-
记一次Redis Cluster Pipeline导致的死锁问题
作者:vivo 互联网服务器团队- Li Gang
本文介绍了一次排查Dubbo线程池耗尽问题的过程。通过查看Dubbo线程状态、分析Jedis连接池获取连接的源码、排查死锁条件等方面,最终确认是因为使用了cluster pipeline模式且没有设置超时时间导致死锁问题。
一、背景介绍
Redis Pipeline是一种高效的命令批量处理机制,可以在Redis中大幅度降低网络延迟,提高读写能力。Redis Cluster Pipeline是基于Redis Cluster的pipeline,通过将多个操作打包成一组操作,一次性发送到Redis Cluster中的多个节点,减少了通信延迟,提高了整个系统的读写吞吐量和性能,适用于需要高效处理Redis Cluster命令的场景。
本次使用到pipeline的场景是批量从Redis Cluster批量查询预约游戏信息,项目内使用的Redis Cluster Pipeline的流程如下,其中的JedisClusterPipeline是我们内部使用的工具类,提供Redis Cluster模式下的pipeline能力:
JedisClusterPipeline使用:
- JedisClusterPipline jedisClusterPipline = redisService.clusterPipelined();
- List
- try {
- for (String key : keys) {
- jedisClusterPipline.hmget(key, VALUE1, VALUE2);
- }
- // 获取结果
- response = jedisClusterPipline.syncAndReturnAll();
- } finally {
- jedisClusterPipline.close();
- }
二、故障现场记录
某天,收到了Dubbo线程池耗尽的告警。查看日志发现只有一台机器有问题,并且一直没恢复,已完成任务数也一直没有增加。
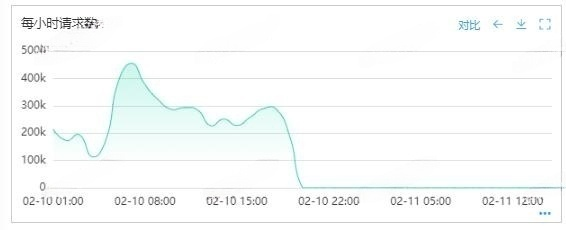
查看请求数监控,发现请求数归零,很明显机器已经挂了。
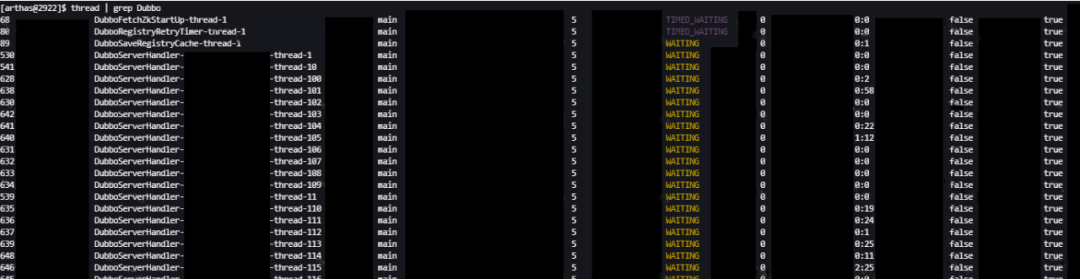
使用arthas查看Dubbo线程,发现400个线程全部处于waiting状态。
三、故障过程分析
Dubbo线程处于waiting状态这一点没有问题,Dubbo线程等待任务的时候也是waiting状态,但是查看完整调用栈发现有问题,下面两张图里的第一张是问题机器的栈,第二张是正常机器的栈,显然问题机器的这个线程在等待Redis连接池里有可用连接。

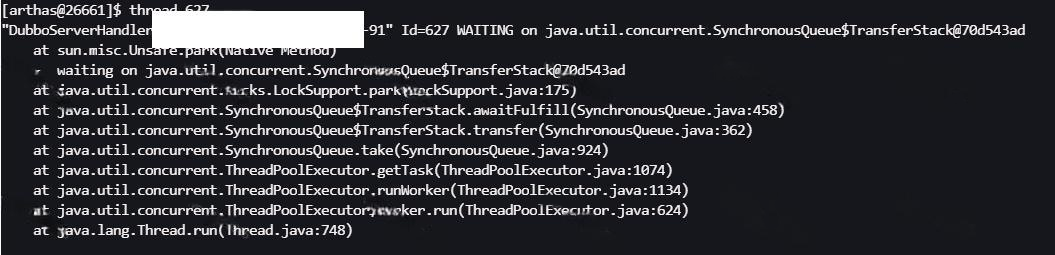
使用jstack导出线程快照后发现问题机器所有的Dubbo线程都在等待Redis连接池里有可用连接。
调查到这里,能发现两个问题。
-
线程一直等待连接而没有被中断。
-
线程获取不到连接。
3.1 线程一直等待连接而没有被中断原因分析
Jedis获取连接的逻辑在org.apache.commons.pool2.impl.GenericObjectPool#borrowObject(long)方法下。
- public T borrowObject(long borrowMaxWaitMillis) throws Exception {
- ...
