-
快排&超详细,Leetcode排序数组题目带你升华掌握

大家好,这里是Dark FalmeMater。
这篇文章我将超级仔细地讲解快速排序,快排之所以叫快排,到底有多快,为什么这么快,还有快速排序的优化和改进,通过这篇文章你一定会对快排有进一步的掌握。快排的历史及介绍
快速排序由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归 进行,以此达到整个数据变成有序序列。
其中Hoare大佬写的版本由于没有那么容易理解且容易出现错误,在后人的智慧下,进行了小小的改变,分化出了挖坑法和双指针法。我们逐个进行讲解。
Hoare版

递归函数分析思路如下
在数组中选定一个关键的点,最右边或者最右边都可以。我们选择最左边进行讲解,找到关键位置后设置left和rght然后分别从数组左边和最右边开始遍历,右边先行,找到小于key位置的值就停下了,左边的找大于key位置的值,找到后就互换,直到左下标和右下标相遇,相遇的时候说明左边已经没有大于key位置的值了,右边没有小于key位置的值了,交换相遇位置的值和key位置的值,就可以将该组数分割成以key位置的值分割的两组数。
有了思路我们可以写出以下的代码:
//hoare版本 int PartSort1(int* a, int left, int right) { int key = a[left];//设置关键点 while (left < right) { while (a[right] > a[keyi])//从最右边开始找到大于关键点的坐标 { --right; } //找大 while (a[left] < a[keyi])//从左边开始找到小于key的坐标 { ++left; } Swap(&a[left], &a[right]);//交换 } Swap(key, &a[left]);//当left相遇,就交换关键点和相遇点的值 return left;返回相遇点的坐标 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
Hoare版解答疑惑及易错点指出:
- key的选择
之所以选择最左边的位置设置key,是因为利用这个值在写代码和进行判断时更方便一些,利用right位置的值当做key当然也可以,如果用递归函数传参数组的第二个元素做key,在递归到每个小区间只有一个数时就会出现错误,因为没有key。
- 相遇节点为什么可以和key位置的互换呢?为什么相遇点的数值一定会比key位置的值小呢?
大家可以思考一下…
这就要看左右指针谁先行了,如动图所示

如果是right先行,会发生什么呢?其实除了最后left和right相遇,其他的都是一样,如果是right先行的话。

在循环判断中右边先行是一定要注意的。
还有吗?
还有呢。
判断条件怎么写呢?判断条件是大于交换还是大于等于(相对left而言)交换呢?如果是left位置的值大于key的话,就交换有可能会发生森么情况呢?

看这个图,在交换了组边的6和右边的2之后,right开始–,因为判断条件是a[right]>key,所以当right找到5时,5=key,right就跳出了循环。同理,因为不满足left下标的值小于key,left跳出循环,交换以left为下标和以right为下标的值,交换的还是5和5,再次循环,判断left
看动图

判断条件也要注意,这种情况很难想到,所以有时运行错误不知道问题出在哪里
更改上边问题,将判断条件改为a[right] >= key和a[left] <= a[keyi]
思考了这么多,终于找到相遇的点后交换key和a[left](a[left]都可以),就可以将这个数组分为两个大小不同的的区间啦!
真的吗?
前边初始化key=a[left],交换key和遍历后的a[left],然而a[0]并没有和找到的值进行交换,而是key这个数和找到的相遇点交换,这个时候a[left]就没有改变为相遇点找到的小于key的值,如果一直递归下去,会变成什么样呢?(上边动图部分,key改成a[left])再来看排序该组数据

