-
生产级Stable Diffusion AI服务部署指南【BentoML】
在本文中,我们将完成 BentoML 和 Diffusers 库之间的集成过程。 通过使用 Stable Diffusion 2.0 作为案例研究,你可以了解如何构建和部署生产就绪的 Stable Diffusion 服务。

推荐:用 NSDT编辑器 快速搭建可编程3D场景
Stable Diffusion 2.0 包含多项新功能,例如更高分辨率(例如 768x768 输出)、称为depth2img 的深度引导稳定扩散模型、内置 4 倍放大模型等等。 更重要的是,你将亲身了解如何利用这两个库的强大功能在生产环境中构建和部署健壮、可扩展且高效的扩散模型。
以下教程的详细代码和说明可以在 BentoML 的 Diffusers 示例项目下找到。
1、为什么选择Diffusers库
HuggingFace 的 Diffusers 库是一个强大的工具,用于访问和利用 Python 中的相关扩散模型。 该库注重易用性,配备了多个扩散管道,只需几行代码即可执行,让用户快速高效地上手。 模型的不同实现和版本可以轻松交换,因为 Diffusers 库试图统一常见扩散模型的接口。 我们甚至可以使用具有类似工作流程的音频生成模型(使用Diffusers)。 最后,Diffusers 社区提供随时可用的自定义管道,这将扩展标准稳定扩散管道的功能。
2、为什么选择 BentoML
将 Diffusers 与 BentoML 集成,使其成为现实部署中更有价值的工具。 借助 BentoML,用户可以轻松打包和提供扩散模型以供生产使用,确保可靠且高效的部署。 BentoML 配备了开箱即用的运营管理工具,例如监控和跟踪,并提供轻松部署到任何云平台的自由。
3、准备依赖
我们建议在配备 Nvidia GPU 且安装了 CUDA Toolkit 的计算机上运行 Stable Diffusion 服务。 我们首先制作一个虚拟环境并安装必要的依赖项。
python3 -m venv venv source venv/bin/activate pip install bentoml diffusers transformers accelerate- 1
- 2
- 3
要访问某些模型,你可能需要使用 Hugging Face 帐户登录。 可以登录你的帐户并获取用户访问令牌。 然后安装huggingface-hub并运行登录命令。
pip install -U huggingface_hub huggingface-cli login- 1
- 2
4、导入扩散模型
使用模型标识符将扩散模型导入 BentoML 模型存储非常简单。
import bentoml bentoml.diffusers.import_model( "sd2", "stabilityai/stable-diffusion-2", )- 1
- 2
- 3
- 4
- 5
- 6
上面的代码片段将从 HuggingFace Hub 下载 Stable Diffusion 2 模型(如果之前已经下载过该模型,则使用缓存的下载文件)并将其导入名为 sd2 的 BentoML 模型存储中。
如果磁盘上已经有经过微调的模型,你还可以提供路径而不是模型标识符。
import bentoml bentoml.diffusers.import_model( "sd2", "./local_stable_diffusion_2/", )- 1
- 2
- 3
- 4
- 5
- 6
可以导入Diffusers支持的任何扩散模型。 例如,以下代码将导入 Linaqruf/anything-v3.0 而不是 stableai/stable-diffusion-2。
import bentoml bentoml.diffusers.import_model( "anything-v3", "Linaqruf/anything-v3.0", )- 1
- 2
- 3
- 4
- 5
- 6
3、将扩散模型转变为 RESTful 服务
使用 Stable Diffusion 2.0 的 text2img 服务可以像下面这样实现,假设 sd2 是导入的 Stable Diffusion 2.0 模型的模型名称。
import torch from diffusers import StableDiffusionPipeline import bentoml from bentoml.io import Image, JSON, Multipart bento_model = bentoml.diffusers.get("sd2:latest") stable_diffusion_runner = bento_model.to_runner() svc = bentoml.Service("stable_diffusion_v2", runners=[stable_diffusion_runner]) @svc.api(input=JSON(), output=Image()) def txt2img(input_data): images, _ = stable_diffusion_runner.run(**input_data) return images[0]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
将代码保存为 service.py,然后我们就可以启动 BentoML 服务端点。
bentoml serve service:svc --production
具有接受 JSON 字典的 /txt2img 端点的 HTTP 服务器应位于端口 3000。在 Web 浏览器中转至 http://127.0.0.1:3000 以访问 Swagger UI: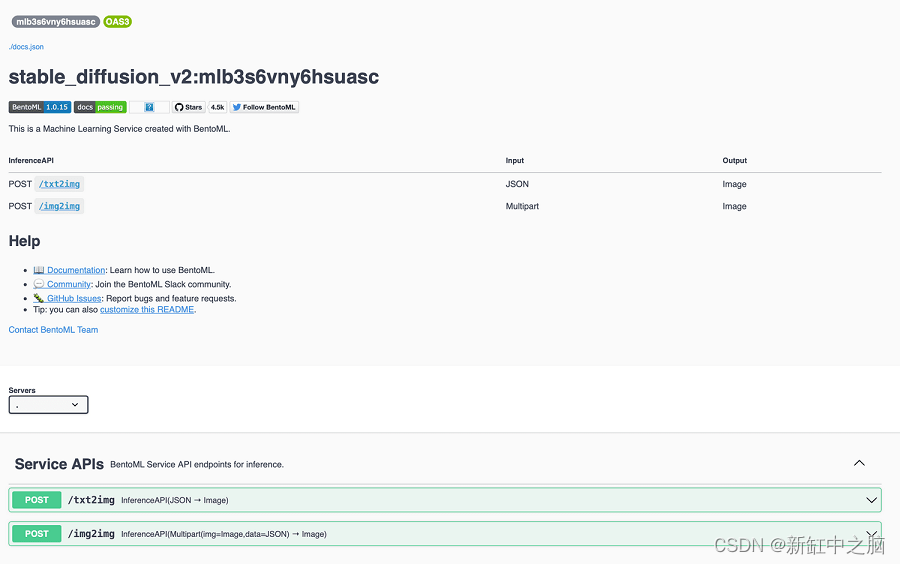
或者,你可以使用curl 测试文本到图像的生成,并将返回的图像写入output.jpg:
curl -X POST http://127.0.0.1:3000/txt2img -H 'Content-Type: application/json' -d "{\"prompt\":\"a black cat\"}" --output output.jpg- 1
你可以在 JSON 字典内添加更多文本参数来生成图像。 以下输入将生成 768x768 的图像:
curl -X POST http://127.0.0.1:3000/txt2img \ -H 'Content-Type: application/json' \ -d "{\"prompt\":\"a black cat\", \"height\":768, \"width\":768}" \ --output output.jpg- 1
- 2
- 3
- 4
如果先前已导入模型,则使用另一个扩散模型很简单,只需更改模型名称即可。 例如,可以通过将模型名称更改为 everything-v3 来创建 Anything v3.0 服务,而不是 sd2。
bento_model = bentoml.diffusers.get("anything-v3:latest") anything_v3_runner = bento_model.to_runner() svc = bentoml.Service("anything_v3", runners=[anything_v3_runner]) @svc.api(input=JSON(), output=Image()) def txt2img(input_data): images, _ = anything_v3_runner.run(**input_data) return images[0]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
你可以尝试Bentoml用于稳定扩散 2.0 服务的相同的curl命令,生成的结果将具有非常不同的风格。
Bentoml.diffusers 还支持扩散器的自定义管道。 如果你想要一种可以使用一个管道同时处理 txt2img 和 img2img 的服务(这可以节省 GPU 的 VRAM),那么这尤其方便。 官方 Diffusers 管道不支持此功能,但社区提供了一个名为“Stable Diffusion Mega”的即用管道,其中包含此功能。 要使用此管道,我们需要稍微不同地导入扩散模型。
import bentoml bentoml.diffusers.import_model( "sd2", "stabilityai/stable-diffusion-2", signatures={ "__call__": { "batchable": False }, "text2img": { "batchable": False }, "img2img": { "batchable": False }, "inpaint": { "batchable": False }, } )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这段代码将告诉 BentoML 除了
__call__之外,扩散模型还有其他方法(例如 text2img)。 重新导入模型后,我们可以拥有一个可以运行文本到图像生成和图像到图像生成的服务。import torch from diffusers import DiffusionPipeline import bentoml from bentoml.io import Image, JSON, Multipart bento_model = bentoml.diffusers.get("sd2:latest") stable_diffusion_runner = bento_model.with_options( pipeline_class=DiffusionPipeline, custom_pipeline="stable_diffusion_mega", ).to_runner() svc = bentoml.Service("stable_diffusion_v2", runners=[stable_diffusion_runner]) @svc.api(input=JSON(), output=Image()) def txt2img(input_data): images, _ = stable_diffusion_runner.text2img.run(**input_data) return images[0] img2img_input_spec = Multipart(img=Image(), data=JSON()) @svc.api(input=img2img_input_spec, output=Image()) def img2img(img, data): data["image"] = img images, _ = stable_diffusion_runner.img2img.run(**data)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
4、通过 Xformers 加速生成
xformers 是一个基于 PyTorch 的库,它托管灵活且优化良好的 Transformers 构建块。 通过 Diffusers,bentoml.diffusers 与 xformers 集成,以在可能的情况下加速扩散模型。 Bentoml.diffusers 服务将在启动时检测是否安装了 xformers,并使用它来自动加速生成过程。
pip install xformers triton- 1
重新运行前面步骤中的 Bentomlserve service:svc --Production,单个图像的生成时间应该比以前更快。 在我们的测试中,只需安装 xformers 即可将在单个 RTX 3060 上运行的生成效率从 7.6 it/s 加速到 9.0 it/s。该优化在 A100 等更强大的 GPU 上效果会更好。
5、结束语
Diffusers 库及其与 BentoML 的集成相结合,为在生产中部署扩散模型提供了强大且实用的解决方案,无论你是经验丰富还是刚刚起步。
-
相关阅读:
ES6新特性
多线程的相关知识
LeetCode315 周赛
聊天页面样式
循环登录提示“您为登录或者认证已过期,请重新登录”
javascript 数组方法 slice() 的使用说明
世界国旗/地图:世界各国国旗图标整理/与echarts世界地图配置对应
linux运行ant 报错 Unable to locate tools.jar【已解决】
程序员周末都干些什么?
Java基础-day08-再谈泛型
- 原文地址:https://blog.csdn.net/shebao3333/article/details/133787802