- PooledObject
p = null; - // 获取blockWhenExhausted配置项,该配置默认值为true
- boolean blockWhenExhausted = getBlockWhenExhausted();
- boolean create;
- long waitTime = System.currentTimeMillis();
- while (p == null) {
- create = false;
- if (blockWhenExhausted) {
- // 从队列获取空闲的对象,该方法不会阻塞,没有空闲对象会返回null
- p = idleObjects.pollFirst();
- // 没有空闲对象则创建
- if (p == null) {
- p = create();
- if (p != null) {
- create = true;
- }
- }
- if (p == null) {
- // borrowMaxWaitMillis默认值为-1
- if (borrowMaxWaitMillis < 0) {
- // 线程栈快照里所有的dubbo线程都卡在这里,这是个阻塞方法,如果队列里没有新的连接会一直等待下去
- p = idleObjects.takeFirst();
- } else {
- // 等待borrowMaxWaitMillis配置的时间还没有拿到连接的话就返回null
- p = idleObjects.pollFirst(borrowMaxWaitMillis,
- TimeUnit.MILLISECONDS);
- }
- }
- if (p == null) {
- throw new NoSuchElementException(
- "Timeout waiting for idle object");
- }
- if (!p.allocate()) {
- p = null;
- }
- }
- ...
- }
- updateStatsBorrow(p, System.currentTimeMillis() - waitTime);
- return p.getObject();
- }
由于业务代码没有设置borrowMaxWaitMillis,导致线程一直在等待可用连接 ,该值可以通过配置jedis pool的maxWaitMillis属性来设置。
到这里已经找到线程一直等待的原因,但线程获取不到连接的原因还需要继续分析。
3.2 线程获取不到连接原因分析
获取不到连接无非两种情况:
-
连不上Redis,无法创建连接
-
连接池里的所有连接都被占用了,无法获取到连接
猜想一:是不是连不上Redis?
询问运维得知发生问题的时间点确实有一波网络抖动,但是很快就恢复了,排查时问题机器是能正常连上Redis的。那有没有可能是创建Redis连接的流程写的有问题,无法从网络抖动中恢复导致线程卡死?这一点要从源码中寻找答案。
创建连接:
- private PooledObject
create() throws Exception { - int localMaxTotal = getMaxTotal();
- long newCreateCount = createCount.incrementAndGet();
- if (localMaxTotal > -1 && newCreateCount > localMaxTotal ||
- newCreateCount > Integer.MAX_VALUE) {
- createCount.decrementAndGet();
- return null;
- }
- final PooledObject
p; - try {
- // 创建redis连接,如果发生超时会抛出异常
- // 默认的connectionTimeout和soTimeout都是2秒
- p = factory.makeObject();
- } catch (Exception e) {
- createCount.decrementAndGet();
- // 这里会把异常继续往上抛出
- throw e;
- }
- AbandonedConfig ac = this.abandonedConfig;
- if (ac != null && ac.getLogAbandoned()) {
- p.setLogAbandoned(true);
- }
- createdCount.incrementAndGet();
- allObjects.put(new IdentityWrapper
(p.getObject()), p); - return p;
- }
可以看到,连接Redis超时时会抛出异常,调用create()函数的borrowObject()也不会捕获这个异常,这个异常最终会在业务层被捕获,所以连不上Redis的话是不会一直等待下去的,网络恢复后再次调用create()方法就能重新创建连接。
综上所诉,第一种情况可以排除,继续分析情况2,连接被占用了没问题,但是一直不释放就有问题。
猜想二:是不是业务代码没有归还Redis连接?