如果是创建的key和找到的点进行交换,就会出现数据污染,好多数据都被更改了,这样的排序一定是错误的,所以初始化条件可以这样。int keyi=left;
int key=a[keyi]在判断时利用key,在交换时交换a[keyi]和a[left]即可。
终于结束啦,然而并没有。
要注意的是在right和left找的过程中left也不能小于right,比如该数组是有序的,在排序的过程中,right先行,但是一直没有找到小于a[keyi]的值,直到到达left的位置再次减一,就会越界访问。
完整代码如下//hoare版本 int PartSort1(int* a, int left, int right) { //int midi=GetMidi(a,left,right) //Swap(&a[left[,&a[midi]); int keyi = left; while (left < right) { while (left < right && a[right] >= a[keyi]) { --right; } //找大 while (left < right && a[left] <= a[keyi]) { ++left; } Swap(&a[left], &a[right]); } Swap(&a[keyi], &a[left]); return left; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
是不是细节满满,一不小心就会出来好多bug。
挖坑法
同样先看图
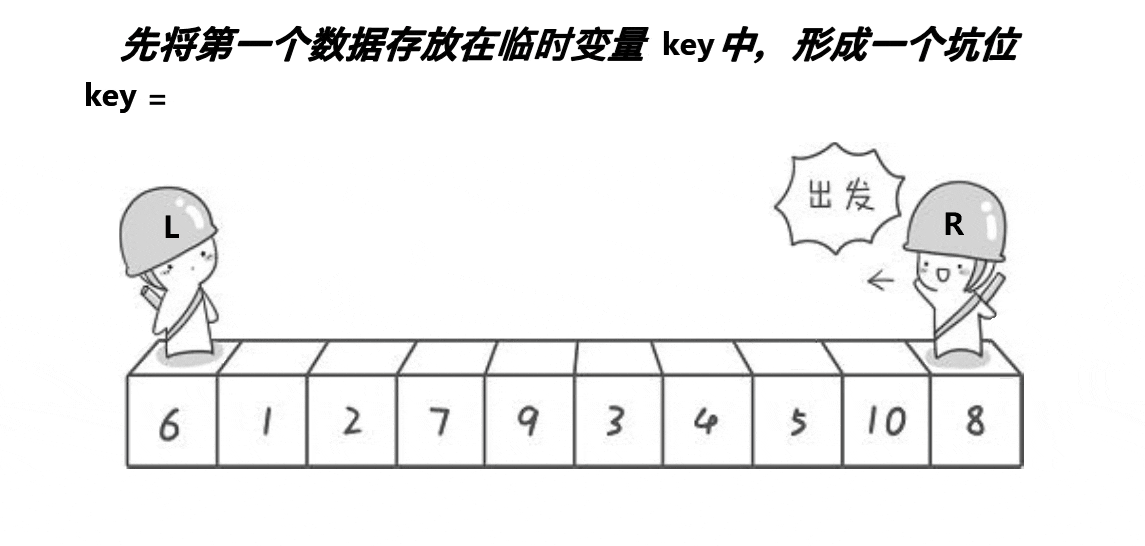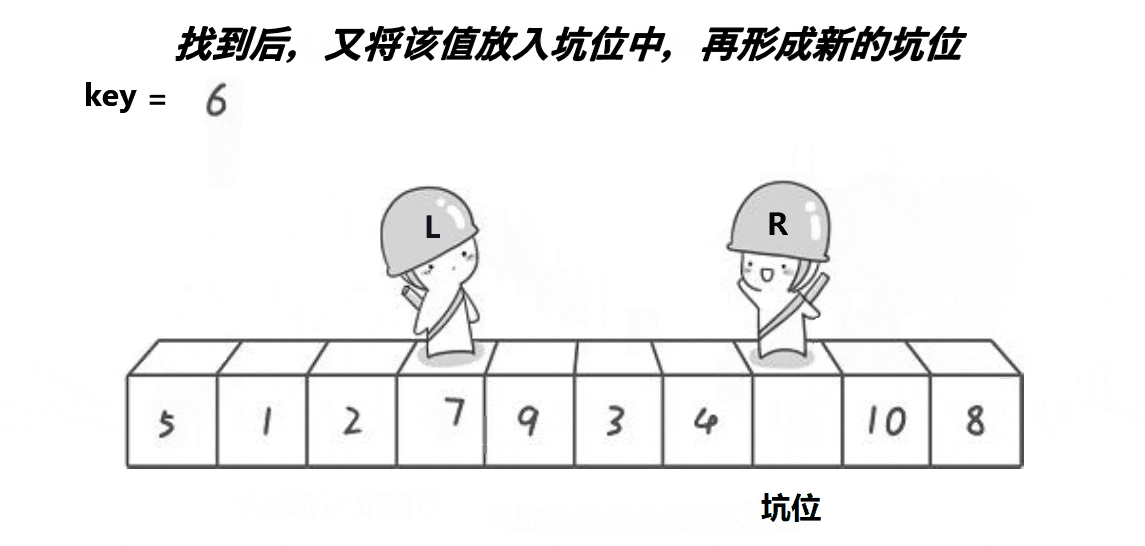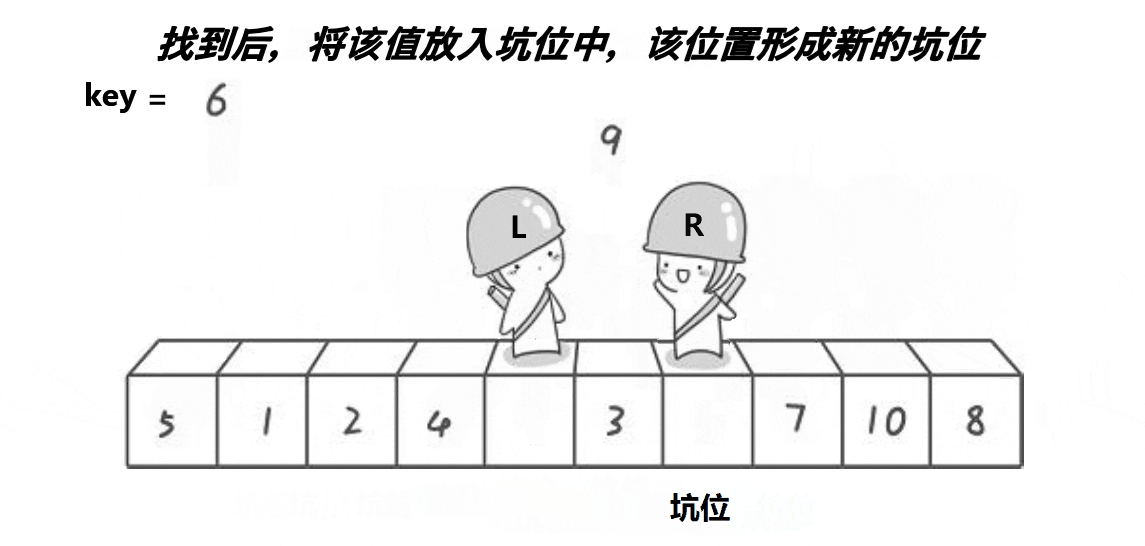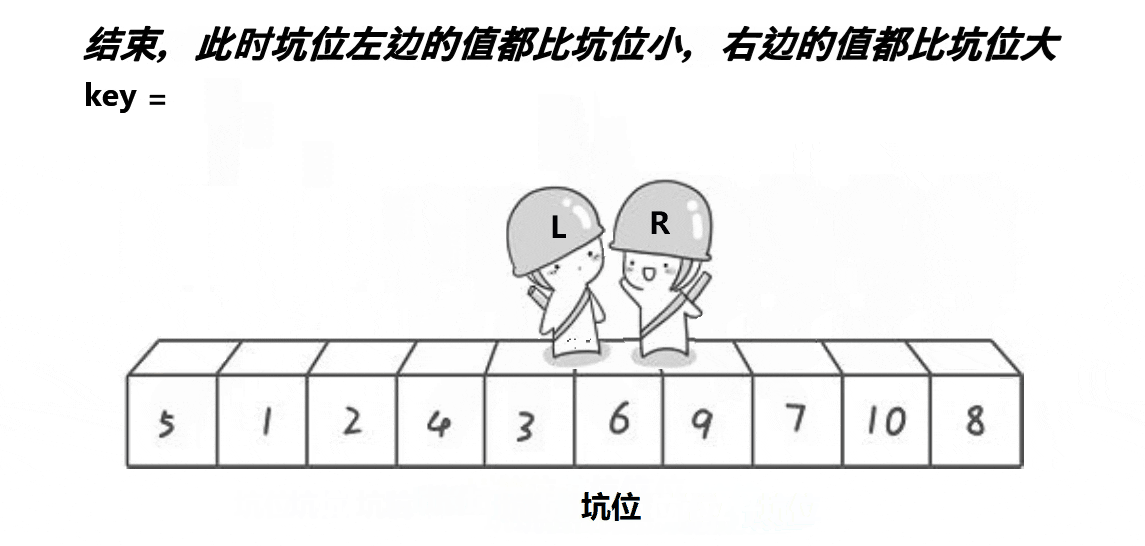
挖坑法相较于Hoare大佬的方法,步骤更加清晰明了一点,一步一步实现上边的动图表现得十分清晰,设置一个坑位,保存left位置的值,设置hole变量等于left,然后从右边找小于a[keyi]即上图key的值,填入坑中,这时将找到的值的位置right设置为坑,然后从左往右找大于a[keyi]的值填入hole,将left所在位置设置为hole,不断循环,直到left等于right,将之前保存的key,即a[keyi]填进坑里,就完成了前边相同的操作。
代码如下,很容易理解
//挖坑法 int PartSort2(int* a, int left, int right) { int key = a[left]; //保存key值以后。左边形成一个坑 int hole = left; while (left < right) { while (left < right && a[right] >= key) { --right; } a[hole] = a[right]; hole = right; //左边再走,找大,填到右边的坑,左边重新形成新的坑位 while (left < right && a[left] <= key) { ++left; } a[hole] = a[left]; hole = left; } a[hole] = key; return hole; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
最后返回right,left,hole都可以,反正最后他们在同一个位置上。
双指针法

