
场景2 持续每秒生产10万条数到消息队列
CREATE TABLE dataGenSourceTable ( order_number BIGINT, price INT, buyer ROW< first_name STRING, last_name STRING >, order_time TIMESTAMP(3), col_array ARRAY < STRING >, col_map map < STRING, STRING > ) WITH ( 'connector'='datagen', --连接器类型 'rows-per-second'='100000', --生产速率 'fields.order_number.kind'='random', --字段order_number的生产方式 'fields.order_number.min'='1', --字段order_number最小值 'fields.order_number.max'='1000', --字段order_number最大值 'fields.price.kind'='sequence', --字段price的生产方式 'fields.price.start'='1', --字段price开始值 'fields.price.end'='1000', --字段price最大值 'fields.col_array.element.length'='5', --每个元素的长度 'fields.col_map.key.length'='5', --map key的长度 'fields.col_map.value.length'='5' --map value的长度 ) ; CREATE TABLE jdqsink1 ( order_number BIGINT, price DECIMAL(32, 2), buyer ROW< first_name STRING, last_name STRING >, order_time TIMESTAMP(3), col_ARRAY ARRAY < STRING >, col_map map < STRING, STRING > ) WITH ( 'connector'='jdq', 'topic'='jrdw-fk-area_info__1', 'jdq.client.id'='xxxxx', 'jdq.password'='xxxxxxx', 'jdq.domain'='db.test.group.com', 'format'='json' ) ; INSERTINTO jdqsink1 SELECT*FROM dataGenSourceTable;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
思考
通过以上案例可以看到,通过Datagen结合其他连接器可以模拟各种场景的数据
- 性能测试:我们可以利用Flink的高处理性能,来调试任务的外部依赖的阈值(超时,限流等)到一个合适的水位,避免自己的任务有过多的外部依赖出现木桶效应;
- 边界条件测试:我们通过使用 Flink DataGen 生成特殊的测试数据,如最小值、最大值、空值、重复值等来验证 Flink 任务在边界条件下的正确性和鲁棒性;
- 数据完整性测试:我们通过Flink DataGen 可以生成包含错误或异常数据的数据集,如无效的数据格式、缺失的字段、重复的数据等。从而可以测试 Flink 任务对异常情况的处理能力,验证 Flink任务在处理数据时是否能够正确地保持数据的完整性。
总之,Flink DataGen 是一个强大的工具,可以帮助测试人员构造各种类型的测试数据。通过合理的使用 ,测试人员可以更有效地进行测试,并发现潜在的问题和缺陷。
作者:京东零售 石朴
来源:京东云开发者社区 转载请注明来源
-
-
相关阅读:
源码分析:设备创建链接和断开链接
【经历】在职8个月->丰富且珍贵
高效且无限扩容,浅析什么是对象存储?
h5(react ts 适配)
Python算法练习 10.15
webpack--加载器(loader)
win10家庭版安装docker desktop问题
iOS 创建PDF文件
Gin源码之gin.Engine结构体及其方法
SpringBoot2入门必读(4):Spring boot集成Mybatis(一)
- 原文地址:https://blog.csdn.net/JDDTechTalk/article/details/133805953