连接没有释放,最先想到的是业务代码里可能有地方漏写了归还Redis连接的代码,pipeline模式下需要在finally块中手动调用JedisClusterPipeline#close()方法将连接归还给连接池,而普通模式下不需要手动释放(参考redis.clients.jedis.JedisClusterCommand#runWithRetries,每次执行完命令后都会自动释放),在业务代码里全局搜索所有使用到了cluster pipeline的代码,均手动调用了JedisClusterPipeline#close()方法,所以不是业务代码的问题。
猜想三:是不是Jedis存在连接泄露的问题?
既然业务代码没问题,那有没有可能是归还连接的代码有问题,存在连接泄露?2.10.0版本的Jedis确实可能发生连接泄露,具体可以看这个issue:https://github.com/redis/jedis/issues/1920,不过我们项目内使用的是2.9.0版本,所以排除连接泄露的情况。
猜想四:是不是发生了死锁?
排除以上可能性后,能想到原因的只剩死锁,思考后发现在没有设置超时时间的情况下,使用pipeline确实有概率发生死锁,这个死锁发生在从连接池(LinkedBlockingDeque)获取连接的时候。
先看下cluster pipeline模式下的Redis和普通的Redis有什么区别。Jedis为每个Redis实例都维护了一个连接池,cluster pipeline模式下,先使用查询用的key计算出其所在的Redis实例列表,再从这些实例对应的连接池里获取到连接,使用完后统一释放。而普通模式下一次只会获取一个连接池的连接,用完后立刻释放。这意味着cluster pipeline模式在获取连接时是符合死锁的“占有并等待”条件的,而普通模式不符合这个条件。
JedisClusterPipeline使用:
- JedisClusterPipline jedisClusterPipline = redisService.clusterPipelined();
- List
- try {
- for (String key : keys) {
- // 申请连接,内部会先调用JedisClusterPipeline.getClient(String key)方法获取连接
- jedisClusterPipline.hmget(key, VALUE1, VALUE2);
- // 获取到了连接,缓存到poolToJedisMap
- }
- // 获取结果
- response = jedisClusterPipline.syncAndReturnAll();
- } finally {
- // 归还所有连接
- jedisClusterPipline.close();
- }
JedisClusterPipeline部分源码:
- public class JedisClusterPipline extends PipelineBase implements Closeable {
- private static final Logger log = LoggerFactory.getLogger(JedisClusterPipline.class);
- // 用于记录redis命令的执行顺序
- private final Queue
orderedClients = new LinkedList<>(); - // redis连接缓存
- private final Map
- private final JedisSlotBasedConnectionHandler connectionHandler;
- private final JedisClusterInfoCache clusterInfoCache;
- public JedisClusterPipline(JedisSlotBasedConnectionHandler connectionHandler, JedisClusterInfoCache clusterInfoCache) {
- this.connectionHandler = connectionHandler;
- this.clusterInfoCache = clusterInfoCache;
- }
- @Override
- protected Client getClient(String key) {
- return getClient(SafeEncoder.encode(key));
- }
- @Override
- protected Client getClient(byte[] key) {
- Client client;
- // 计算key所在的slot
- int slot = JedisClusterCRC16.getSlot(key);
- // 获取solt对应的连接池
- JedisPool pool = clusterInfoCache.getSlotPool(slot);
- // 从缓存获取连接
- Jedis borrowedJedis = poolToJedisMap.get(pool);
- // 缓存中没有连接则从连接池获取并缓存
- if (null == borrowedJedis) {
- borrowedJedis = pool.getResource();
- poolToJedisMap.put(pool, borrowedJedis);
- }
- client = borrowedJedis.getClient();
- orderedClients.add(client);
- return client;
- }
- @Override
- public void close() {
- for (Jedis jedis : poolToJedisMap.values()) {
- // 清除连接内的残留数据,防止连接归还时有数据漏读的现象
- try {
- jedis.getClient().getAll();
- } catch (Throwable throwable) {
- log.warn("关闭jedis时遍历异常,遍历的目的是:清除连接内的残留数据,防止连接归还时有数据漏读的现象");
- }
- try {
- jedis.close();
- } catch (Throwable throwable) {
- log.warn("关闭jedis异常");
- }
- }
- // 归还连接
- clean();
- orderedClients.clear();
- poolToJedisMap.clear();
- }
- /**
- * go through all the responses and generate the right response type (warning :
- * usually it is a waste of time).