看几遍动图,不管他们用什么方法进行实现,最终实现的效果都是相同的。双指针法只要懂得了原理,还是很容易实现的。
双指针法和前边两种方法略有不同,来体验一下。先看代码后进行讲解//前后指针法 int PartSort3(int* a, int left, int right) { int midi = GetMidi(a, left, right); Swap(&a[left], &a[midi]); int prev = left; int cur = prev + 1; int keyi = left; while (cur <= right) { if (a[cur] < a[keyi]) { ++prev; if (prev != cur) { Swap(&a[prev], &a[cur]); } } ++cur; } Swap(&a[prev], &a[keyi]); return prev; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
还是一样选择left位置的值作为key,设置两个指针,一个指向数组最前边的位置,一个在他的后边,前后指针法因此得名。
具体思路:设置前后指针,后边的指针只要不越界访问,cur就一直往后走,如果prev的下一个位置不是cur,且cur找到小于key的值时,就交换prev位置和cur位置的值。直到最后cur大于right结束循环。此时prev位置的值一定小于或等于key,因为cur在后边查找的过程中最不济的情况也就是一个也没找到,prev和他自己换,照样也不变,在找到第一个之前cur和prev一直一起移动并一直在cur的后一位,当cur找到大于key位置的坐标后,prev不动,cur继续移动,所以当cur找到小于key的位置时,prev的下一个位置一定是大于key的,可以放心交换。
直到最后cur走到数组尽头,就如前边所说,prev的下一位一定大于key,而prev位置的值一定小于等于key,交换a[prev]和a[keyi]的值,就可以将数组分成以prev位置为中心的两组,左边的值都小于等于key,右边的值都大于key。循环有一种更简单的方法表示,效果相同
while (cur <= right) { if (a[cur] < a[keyi] && ++prev != cur) { Swap(&a[prev], &a[cur]); } ++cur; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
&&操作符,当前一条件为假,后一条件就不走,如果前一条件为真后,才会走后一条件,然后prev才会++,与上边实现的效果相同。
递归函数
void QuickSort1(int* a, int begin, int end) { if (begin >= end) { return; } int keyi = PartSort1(a, begin, end); QuickSort1(a, begin, keyi - 1); QuickSort1(a, keyi + 1, end); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
begin和end是传进来的数组段的第一个位置和最后一个位置的下标。要注意接下来的递归数组的区间还有结束判断条件。
举一个例子说明递归流程。

