-
富文本文案存储翻译方案
一般富文本的功能会有些样式,存储到数据库表里面之后会带上一大堆的标签和样式,底层如果要对这些进行翻译的话会变得非常困难,因为我们要翻译的只是里面的中文内容,这就面临第一个问题,把中文取出来,如果把这个当成一道题,大致会有集中方案:
1、遍历整个内容,判断连续的中文文段,收集起来,
2、利用正则表达式, 获取出特定标签内的内容。以上两种方式都会面临一个问题,内容取不全,翻译就会不完整,因为不确定正文是否包含正则内的内容。
还有就是代码不好写,要处理各种边界逻辑。
我有一种办法,代码仅需十几行,首先富文本内容都有一个特点,就是前端能转换成html解析,所以,我们把内容转换成我们能看到的结构,在代码中就是转换成html结构的对象,那什么工具能实现这种效果呢?
JSOUP
废话不多说:

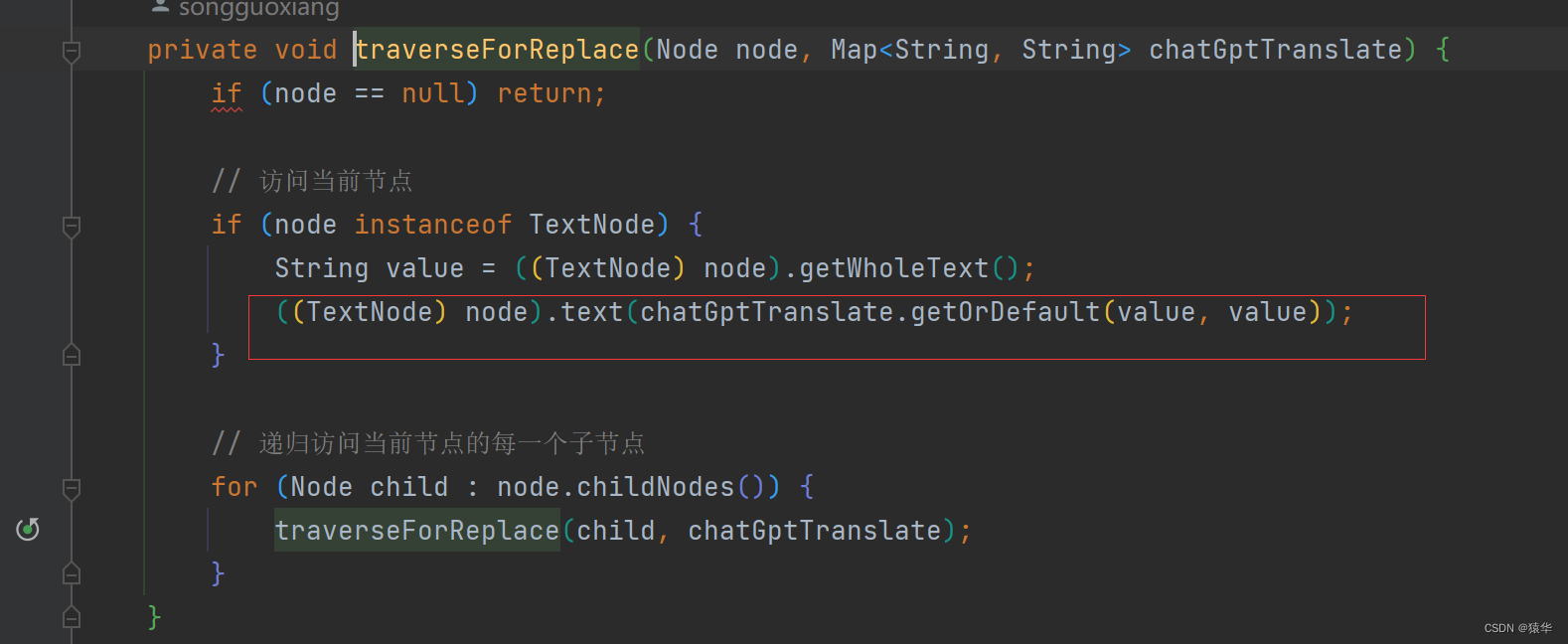
转换成Document对象之后里面的标签都会被解析成该对象的节点,有个类型就是存储的正文内容:TextNode
拿到这个节点之后就能拿到文案内容了。
一个递归即可解决

这样之后termList就是整个富文本中的非标签内容,将其翻译之后在替换回来就完美解决了
-
相关阅读:
独立站3大火爆类目推荐
强化学习科研知识必备(数据库、期刊、会议、牛人)
java集合常用方法汇总
@ConditionalOnProperty 用法
一篇五分生信临床模型预测文章代码复现——Figure1 差异表达基因及预后基因筛选——下载数据(一)
vue 中 watch 对对象的深度监听
Vue.js(2): 组件与路由基础指南
Golang中init()函数初始化顺序
Python (十二) 模块、包
抖音矩阵系统,抖音矩阵系统,抖音矩阵系统,抖音矩阵系统,抖音矩阵系统,抖音矩阵系统,抖音矩阵系统,抖音矩阵系统,抖音矩阵系统,抖音矩阵系统。
- 原文地址:https://blog.csdn.net/m0_52255061/article/details/133811035