- *
- * @return A list of all the responses in the order
- */
- public List
- List
- List
throwableList = new ArrayList<>(); - for (Client client : orderedClients) {
- try {
- Response response = generateResponse(client.getOne());
- if(response == null){
- continue;
- }
- formatted.add(response.get());
- } catch (Throwable e) {
- throwableList.add(e);
- }
- }
- slotCacheRefreshed(throwableList);
- return formatted;
- }
- }

举个例子:
假设有一个集群有两台Redis主节点(集群模式下最小的主节点数量是3,这里只是为了举例),记为节点1/2,有个java程序有4个Dubbo线程,记为线程1/2/3/4,每个Redis实例都有一个大小为2的连接池。
线程1和线程2,先获取Redis1的连接再获取Redis2的连接。线程3和线程4,先获取Redis2的连接再获取Redis1的连接,假设这四个线程在获取到连接第一个连接后都等待了一会,在获取第二个连接的时候就会发生死锁(等待时间越长,触发的概率越大)。
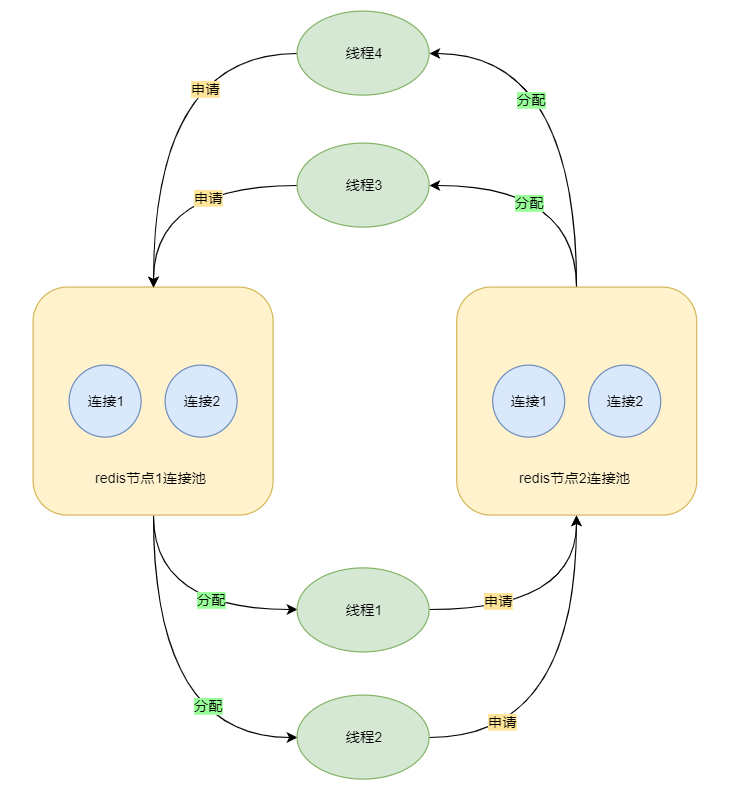
所以pipeline是可能导致死锁的,这个死锁的条件很容易破坏,等待连接的时候设置超时时间即可。还可以增大下连接池的大小,资源够的话也不会发生死锁。
四、死锁证明
以上只是猜想,为了证明确实发生了死锁,需要以下条件:
-
线程当前获取到了哪些连接池的连接
-
线程当前在等待哪些连接池的连接
-
每个连接池还剩多少连接
已知问题机器的Dubbo线程池大小为400,Redis集群主节点数量为12,Jedis配置的连接池大小为20。
4.1 步骤一:获取线程在等待哪个连接池有空闲连接