递归结束后,数组就变为有序的了。至于先往右递归还是先往左都可以,没有区别。
上边递归时用的Hoare大佬的版本,用挖坑法和双指针法也都可以。时间复杂度与空间复杂度
快排的时间复杂度为O(nlogN),空间复杂度为O(N),如果情况比较好的话为O(log2n),空间是可以复用的,一边用完另一边还可以用。
时间复杂度最坏的情况是若该数组为有序数组。最好情况就是一直取到中间位置。
最坏情况:

若数组数量为n,一次只排好了一个数据,right第一次跑n次,第二次跑n-1次,则时间复杂度明显为O(n^2)。
假使每次都能找到中间值,此时时间复杂度最低。2^h=n,所以n=log2 ^n。

最好情况时间复杂度为O(nlogn)。
至于空间复杂度从上边的图就可以看出,因为递归开辟的空间是在栈上的,每次开辟的空间都可知小于n,故每次递归开辟空间为O(1),所以快排的时间复杂度为递归深度乘于O(1),最坏情况为O(N),最好的情况为O(logN)。优化
借助题目:排序数组

给一个数组,要求给他排序,要求很简单,却只有50%的通过率,力扣标记简单不一定简单,标记中等那一定是有点难。
这题很显然,普通的排序比如冒泡排序,插入排序,选择排序是过不了的,我们刚刚学习了快排,何不尝试一波。void Swap(int* x, int* y) { int tmp = *x; *x = *y; *y = tmp; } void QuickSort1(int* a, int begin, int end) { if (begin >= end) { return; } int keyi = PartSort1(a, begin, end); QuickSort1(a, begin, keyi - 1); QuickSort1(a, keyi + 1, end); } //hoare版本 int PartSort1(int* a, int left, int right) { int keyi = left; while (left < right) { while (left < right && a[right] >= a[keyi]) { --right; } //找大 while (left < right && a[left] <= a[keyi]) { ++left; } Swap(&a[left], &a[right]); } Swap(&a[keyi], &a[left]); return left; } int* sortArray(int* nums, int numsSize, int* returnSize){ QuickSort1(nums, 0, numsSize-1); *returnSize=numsSize; return nums; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
快排解题的代码如下
然而却发现

用hoare大佬的方法走一遍,发现时间复杂度在这组用例上为O(N^2),right一直向右移,不会分成左右两组,一直递归n次,right向前的次数从n到1,这样的话花费的时间太多了,针对这种情况进行优化,就要介绍三数取中。三数取中
如何防止上面最坏的情况发生?
只需要防止最左边的数为该组数里最小的数即可。可以找出left位置的值和right位置的值及(left+right)/2数组中间下标的值,找出他们三个中间大小的一个,与a[left]进行交换,这样就可以防止left是数组中最小的元素这种情况的发生。
将三数取中抽离成函数
//三数取中 int GetMidi(int* a, int left, int right) { int mid = (left + right) / 2; //left mid right if (a[left] < a[mid]) { if (a[mid] < a[right]) { return mid; } else if (a[left] > a[right]) { return left; } else { return right; } } else { if (a[mid] > a[right]) { return mid; } else if (a[left] > a[right]) { return left; } else { return right; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
在每次partsort前搞来中间值的坐标,与left进行交换
int midi=GetMidi(a,left,right)
Swap(&a[left[,&a[midi]);加上三数取中再次运行
然而。。。。

再次出乎意料,如果是全部数字都一样或者有大量重复数据,right还是像刚才有序数组的情况一样,right一直向左,时间复杂度为O(N^2),此时三数取中也没用了,无论怎么取,取到的都是2。针对这种情况怎么办?三路分化
将hoare大佬的方法和双指针法结合起来,将数组分为三个部分,左边小于key,中间的区段是等于key的,右边的部分是大于key的。
设置三个指针,两个指针用于位置的交换是数组划分为三个区间,一个指针用于遍历。
看思路

最后在left和right之间的部分就是等于5的部分,left之前皆小于key,right之后皆大于key。
总结下来只有以下三种情况- cur的值小于key,交换cur的值和left的值,cur++,left++。
- cur的值等于key,直接++cur
- cur的值大于key,交换cur和right的值,cur不能动。
代码实现
void QuickSort1(int* a, int left, int right) { if (left >= right) { return; } int begin = left;//记录左右边界 int end = right; int midi = GetMidi(a, left, right); Swap(&a[left], &a[midi]); int key = a[left]; int cur = left + 1; while (cur <= right) { if (a[cur] < key)//重点理解 { Swap(&a[cur], &a[left]); ++left; ++cur; } else if (a[cur] > key) { Swap(&a[cur], &a[right]); } else { ++cur; } } QuickSort1(a, begin, left-1); QuickSort1(a, right+1, end); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
这次我们信心满满,如果数组的元素全部为2的话,遍历一遍,right和left直接相遇,甚至只需要O(N)的时间就可以完成。
更改代码后运行。

还是超出时间限制,这又是为什么呢?这道题对快速排序做了针对性的处理,普通的快排很难过这道题,他会检测我们的三数取中,然后搞出对应的一串数字,让每次取出的数都是数组中倒数第二大,这样的话时间复杂度还是很大。
解决方法:选取数组中任意位置的数和left位置和right作比较选出keyi,而不是一直取中间坐标与他们相比较,用rand函数进行操作,使我们选数位置没有规律可循,这样编译器就不能根据我们所写的代码搞出针对性用例。
代码如下:
int GetMidi(int* a, int left, int right) { //int mid = (left + right) / 2; int mid =left+(rand()%(right-left)); //left mid right if (a[left] < a[mid]) { if (a[mid] < a[right]) { return mid; } else if (a[left] > a[right]) { return left; } else { return right; } } else { if (a[mid] > a[right]) { return mid; } else if (a[left] > a[right]) { return left; } else { return right; } } } void Swap(int* x, int* y) { int tmp = *x; *x = *y; *y = tmp; } void QuickSort1(int* a, int left, int right) { if (left >= right) { return; } int begin = left;//记录左右边界 int end = right; int midi = GetMidi(a, left, right); Swap(&a[left], &a[midi]); int key = a[left]; int cur = left + 1; while (cur <= right) { if (a[cur] < key) { Swap(&a[cur], &a[left]); ++left; ++cur; } else if (a[cur] > key) { Swap(&a[cur], &a[right]); --right; } else { ++cur; } } QuickSort1(a, begin, left-1); QuickSort1(a, right+1, end); } int* sortArray(int* nums, int numsSize, int* returnSize){ srand(time(NULL)); QuickSort1(nums, 0, numsSize-1); *returnSize=numsSize; return nums; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
运行后如图

