-
ChatGLM:向量化构建本地知识库原理
一、概念
1.向量:是有大小和方向的量,可以使用带箭头的线段表示,箭头指向即为向量的方向,线段的长度表示向量的大小。
2.向量化:将语言模型的数据转化为向量。这通常通过嵌入模型(embedding models)完成,比如word2vec,GloVe,或者BERT等,这些模型可以将文本数据转化为向量形式。
3.向量数据库(Vector Database):也叫矢量数据库,主要用来存储和处理向量数据。
4.与sql查询的区别:使用向量数据库根据语义或上下文含义查找最相似或相关的数据,而不是使用基于精确匹配或预定义标准查询数据库的传统方法。
5.向量数据库的主要特点:高效存储与检索。
二、文本向量储存
主流的文本向量储存技术有
1.词袋模型(Bag-of-Words):词袋模型将文本表示为一个向量,其中向量的每个维度表示一个单词,而向量的值表示该单词在文本中的出现频率或权重。可以使用词频(Term Frequency)或词频-逆文档频率(TF-IDF)等方法来计算向量的值。
2.Word2Vec:Word2Vec 是一种基于神经网络的词嵌入模型,Word2vec主要是基于两个核心思想:连续词袋模型和skip-gram模型。
它将单词映射为连续向量空间中的向量。通过训练神经网络,Word2Vec 可以学习到单词之间的语义和语法关系,从而产生具有语义相关性的向量表示。
3.GloVe:GloVe(Global Vectors for Word Representation)也是一种词嵌入模型,它通过统计单词在上下文中的共现关系来生成向量表示。GloVe 模型将全局的词语共现统计信息与局部的上下文窗口统计信息相结合,产生更加全面和准确的向量表示。
4.BERT:BERT(Bidirectional Encoder Representations from Transformers)是一种基于 Transformer 模型的预训练语言模型。通过训练大规模的语料库,BERT 能够生成上下文敏感的单词嵌入向量,捕捉到单词的语义和句子之间的关系。
5.Doc2Vec:Doc2Vec 是一种将整个文档(而不仅仅是单词)嵌入为向量的技术。它类似于 Word2Vec,但将文档作为一个整体进行嵌入,从而生成文档级别的向量表示。
而今天我要介绍的的项目使用的是以word2vec为基础生成的embedding模型,适合于通过较少的资源生成精度较高的问答结果。
三、word2vec模型
Text2vec模型使用词嵌入(Word Embedding)技术来实现文本向量化。词嵌入是一种将单词映射到连续向量空间的技术,能够捕捉到单词之间的语义和语法关系。通过将文本中的每个单词映射为词嵌入向量,text2vec模型可以将整个文本表示为一个向量序列,从而保留了文本的语义信息。
在文本向量化过程中,text2vec模型可以使用不同的词嵌入算法,如Word2Vec、GloVe、BERT等。这些算法基于不同的原理和训练方法,但都旨在将单词表示为具有语义相关性的向量。目前使用广泛的还是word2vec.
通过使用word2vec模型,我们可以将文本数据转换为数值向量,以便应用于各种机器学习和自然语言处理任务,例如文本分类、情感分析、机器翻译等。文本向量化的过程使得计算机能够更好地理解和处理文本数据,从而提高了文本相关任务的性能和效果。但是word2vec也有他自身的局限性,比如比较适合处理短文本,面对长文本容易出现问题数量判断错误,问题的题干理解不清晰等问题。
word2vec模型的优缺点:
1.优点:会考虑上下文,速度快,通用性强。
2.缺点:由于词和向量是一对一的关系,所以无法理解多义词。
(1)概念
Word2Vec是用来生成词向量的工具,而词向量与语言模型有着密切的关系。Word2Vec旨在从巨大的词汇量中高效学习词向量,并预测与输入词汇关联度大的其他词汇。
Word2Vec是轻量级的神经网络,其模型仅仅包括输入层、隐藏层和输出层。word2vec为什么不用现成的DNN模型,要继续优化出新方法呢?最主要的问题:DNN模型的这个处理过程非常耗时。word2vec也使用了CBOW与Skip-Gram来训练模型与得到词向量,但是并没有使用传统的DNN模型,而是对其进行了改进。最先优化使用的数据结构是用霍夫曼树来代替隐藏层和输出层的神经元。
word2vec工具主要包含两个模型:跳字模型(skip-gram)和连续词袋模型(continuous bag of words,简称CBOW)
(2)CBOW模型
连续词袋模型(Continuous Bag-of-Word Model, CBOW)是一个三层神经网络,输入已知上下文,输出对下个单词的预测。CBOW模型的第一层是输入层, 输入已知上下文的词向量;中间一层称为线性隐含层, 它将所有输入的词向量累加; 第三层是一棵哈夫曼树, 树的的叶节点与语料库中的单词一一对应, 而树的每个非叶节点是一个二分类器(一般是softmax感知机等), 树的每个非叶节点都直接与隐含层相连。将上下文的词向量输入CBOW模型, 由隐含层累加得到中间向量,将中间向量输入哈夫曼树的根节点, 根节点会将其分到左子树或右子树。每个非叶节点都会对中间向量进行分类, 直到达到某个叶节点,该叶节点对应的单词就是对下个单词的预测。
训练过程:
首先根据预料库建立词汇表, 词汇表中所有单词拥有一个随机的词向量。我们从语料库选择一段文本进行训练;
将单词W的上下文的词向量输入CBOW, 由隐含层累加, 在第三层的哈夫曼树中沿着某个特定的路径到达某个叶节点, 从给出对单词W的预测。
训练过程中我们已经知道了单词W, 根据W的哈夫曼编码我们可以确定从根节点到叶节点的正确路径, 也确定了路径上所有分类器应该作出的预测.
我们采用梯度下降法调整输入的词向量, 使得实际路径向正确路径靠拢。在训练结束后我们可以从词汇表中得到每个单词对应的词向量
(3) Skip-gram
Skip-gram模型同样是一个三层神经网络,skip-gram模型的结构与CBOW模型正好相反,skip-gram模型输入某个单词,输出对它上下文词向量的预测。
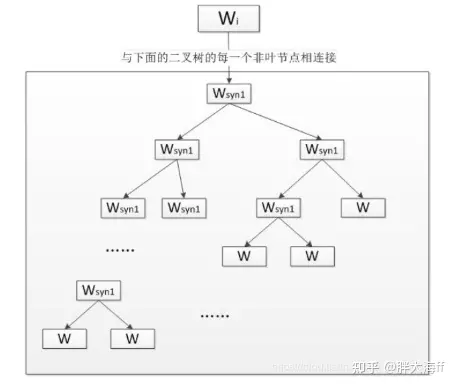
Skip-gram的核心同样是一个哈夫曼树, 每一个单词从树根开始到达叶节点,可以预测出它上下文中的一个单词。对每个单词进行N-1次迭代,得到对它上下文中所有单词的预测, 根据训练数据调整词向量得到足够精确的结果。
-
相关阅读:
java数据结构与算法刷题-----LeetCode26:删除有序数组中的重复项
交叉导轨这样使用,能省不少事!
浮点数在内存中的存储
Opencascade常用函数 更新中...
Vue3表单页面利用keep-alive缓存数据的一种思路
【微服务】五. Nacos服务注册
Web前端大作业—电影网页介绍8页(html+css+javascript) 带登录注册表单
Launch SkyWalking
VSCode配置用户代码段以及常用快捷键汇总
IOS开发学习日记(十七)
- 原文地址:https://blog.csdn.net/qq_34717531/article/details/133680936