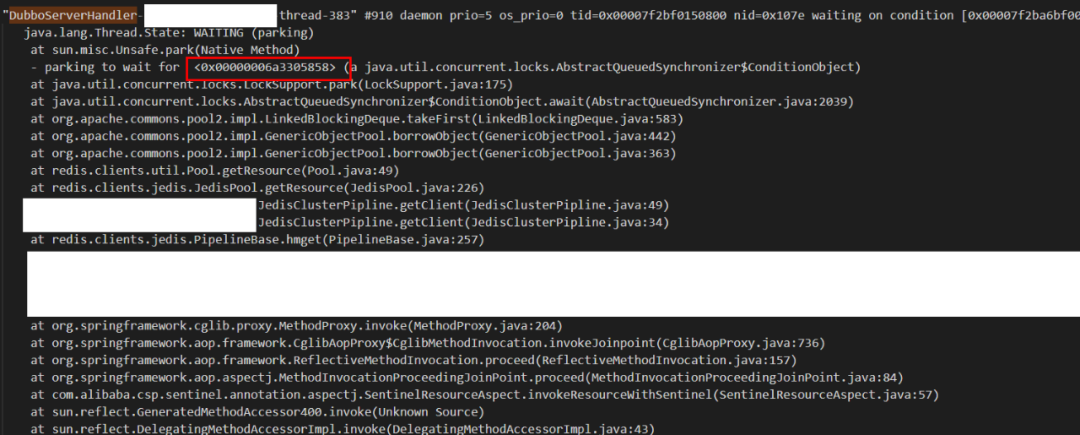
第一步:先通过jstack和jmap分别导出栈和堆
第二步:通过分析栈可以知道线程在等待的锁的地址,可以看到Dubbo线程383在等待0x6a3305858这个锁对象,这个锁属于某个连接池,需要找到具体是哪个连接池。
第三步:使用mat(Eclipse Memory Analyzer Tool)工具分析堆,通过锁的地址找到对应的连接池。
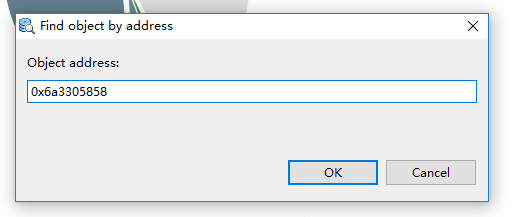
使用mat的with incoming references功能顺着引用一层层的往上找。

引用关系:ConditionObject->LinkedBlockingDeque

引用关系:LinkedBlockingDeque->GenericObjectPool

引用关系:GenericObjectPool->JedisPool。这里的ox6a578ddc8就是这个锁所属的连接池地址。
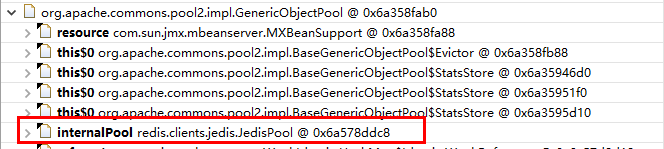
这样我们就能知道Dubbo线程383当前在等待0x6a578ddc8这个连接池的连接。
通过这一套流程,我们可以知道每个Dubbo线程分别在等待哪些连接池有可用连接。
4.2 步骤二:获取线程当前持有了哪些连接池的连接
第一步:使用mat在堆中查找所有JedisClusterPipeline类(正好400个,每个Dubbo线程都各有一个),然后查看里面的poolToJedisMap,其中保存了当前JedisClusterPipeline已经持有的连接和其所属的连接池。
下图中,我们可以看到JedisClusterPipeline(0x6ac40c088)对象当前的poolToJedisMap里有三个Node对象(0x6ac40dd40, 0x6ac40dd60, 0x6ac40dd80),代表其持有三个连接池的连接,可以从Node对象中找到JedisPool的地址。
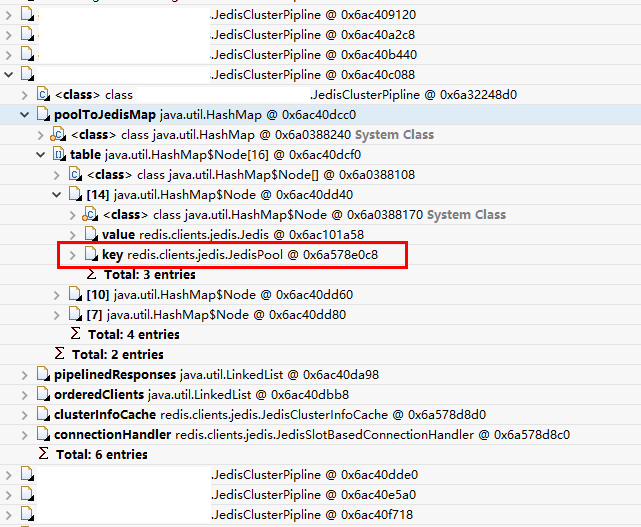
第二步:第一步拿到JedisClusterPipeline持有哪个连接池的连接后,再查找持有此JedisClusterPipeline的Dubbo线程,这样就能得到Dubbo线程当前持有哪些连接池的连接。