可以发现所用时间还是很长,这道题如果用堆排序和shell排序都是很好过的,放在这里是为了提升我们对快排的理解和掌握。小区间优化
在上边显示递归流程的图中,我们可以看到递归的过程,类比树的结构,树的每一个节点都是一次递归,树的最后一排的节点个数占全部节点的50%,倒数第二行占总个数的25%,如果分成的数组的量的变小到一定的个数的时候可以不再使用递归,而是选择其他的方法进行排序,可以减少大量的递归次数。
这种方法叫做小区间优化,使用什么排序比较好呢?冒泡排序和选择排序的时间复杂度为O(N²),选择排序的时间复杂度最高为O(N²),可以使用选择排序进行小区间优化,从而减少大量的递归次数
插入排序及小区间优化后的代码如下//插入排序 void InsertSort(int* a, int n) { //[0,end]有序,把end+1的位置插入到前序序列 //控制[0,end+1]有序 for (int i = 0; i < n - 1; i++) { int end = i; int tmp = a[end + 1]; while (end >= 0) { if (tmp < a[end]) { a[end + 1] = a[end]; } else { break; }-+ --end; } a[end + 1] = tmp; } } //加上小区间优化 void QuickSort2(int* a, int begin, int end) { if (begin >= end) { return; } if ((end - begin + 1) > 10)//如果一个数组的元素小于10,就进行插入排序 { int keyi = PartSort2(a, begin, end); QuickSort2(a, begin, keyi - 1); QuickSort2(a, keyi + 1, end); } else { InsertSort(a + begin, end - begin + 1); } } //加上小区间优化 void QuickSort2(int* a, int begin, int end) { if (begin >= end) { return; } if ((end - begin + 1) > 10) { int keyi = PartSort2(a, begin, end); QuickSort2(a, begin, keyi - 1); QuickSort2(a, keyi + 1, end); } else { InsertSort(a + begin, end - begin + 1); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
快排非递归版
复习一下:它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归 进行,以此达到整个数据变成有序序列。
将一整个数组不断细分,在不断划分的过程中进行有序化,最终完成排序的功能。在前边partsort函数中,我们只要通过某种方法得到分成一组一组的小数组段的left和right即可。
上边的说明递归的流程图是直接全部展开的,实际上是一直向左划分,直到分出的数组left和right相等,然后回到上步。
如图所示

结合代码就很容易明白。
在非递归版本我们想和递归的步骤相同,如何得到上述递归过程中的left和right?这是问题之所在,而且在递归过程中向partsort1传入不同的left和right。
可以借助栈先进先出的功能来实现,push起始的left和right,进行第一次partsort,知道了left和right后,将他们再pop掉。void QuickSortNonR(int* a, int begin, int end) { ST st; STInit(&st); STPush(&st, end); STPush(&st, begin); while (!STEmpty(&st)) { int left = STTop(&st); STPop(&st); int right = STTop(&st); STPop(&st); int keyi = PartSort1(a, left, right); if (keyi + 1 < right) { STPush(&st, right); STPush(&st, keyi + 1); } if (left < keyi - 1) { STPush(&st, keyi - 1); STPush(&st, left); } } STDestroy(&st); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
快排讲到这里就结束啦,如果你有耐心看完的话你一定会对快排的掌握有所提升哒。
加油! -
相关阅读:
Vue3 defineProps使用
如何从 SD 卡恢复已删除的文件 –最新方法
Windows系统设置mysql主从模式
C语言描述数据结构 —— 带头双向循环链表
ATFX汇市:澳大利亚一季度CPI年率大降,澳元升值态势延续
Python使用大连理工情感本体提取文本的情感倾向
Rust之Sea-orm快速入门指南
IP-guard Webserver view 远程命令执行漏洞【2023最新漏洞】
不同的二叉搜索树
实例详解 Java 死锁与破解死锁
- 原文地址:https://blog.csdn.net/qq_75270497/article/details/133757381