4.3 死锁分析
通过流程一可以发现虽然Redis主节点有12个,但是所有的Dubbo线程都只在等待以下5个节点对应的连接池之一:
-
0x6a578e0c8
-
0x6a578e048
-
0x6a578ddc8
-
0x6a578e538
-
0x6a578e838
通过流程二我们可以得知这5个连接池的连接当前被哪些线程占用:
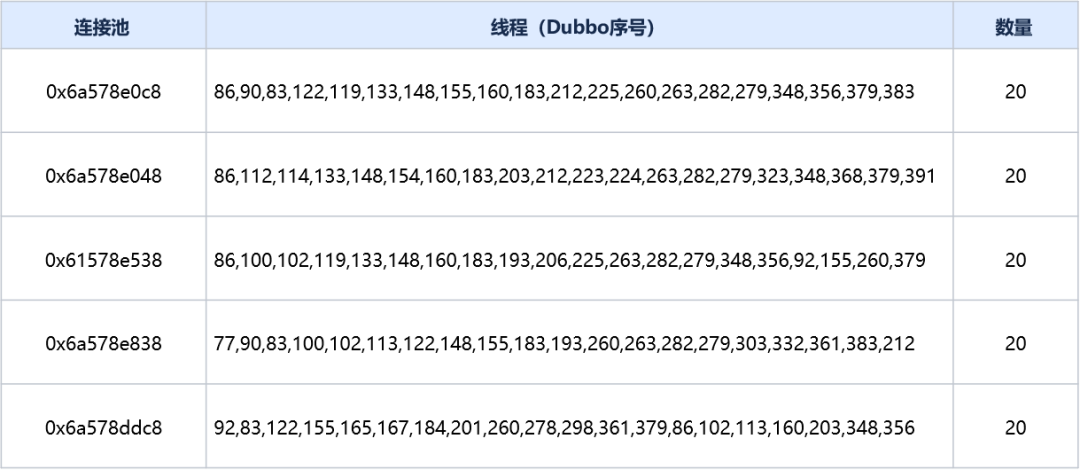
已知每个连接池的大小都配置为了20,这5个连接池的所有连接已经被100个Dubbo线程占用完了,而所有的400个Dubbo线程又都在等待这5个连接池的连接,并且其等待的连接当前没被自己占用,通过这些条件,我们可以确定发生了死锁。
五、总结
这篇文章主要展现了一次系统故障的分析过程。在排查过程中,作者使用jmap和jstack保存故障现场,使用arthas分析故障现场,再通过阅读和分析源码,从多个可能的角度一步步的推演故障原因,推测是死锁引起的故障。在验证死锁问题时,作者使用mat按照一定的步骤来寻找线程在等待哪个连接池的连接和持有哪些连接池的连接,再结合死锁检测算法最终确认故障机器发生了死锁。
排查线上问题并非易事,不仅要对业务代码有足够的了解,还要对相关技术知识有系统性的了解,推测出可能导致问题的原因后,再熟练运用好排查工具,最终确认问题原因。
-
相关阅读:
Python大语言模型实战-利用MetaGPT框架自动开发一个游戏软件(附完整教程)
JDBC整合C3P0,DBCP,DRUID数据库连接池
同事问我飞速代码背后的秘密,我望着他笑着拿出了MybatisPlus~
单场GMV翻了100倍,冷门品牌崛起背后的“通用法则”是什么?
身份证读卡器Qt语言实现Linux系统开发集成
Spring MVC 请求处理过程。你这样回答保证通过面试!
模拟滤波器和经典的低通滤波器
SpringCloud整合Nacos
samba服务器讲解
LeetCode-190. 颠倒二进制位(java)
- 原文地址:https://blog.csdn.net/vivo_tech/article/details/133786376
